On Mon, Feb 13, 2012 at 04:43:13PM +0100, Jan Kara wrote:
> On Sun 12-02-12 11:10:29, Wu Fengguang wrote:
> > 4) test case
> >
> > Run 2 dd tasks in a 100MB memcg (a very handy test case from Greg Thelen):
> >
> > mkdir /cgroup/x
> > echo 100M > /cgroup/x/memory.limit_in_bytes
> > echo $$ > /cgroup/x/tasks
> >
> > for i in `seq 2`
> > do
> > dd if=/dev/zero of=/fs/f$i bs=1k count=1M &
> > done
> >
> > Before patch, the dd tasks are quickly OOM killed.
> > After patch, they run well with reasonably good performance and overheads:
> >
> > 1073741824 bytes (1.1 GB) copied, 22.2196 s, 48.3 MB/s
> > 1073741824 bytes (1.1 GB) copied, 22.4675 s, 47.8 MB/s
> I wonder what happens if you run:
> mkdir /cgroup/x
> echo 100M > /cgroup/x/memory.limit_in_bytes
> echo $$ > /cgroup/x/tasks
>
> for (( i = 0; i < 2; i++ )); do
> mkdir /fs/d$i
> for (( j = 0; j < 5000; j++ )); do
> dd if=/dev/zero of=/fs/d$i/f$j bs=1k count=50
> done &
> done
That's a very good case, thanks!
> Because for small files the writearound logic won't help much...
Right, it also means the native background work cannot be more I/O
efficient than the pageout works, except for the overheads of more
work items..
> Also the number of work items queued might become interesting.
It turns out that the 1024 mempool reservations are not exhausted at
all (the below patch as a trace_printk on alloc failure and it didn't
trigger at all).
Here is the representative iostat lines on XFS (full "iostat -kx 1 20" log attached):
avg-cpu: %user %nice %system %iowait %steal %idle
0.80 0.00 6.03 0.03 0.00 93.14
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 205.00 0.00 163.00 0.00 16900.00 207.36 4.09 21.63 1.88 30.70
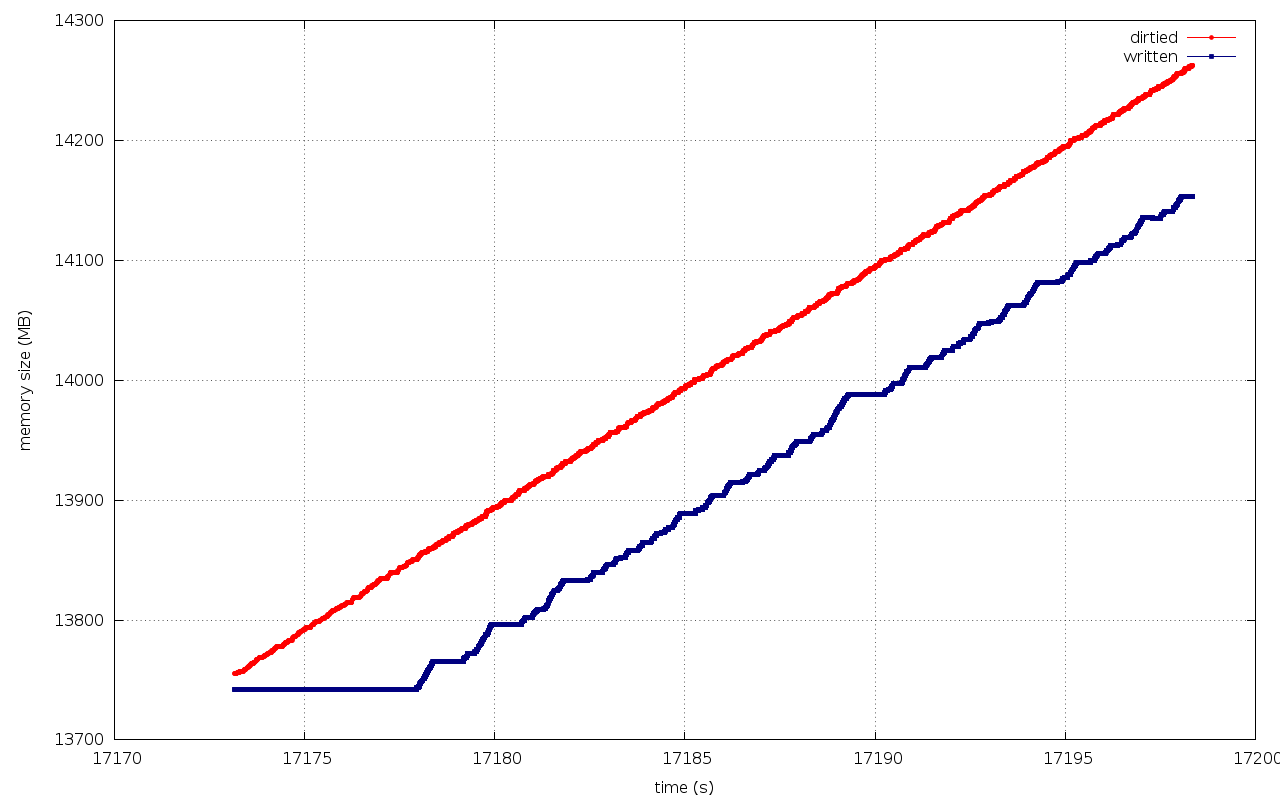
The attached dirtied/written progress graph looks interesting.
Although the iostat disk utilization is low, the "dirtied" progress
line is pretty straight and there is no single congestion_wait event
in the trace log. Which makes me wonder if there are some unknown
blocking issues in the way.
