On Fri, May 11, 2012 at 10:51:14PM +0800, Fengguang Wu wrote:
> > > > Look at the gray "bdi setpoint" lines. The
> > > > VM_COMPLETIONS_PERIOD_LEN=8s kernel is able to achieve roughly the
> > > > same stable bdi_setpoint as the vanilla kernel, while being able to
> > > > adapt to the balanced bdi_setpoint much more fast (actually now the
> > > > bdi_setpoint is immediately close to the balanced value when
> > > > balance_dirty_pages() starts throttling, while the vanilla kernel
> > > > takes about 20 seconds for bdi_setpoint to grow up).
> > > Which graph is from which kernel? All four graphs have the same name so
> > > I'm not sure...
> >
> > They are for test cases:
> >
> > 0.5s period
> > bay/JBOD-2HDD-thresh=1000M/xfs-1dd-1-3.4.0-rc2-prop+/balance_dirty_pages-pages+.png
> > 3s period
> > bay/JBOD-2HDD-thresh=1000M/xfs-1dd-1-3.4.0-rc2-prop3+/balance_dirty_pages-pages+.png
> > 8s period
> > bay/JBOD-2HDD-thresh=1000M/xfs-1dd-1-3.4.0-rc2-prop8+/balance_dirty_pages-pages+.png
> > vanilla
> > bay/JBOD-2HDD-thresh=1000M/xfs-1dd-1-3.3.0/balance_dirty_pages-pages+.png
> >
> > > The faster (almost immediate) initial adaptation to bdi's writeout fraction
> > > is mostly an effect of better normalization with my patches. Although it is
> > > pleasant, it happens just at the moment when there is a small number of
> > > periods with non-zero number of events. So more important for practice is
> > > in my opininion to compare transition of computed fractions when workload
> > > changes (i.e. we start writing to one bdi while writing to another bdi or
> > > so).
> >
> > OK. I'll test this scheme and report back.
> >
> > loop {
> > dd to disk 1 for 30s
> > dd to disk 2 for 30s
> > }
>
> Here are the new results. For simplicity I run the dd dirtiers
> continuously, and start another dd reader to knock down the write
> bandwidth from time to time:
>
> loop {
> dd from disk 1 for 30s
> dd from disk 2 for 30s
> }
>
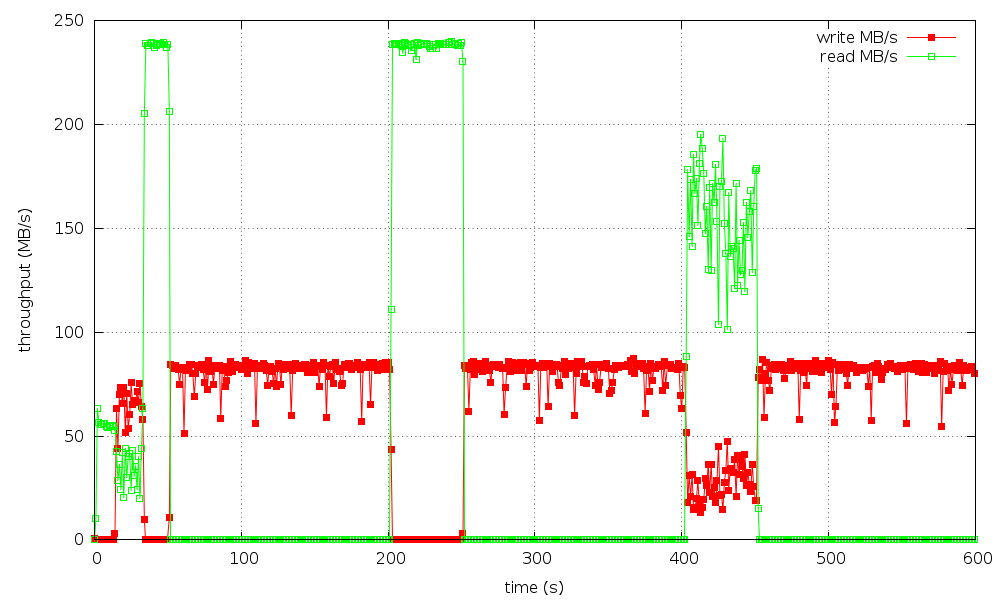
> The first attached iostat graph shows the resulting read/write
> bandwidth for one of the two disks.
