Hi Vivek,
On Sun, Apr 01, 2012 at 04:56:47PM -0400, Vivek Goyal wrote:
> On Wed, Mar 28, 2012 at 08:13:08PM +0800, Fengguang Wu wrote:
> >
> > Here is one possible solution to "buffered write IO controller", based on Linux
> > v3.3
> >
> > git://git.kernel.org/pub/scm/linux/kernel/git/wfg/linux.git buffered-write-io-controller
> >
> > Features:
> > - support blkio.weight
> > - support blkio.throttle.buffered_write_bps
>
> Introducing separate knob for buffered write makes sense. It is different
> throttling done at block layer.
Yeah thanks.
> > Possibilities:
> > - it's trivial to support per-bdi .weight or .buffered_write_bps
> >
> > Pros:
> > 1) simple
> > 2) virtually no space/time overheads
> > 3) independent of the block layer and IO schedulers, hence
> > 3.1) supports all filesystems/storages, eg. NFS/pNFS, CIFS, sshfs, ...
> > 3.2) supports all IO schedulers. One may use noop for SSDs, inside virtual machines, over iSCSI, etc.
> >
> > Cons:
> > 1) don't try to smooth bursty IO submission in the flusher thread (*)
>
> Yes, this is a core limitation of throttling while writing to cache. I think
> once we had agreed that IO scheduler in general should be able to handle
> burstiness caused by WRITES. CFQ does it well. deadline not so much.
Yes I still remember that. It's better for the general kernel to
handle bursty writes just right, rather than to rely on IO controllers
for good interactive read performance.
> > 2) don't support IOPS based throttling
>
> If need be then you can still support it. Isn't it? Just that it will
> require more code in buffered write controller to keep track of number
> of operations per second and throttle task if IOPS limit is crossed. So
> it does not sound like a limitation of design but just limitation of
> current set of patches?
Sure. By adding some IOPS or "disk time" accounting, more IO metrics
can be supported.
> > 3) introduces semantic differences to blkio.weight, which will be
> > - working by "bandwidth" for buffered writes
> > - working by "device time" for direct IO
>
> I think blkio.weight can be thought of a system wide weight of a cgroup
> and more than one entity/subsystem should be able to make use of it and
> differentiate between IO in its own way. CFQ can decide to do proportional
> time division, and buffered write controller should be able to use the
> same weight and do write bandwidth differentiation. I think it is better
> than introducing another buffered write controller tunable for weight.
>
> Personally, I am not too worried about this point. We can document and
> explain it well.
Agreed. The throttling may work in *either* bps, IOPS or disk time
modes. In each mode blkio.weight is naturally tied to the
corresponding IO metrics.
> > (*) Maybe not a big concern, since the bursties are limited to 500ms: if one dd
> > is throttled to 50% disk bandwidth, the flusher thread will be waking up on
> > every 1 second, keep the disk busy for 500ms and then go idle for 500ms; if
> > throttled to 10% disk bandwidth, the flusher thread will wake up on every 5s,
> > keep busy for 500ms and stay idle for 4.5s.
> >
> > The test results included in the last patch look pretty good in despite of the
> > simple implementation.
>
> Can you give more details about test results. Did you test throttling or you
> tested write speed differentation based on weight too.
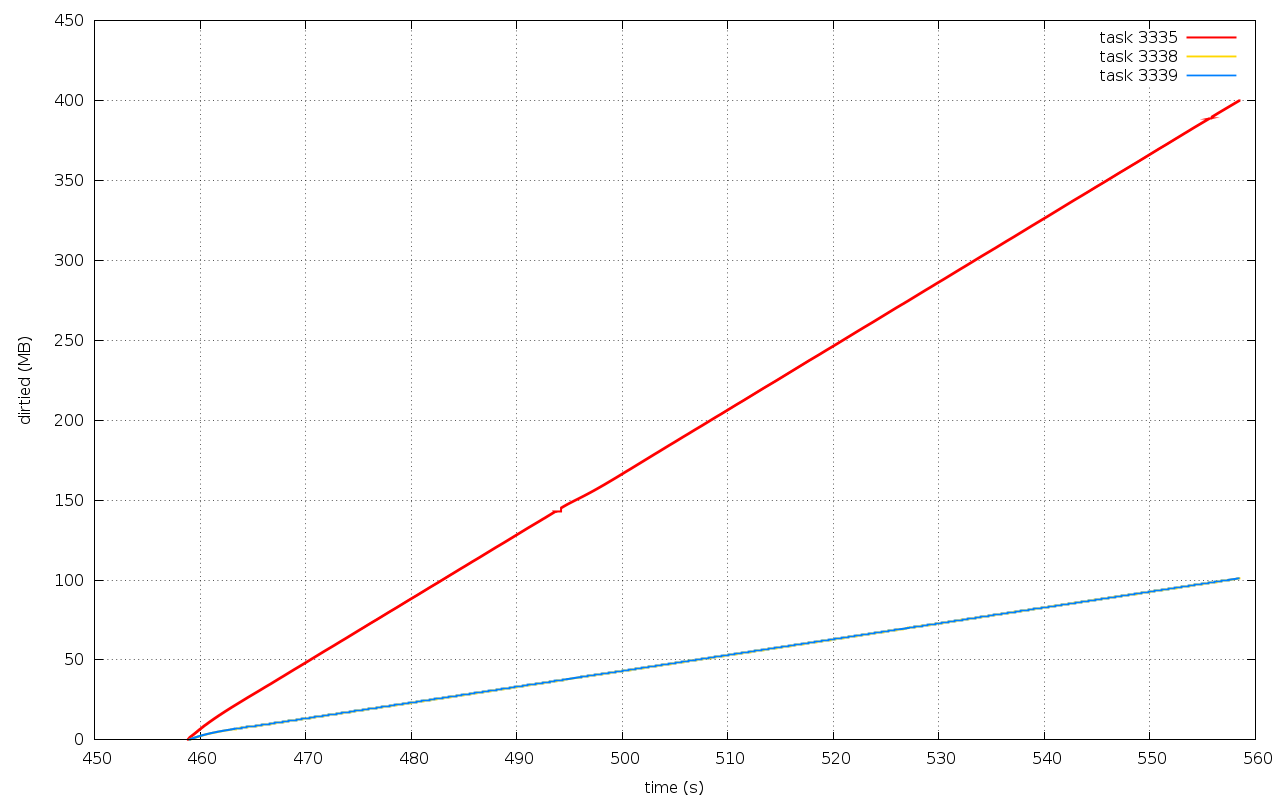
Patch 6/6 shows simple test results for bps based throttling.
Since then I've improved the patches to work in a more "contained" way
when blkio.throttle.buffered_write_bps is not set.
The old behavior is, if blkcg A contains 1 dd and blkcg B contains 10
dd tasks and they have equal weight, B will get 10 times bandwidth
than A.
With the below updated core bits, A and B will get equal share of
write bandwidth. The basic idea is to use
bdi->dirty_ratelimit * blkio.weight
as the throttling bps value if blkio.throttle.buffered_write_bps
is not specified by the user.
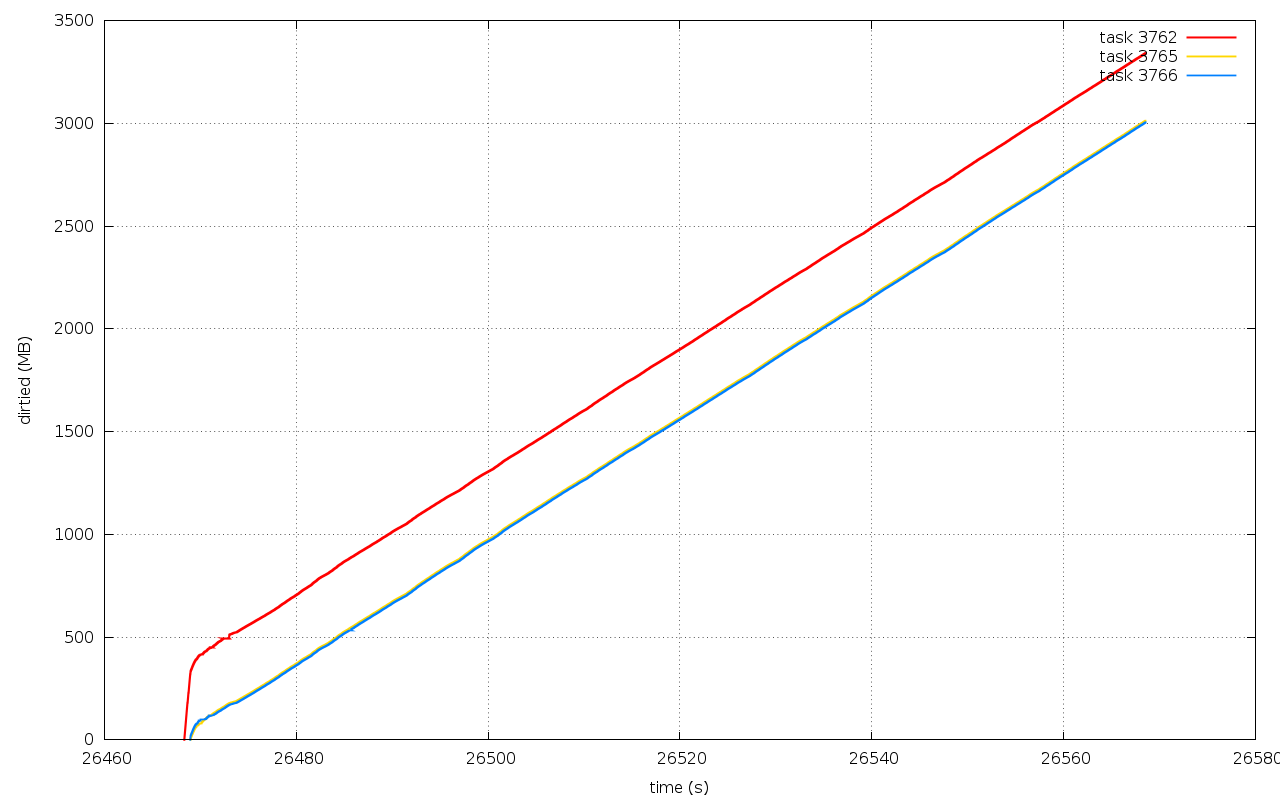
Test results are "pretty good looking" :-) The attached graphs
illustrates nice attributes of accuracy, fairness and smoothness
for the following tests.
- bps throttling (1 cp + 2 dd, throttled to 4MB/s and 2MB/s)
mount /dev/sda5 /fs
echo > /debug/tracing/trace
echo 1 > /debug/tracing/events/writeback/balance_dirty_pages/enable
echo 1 > /debug/tracing/events/writeback/bdi_dirty_ratelimit/enable
echo 1 > /debug/tracing/events/writeback/task_io/enable
cat /debug/tracing/trace_pipe | bzip2 > trace.bz2 &
rmdir /cgroup/cp
mkdir /cgroup/cp
echo $$ > /cgroup/cp/tasks