>
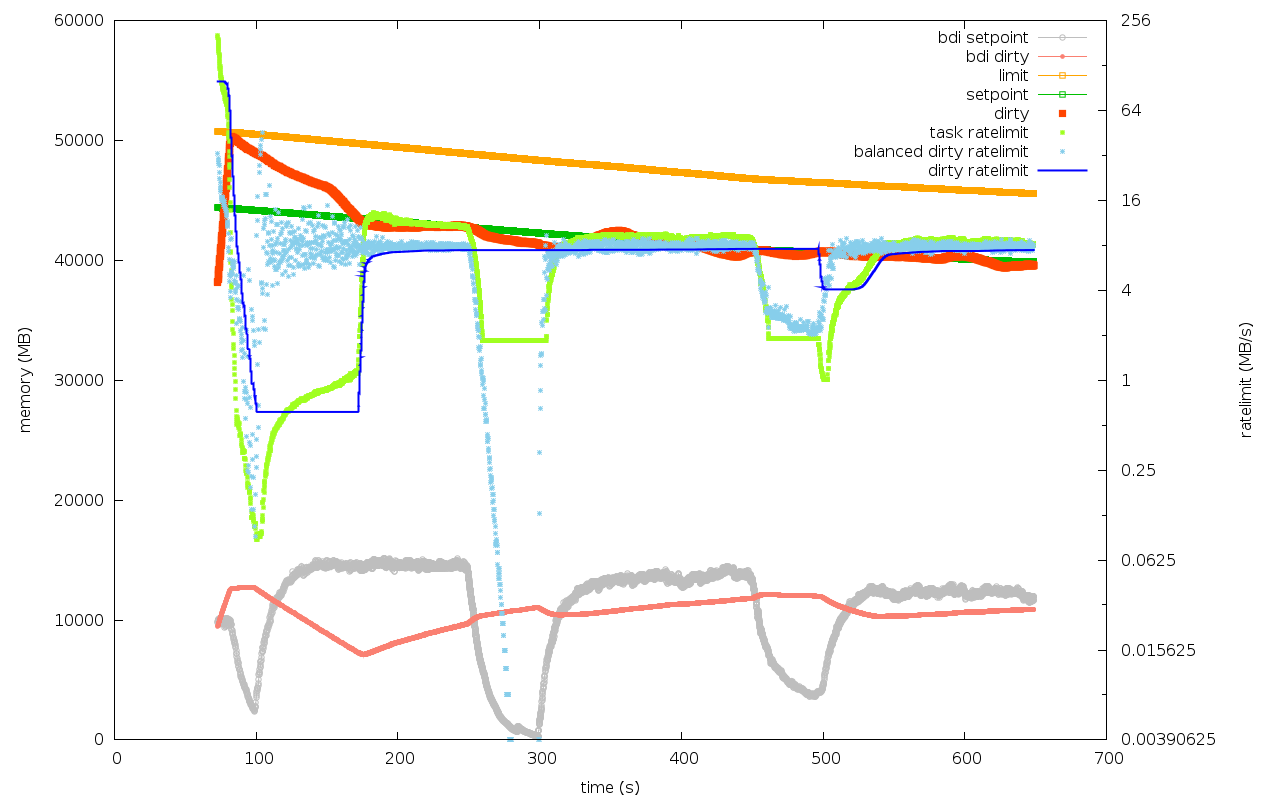
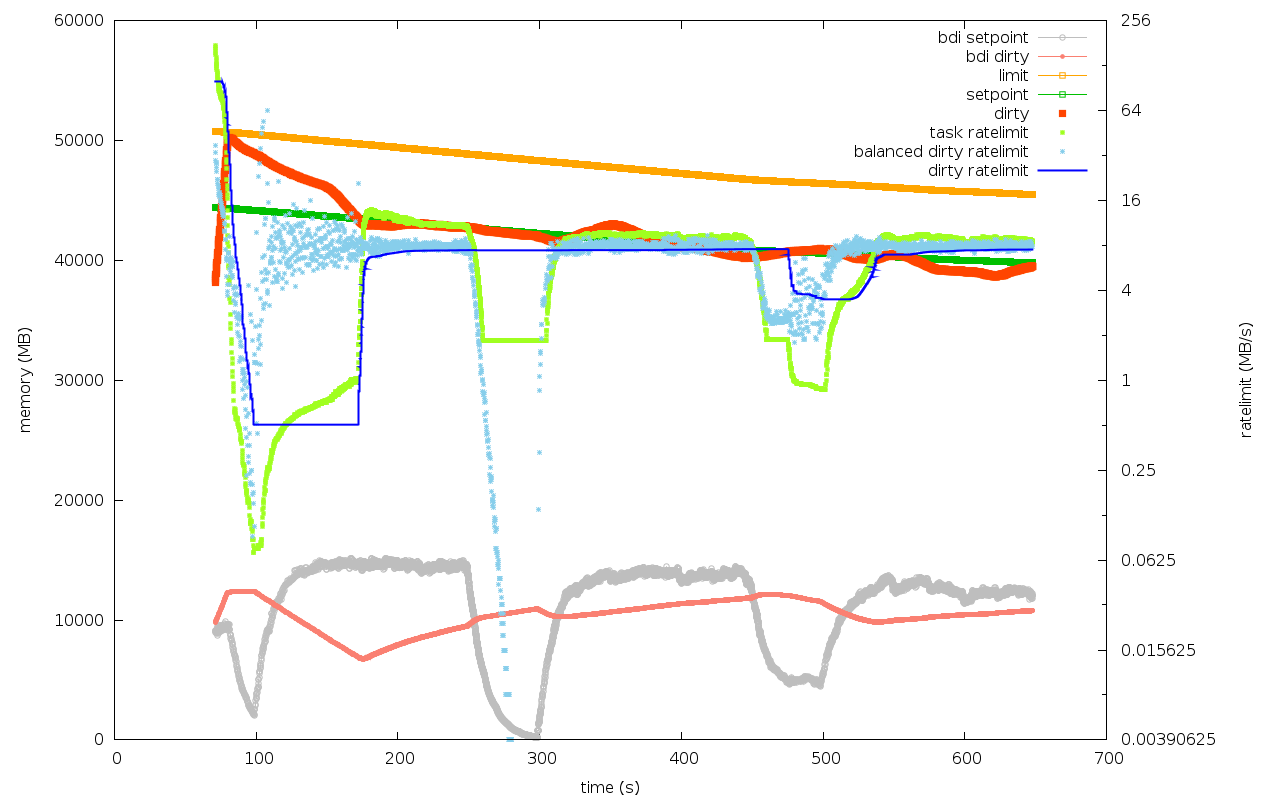
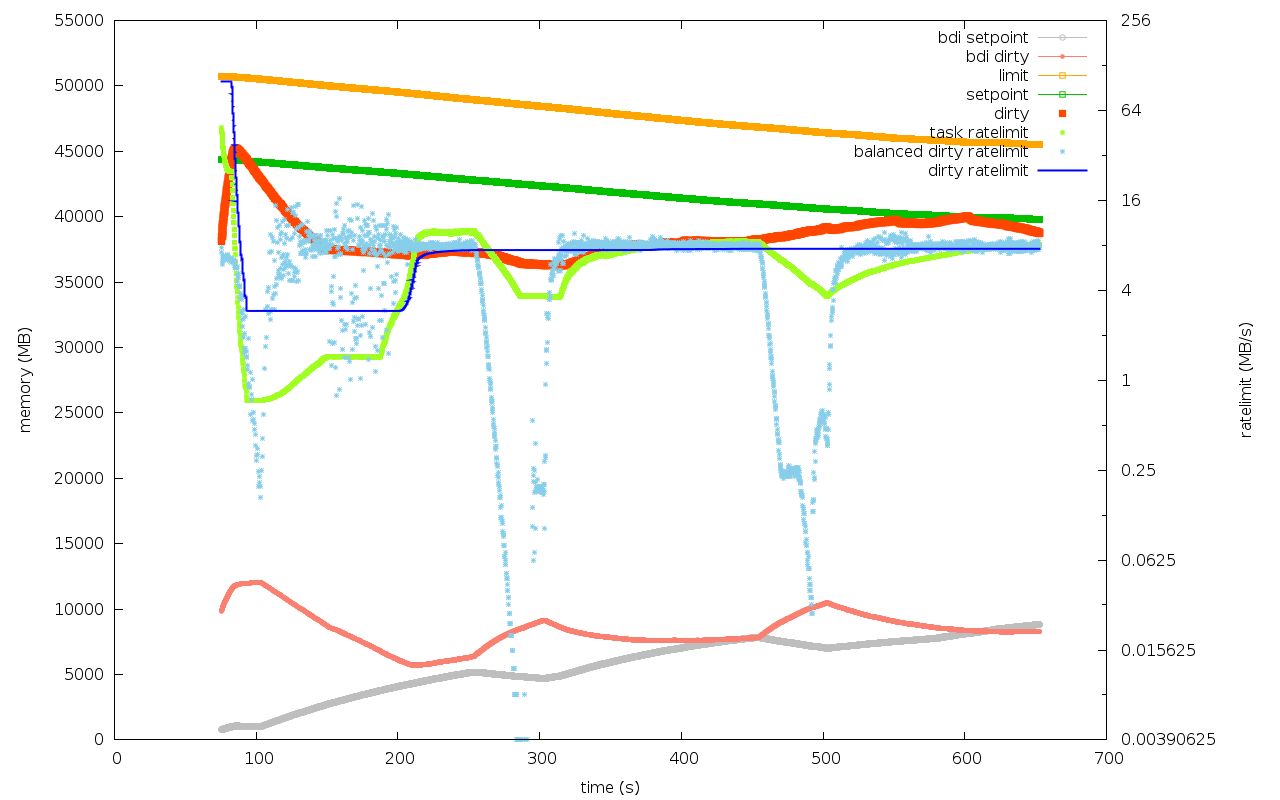
> The followed graphs are for
> - 3s period
> - 8s period
> - vanilla
> in order. The test case is (xfs-1dd, mem=2GB, 2 disks JBOD).
Here are more results for another test box with mem=256G running 4
SSDs. This time I run 8 dd readers to better disturb the writes.
The first 3 graphs are for cases:
lkp-nex04/alternant_read_8/xfs-10dd-2-3.4.0-rc5-prop3+
lkp-nex04/alternant_read_8/xfs-10dd-2-3.4.0-rc5-prop8+
lkp-nex04/alternant_read_8/xfs-10dd-2-3.3.0
The last graph shows how the write bandwidth is squeezed by reads over time:
lkp-nex04/alternant_read_8/xfs-10dd-2-3.4.0-rc5-prop8+/iostat-bw.png
The observations for this box are
- the 3s and 8s periods result in roughly the same adaption speed
- the patch makes a really *big* difference in systems with big
memory:bandwidth ratio. It's sweet! In comparison, the vanilla
kernel adapts to new write bandwidth so much slower.
Thanks,
Fengguang
Attachment:
balance_dirty_pages-pages.png
Description: PNG image
{kind=link}
Attachment:
balance_dirty_pages-pages.png
Description: PNG image
{kind=link}
Attachment:
balance_dirty_pages-pages.png
Description: PNG image
{kind=link}
Attachment:
iostat-bw.png
Description: PNG image
{kind=link}