echo $((4<<20)) > /cgroup/cp/blkio.throttle.buffered_write_bps
cp /dev/zero /fs/zero &
echo $$ > /cgroup/tasks
if true; then
rmdir /cgroup/dd
mkdir /cgroup/dd
echo $$ > /cgroup/dd/tasks
echo $((2<<20)) > /cgroup/dd/blkio.throttle.buffered_write_bps
dd if=/dev/zero of=/fs/zero1 bs=64k &
dd if=/dev/zero of=/fs/zero2 bs=64k &
fi
echo $$ > /cgroup/tasks
sleep 100
killall dd
killall cp
killall cat
- bps proportional (1 cp + 2 dd, with equal weight)
mount /dev/sda5 /fs
echo > /debug/tracing/trace
echo 1 > /debug/tracing/events/writeback/balance_dirty_pages/enable
echo 1 > /debug/tracing/events/writeback/bdi_dirty_ratelimit/enable
echo 1 > /debug/tracing/events/writeback/task_io/enable
cat /debug/tracing/trace_pipe | bzip2 > trace.bz2 &
rmdir /cgroup/cp
mkdir /cgroup/cp
echo $$ > /cgroup/cp/tasks
cp /dev/zero /fs/zero &
rmdir /cgroup/dd
mkdir /cgroup/dd
echo $$ > /cgroup/dd/tasks
dd if=/dev/zero of=/fs/zero1 bs=64k &
dd if=/dev/zero of=/fs/zero2 bs=64k &
echo $$ > /cgroup/tasks
sleep 100
killall dd
killall cp
killall cat
- bps proportional (1 cp + 2 dd, with weights 500 and 1000)
Thanks,
Fengguang
---
PS. the new core changes to the dirty throttling code, supporting two
major block IO controller features with only 74 lines of new code.
It asks for more comments and cleanups. So please don't look at it
carefully. It refactors the code to share the blkcg dirty_ratelimit
update code with the existing bdi_update_dirty_ratelimit(), however it
turns out that not many lines are actually shared. So I might revert
to standalone blkcg_update_dirty_ratelimit() scheme in the next post.
mm/page-writeback.c | 146 +++++++++++++++++++++++++++++++-----------
1 file changed, 110 insertions(+), 36 deletions(-)
--- a/mm/page-writeback.c
+++ b/mm/page-writeback.c
@@ -34,6 +34,7 @@
#include <linux/syscalls.h>
#include <linux/buffer_head.h> /* __set_page_dirty_buffers */
#include <linux/pagevec.h>
+#include <linux/blk-cgroup.h>
#include <trace/events/writeback.h>
/*
@@ -836,35 +837,28 @@ static void global_update_bandwidth(unsigned long thresh,
* Normal bdi tasks will be curbed at or below it in long term.
* Obviously it should be around (write_bw / N) when there are N dd tasks.
*/
-static void bdi_update_dirty_ratelimit(struct backing_dev_info *bdi,
+static void bdi_update_dirty_ratelimit(unsigned int blkcg_id,
+ struct backing_dev_info *bdi,
+ unsigned long *pdirty_ratelimit,
+ unsigned long pos_ratio,
+ unsigned long write_bw,
unsigned long thresh,
unsigned long bg_thresh,
unsigned long dirty,
- unsigned long bdi_thresh,
- unsigned long bdi_dirty,
- unsigned long dirtied,
- unsigned long elapsed)
+ unsigned long dirty_rate)
{
unsigned long freerun = dirty_freerun_ceiling(thresh, bg_thresh);
unsigned long limit = hard_dirty_limit(thresh);
unsigned long setpoint = (freerun + limit) / 2;
- unsigned long write_bw = bdi->avg_write_bandwidth;
- unsigned long dirty_ratelimit = bdi->dirty_ratelimit;
- unsigned long dirty_rate;
+ unsigned long dirty_ratelimit = *pdirty_ratelimit;
unsigned long task_ratelimit;
unsigned long balanced_dirty_ratelimit;
- unsigned long pos_ratio;
unsigned long step;
unsigned long x;
- /*
- * The dirty rate will match the writeout rate in long term, except
- * when dirty pages are truncated by userspace or re-dirtied by FS.
- */
- dirty_rate = (dirtied - bdi->dirtied_stamp) * HZ / elapsed;
+ if (!blkcg_id && dirty < freerun)
+ return;
- pos_ratio = bdi_position_ratio(bdi, thresh, bg_thresh, dirty,
- bdi_thresh, bdi_dirty);
/*
* task_ratelimit reflects each dd's dirty rate for the past 200ms.
*/
@@ -904,11 +898,6 @@ static void bdi_update_dirty_ratelimit(struct backing_dev_info *bdi,
*/
balanced_dirty_ratelimit = div_u64((u64)task_ratelimit * write_bw,
dirty_rate | 1);
- /*
- * balanced_dirty_ratelimit ~= (write_bw / N) <= write_bw
- */
- if (unlikely(balanced_dirty_ratelimit > write_bw))
- balanced_dirty_ratelimit = write_bw;
/*
* We could safely do this and return immediately:
@@ -927,6 +916,11 @@ static void bdi_update_dirty_ratelimit(struct backing_dev_info *bdi,
* which reflects the direction and size of dirty position error.
*/
+ if (blkcg_id) {
+ dirty_ratelimit = (dirty_ratelimit + balanced_dirty_ratelimit) / 2;
+ goto out;
+ }
+
/*
* dirty_ratelimit will follow balanced_dirty_ratelimit iff
* task_ratelimit is on the same side of dirty_ratelimit, too.
@@ -946,13 +940,11 @@ static void bdi_update_dirty_ratelimit(struct backing_dev_info *bdi,
*/
step = 0;
if (dirty < setpoint) {
- x = min(bdi->balanced_dirty_ratelimit,
- min(balanced_dirty_ratelimit, task_ratelimit));
+ x = min(balanced_dirty_ratelimit, task_ratelimit);
if (dirty_ratelimit < x)
step = x - dirty_ratelimit;
} else {
- x = max(bdi->balanced_dirty_ratelimit,
- max(balanced_dirty_ratelimit, task_ratelimit));
+ x = max(balanced_dirty_ratelimit, task_ratelimit);
if (dirty_ratelimit > x)
step = dirty_ratelimit - x;
}
@@ -973,10 +965,12 @@ static void bdi_update_dirty_ratelimit(struct backing_dev_info *bdi,
else
dirty_ratelimit -= step;
- bdi->dirty_ratelimit = max(dirty_ratelimit, 1UL);
- bdi->balanced_dirty_ratelimit = balanced_dirty_ratelimit;
+out:
+ *pdirty_ratelimit = max(dirty_ratelimit, 1UL);
- trace_bdi_dirty_ratelimit(bdi, dirty_rate, task_ratelimit);
+ trace_bdi_dirty_ratelimit(bdi, write_bw, dirty_rate, dirty_ratelimit,
+ task_ratelimit, balanced_dirty_ratelimit,
+ blkcg_id);
}
void __bdi_update_bandwidth(struct backing_dev_info *bdi,
@@ -985,12 +979,14 @@ void __bdi_update_bandwidth(struct backing_dev_info *bdi,
unsigned long dirty,
unsigned long bdi_thresh,
unsigned long bdi_dirty,
+ unsigned long pos_ratio,
unsigned long start_time)
{
unsigned long now = jiffies;
unsigned long elapsed = now - bdi->bw_time_stamp;
unsigned long dirtied;
unsigned long written;
+ unsigned long dirty_rate;
/*
* rate-limit, only update once every 200ms.
@@ -1010,9 +1006,18 @@ void __bdi_update_bandwidth(struct backing_dev_info *bdi,
if (thresh) {
global_update_bandwidth(thresh, dirty, now);
- bdi_update_dirty_ratelimit(bdi, thresh, bg_thresh, dirty,
- bdi_thresh, bdi_dirty,
- dirtied, elapsed);
+ /*
+ * The dirty rate will match the writeout rate in long term,
+ * except when dirty pages are truncated by userspace or
+ * re-dirtied by FS.
+ */
+ dirty_rate = (dirtied - bdi->dirtied_stamp) * HZ / elapsed;
+ bdi_update_dirty_ratelimit(0, bdi,
+ &bdi->dirty_ratelimit,
+ pos_ratio,
+ bdi->avg_write_bandwidth,
+ thresh, bg_thresh, dirty,
+ dirty_rate);
}
bdi_update_write_bandwidth(bdi, elapsed, written);
@@ -1028,13 +1033,14 @@ static void bdi_update_bandwidth(struct backing_dev_info *bdi,
unsigned long dirty,
unsigned long bdi_thresh,
unsigned long bdi_dirty,
+ unsigned long pos_ratio,
unsigned long start_time)
{
if (time_is_after_eq_jiffies(bdi->bw_time_stamp + BANDWIDTH_INTERVAL))
return;
spin_lock(&bdi->wb.list_lock);
__bdi_update_bandwidth(bdi, thresh, bg_thresh, dirty,
- bdi_thresh, bdi_dirty, start_time);
+ bdi_thresh, bdi_dirty, pos_ratio, start_time);
spin_unlock(&bdi->wb.list_lock);
}
@@ -1149,6 +1155,51 @@ static long bdi_min_pause(struct backing_dev_info *bdi,
return pages >= DIRTY_POLL_THRESH ? 1 + t / 2 : t;
}
+static void blkcg_update_bandwidth(struct blkio_cgroup *blkcg,
+ struct backing_dev_info *bdi,
+ unsigned long pos_ratio)
+{
+#ifdef CONFIG_BLK_CGROUP
+ unsigned long now = jiffies;
+ unsigned long dirtied;
+ unsigned long elapsed;
+ unsigned long dirty_rate;
+ unsigned long bps = blkcg_buffered_write_bps(blkcg) >>
+ PAGE_CACHE_SHIFT;
+
+ if (!blkcg)
+ return;
+ if (!spin_trylock(&blkcg->lock))
+ return;
+
+ elapsed = now - blkcg->bw_time_stamp;
+ if (elapsed <= MAX_PAUSE)
+ goto unlock;
+
+ dirtied = percpu_counter_read(&blkcg->nr_dirtied);
+
+ if (elapsed > MAX_PAUSE * 2)
+ goto snapshot;
+
+ if (!bps)
+ bps = (u64)bdi->dirty_ratelimit * blkcg_weight(blkcg) /
+ BLKIO_WEIGHT_DEFAULT;
+ else
+ pos_ratio = 1 << RATELIMIT_CALC_SHIFT;
+
+ dirty_rate = (dirtied - blkcg->dirtied_stamp) * HZ / elapsed;
+ blkcg->dirty_rate = (blkcg->dirty_rate * 7 + dirty_rate) / 8;
+ bdi_update_dirty_ratelimit(1, bdi, &blkcg->dirty_ratelimit,
+ pos_ratio, bps, 0, 0, 0,
+ blkcg->dirty_rate);
+snapshot:
+ blkcg->dirtied_stamp = dirtied;
+ blkcg->bw_time_stamp = now;
+unlock:
+ spin_unlock(&blkcg->lock);
+#endif
+}
+
/*
* balance_dirty_pages() must be called by processes which are generating dirty
* data. It looks at the number of dirty pages in the machine and will force
@@ -1178,6 +1229,7 @@ static void balance_dirty_pages(struct address_space *mapping,
unsigned long pos_ratio;
struct backing_dev_info *bdi = mapping->backing_dev_info;
unsigned long start_time = jiffies;
+ struct blkio_cgroup *blkcg = task_blkio_cgroup(current);
for (;;) {
unsigned long now = jiffies;
@@ -1202,6 +1254,8 @@ static void balance_dirty_pages(struct address_space *mapping,
freerun = dirty_freerun_ceiling(dirty_thresh,
background_thresh);
if (nr_dirty <= freerun) {
+ if (blkcg && blkcg_buffered_write_bps(blkcg))
+ goto always_throttle;
current->dirty_paused_when = now;
current->nr_dirtied = 0;
current->nr_dirtied_pause =
@@ -1212,6 +1266,7 @@ static void balance_dirty_pages(struct address_space *mapping,
if (unlikely(!writeback_in_progress(bdi)))
bdi_start_background_writeback(bdi);
+always_throttle:
/*
* bdi_thresh is not treated as some limiting factor as
* dirty_thresh, due to reasons
@@ -1252,16 +1307,30 @@ static void balance_dirty_pages(struct address_space *mapping,
if (dirty_exceeded && !bdi->dirty_exceeded)
bdi->dirty_exceeded = 1;
+ pos_ratio = bdi_position_ratio(bdi, dirty_thresh,
+ background_thresh, nr_dirty,
+ bdi_thresh, bdi_dirty);
+
bdi_update_bandwidth(bdi, dirty_thresh, background_thresh,
nr_dirty, bdi_thresh, bdi_dirty,
- start_time);
+ pos_ratio, start_time);
dirty_ratelimit = bdi->dirty_ratelimit;
- pos_ratio = bdi_position_ratio(bdi, dirty_thresh,
- background_thresh, nr_dirty,
- bdi_thresh, bdi_dirty);
+ if (blkcg) {
+ blkcg_update_bandwidth(blkcg, bdi, pos_ratio);
+ if (!blkcg_buffered_write_bps(blkcg))
+ dirty_ratelimit = blkcg_dirty_ratelimit(blkcg);
+ }
+
task_ratelimit = ((u64)dirty_ratelimit * pos_ratio) >>
RATELIMIT_CALC_SHIFT;
+
+ if (blkcg && blkcg_buffered_write_bps(blkcg) &&
+ task_ratelimit > blkcg_dirty_ratelimit(blkcg)) {
+ task_ratelimit = blkcg_dirty_ratelimit(blkcg);
+ dirty_ratelimit = task_ratelimit;
+ }
+
max_pause = bdi_max_pause(bdi, bdi_dirty);
min_pause = bdi_min_pause(bdi, max_pause,
task_ratelimit, dirty_ratelimit,
@@ -1933,6 +2002,11 @@ int __set_page_dirty_no_writeback(struct page *page)
void account_page_dirtied(struct page *page, struct address_space *mapping)
{
if (mapping_cap_account_dirty(mapping)) {
+#ifdef CONFIG_BLK_DEV_THROTTLING
+ struct blkio_cgroup *blkcg = task_blkio_cgroup(current);
+ if (blkcg)
+ __percpu_counter_add(&blkcg->nr_dirtied, 1, BDI_STAT_BATCH);
+#endif
__inc_zone_page_state(page, NR_FILE_DIRTY);
__inc_zone_page_state(page, NR_DIRTIED);
__inc_bdi_stat(mapping->backing_dev_info, BDI_RECLAIMABLE);
Attachment:
balance_dirty_pages-task-bw.png
Description: PNG image
{kind=link}
Attachment:
balance_dirty_pages-task-bw.png
Description: PNG image
{kind=link}
Attachment:
balance_dirty_pages-task-bw.png
Description: PNG image
{kind=link}