> Another common case to test - run 'slapadd' command in each cgroup to
> create big LDAP database. That does pretty much random IO on a big mmaped
> DB file.
I've not used this. Will it need some configuration and data feed?
fio looks more handy to me for emulating mmap random IO.
> > +/*
> > + * schedule writeback on a range of inode pages.
> > + */
> > +static struct wb_writeback_work *
> > +bdi_flush_inode_range(struct backing_dev_info *bdi,
> > + struct inode *inode,
> > + pgoff_t offset,
> > + pgoff_t len,
> > + bool wait)
> > +{
> > + struct wb_writeback_work *work;
> > +
> > + if (!igrab(inode))
> > + return ERR_PTR(-ENOENT);
> One technical note here: If the inode is deleted while it is queued, this
> reference will keep it living until flusher thread gets to it. Then when
> flusher thread puts its reference, the inode will get deleted in flusher
> thread context. I don't see an immediate problem in that but it might be
> surprising sometimes. Another problem I see is that if you try to
> unmount the filesystem while the work item is queued, you'll get EBUSY for
> no apparent reason (for userspace).
Yeah, we need to make umount work.
And I find the pageout works seem to have some problems with ext4.
For example, this can be easily triggered with 10 dd tasks running
inside the 100MB limited memcg:
[18006.858109] INFO: task jbd2/sda1-8:51294 blocked for more than 120 seconds.
[18006.866425] "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
[18006.876096] jbd2/sda1-8 D 0000000000000000 5464 51294 2 0x00000000
[18006.884729] ffff88040b097c70 0000000000000046 ffff880823032310 ffff88040b096000
[18006.894356] 00000000001d2f00 00000000001d2f00 ffff8808230322a0 00000000001d2f00
[18006.904000] ffff88040b097fd8 00000000001d2f00 ffff88040b097fd8 00000000001d2f00
[18006.913652] Call Trace:
[18006.916901] [<ffffffff8103d4af>] ? native_sched_clock+0x29/0x70
[18006.924134] [<ffffffff81232aab>] ? jbd2_journal_commit_transaction+0x1d0/0x1281
[18006.933324] [<ffffffff8109660d>] ? local_clock+0x41/0x5a
[18006.939879] [<ffffffff810b0ddd>] ? lock_release_holdtime+0xa3/0xac
[18006.947410] [<ffffffff81232aab>] ? jbd2_journal_commit_transaction+0x1d0/0x1281
[18006.956607] [<ffffffff81a57904>] schedule+0x5a/0x5c
[18006.962677] [<ffffffff81232ab0>] jbd2_journal_commit_transaction+0x1d5/0x1281
[18006.971683] [<ffffffff8103d4af>] ? native_sched_clock+0x29/0x70
[18006.978933] [<ffffffff810738ce>] ? try_to_del_timer_sync+0xba/0xc8
[18006.986452] [<ffffffff8109660d>] ? local_clock+0x41/0x5a
[18006.992999] [<ffffffff8108683a>] ? wake_up_bit+0x2a/0x2a
[18006.999542] [<ffffffff810738ce>] ? try_to_del_timer_sync+0xba/0xc8
[18007.007062] [<ffffffff81073a6f>] ? del_timer_sync+0xbb/0xce
[18007.013898] [<ffffffff810739b4>] ? process_timeout+0x10/0x10
[18007.020835] [<ffffffff81237bc1>] kjournald2+0xcf/0x242
[18007.027187] [<ffffffff8108683a>] ? wake_up_bit+0x2a/0x2a
[18007.033733] [<ffffffff81237af2>] ? commit_timeout+0x10/0x10
[18007.040574] [<ffffffff81086384>] kthread+0x95/0x9d
[18007.046542] [<ffffffff81a61134>] kernel_thread_helper+0x4/0x10
[18007.053675] [<ffffffff81a591b4>] ? retint_restore_args+0x13/0x13
[18007.061003] [<ffffffff810862ef>] ? __init_kthread_worker+0x5b/0x5b
[18007.068521] [<ffffffff81a61130>] ? gs_change+0x13/0x13
[18007.074878] no locks held by jbd2/sda1-8/51294.
Sometimes I also catch dd/ext4lazyinit/flush all stalling in start_this_handle:
[17985.439567] dd D 0000000000000007 3616 61440 1 0x00000004
[17985.448088] ffff88080d71b9b8 0000000000000046 ffff88081ec80070 ffff88080d71a000
[17985.457545] 00000000001d2f00 00000000001d2f00 ffff88081ec80000 00000000001d2f00
[17985.467168] ffff88080d71bfd8 00000000001d2f00 ffff88080d71bfd8 00000000001d2f00
[17985.476647] Call Trace:
[17985.479843] [<ffffffff8103d4af>] ? native_sched_clock+0x29/0x70
[17985.487025] [<ffffffff81230b9d>] ? start_this_handle+0x357/0x4ed
[17985.494313] [<ffffffff8109660d>] ? local_clock+0x41/0x5a
[17985.500815] [<ffffffff810b0ddd>] ? lock_release_holdtime+0xa3/0xac
[17985.508287] [<ffffffff81230b9d>] ? start_this_handle+0x357/0x4ed
[17985.515575] [<ffffffff81a57904>] schedule+0x5a/0x5c
[17985.521588] [<ffffffff81230c39>] start_this_handle+0x3f3/0x4ed
[17985.528669] [<ffffffff81147820>] ? kmem_cache_free+0xfa/0x13a
[17985.545142] [<ffffffff8108683a>] ? wake_up_bit+0x2a/0x2a
[17985.551650] [<ffffffff81230f0e>] jbd2__journal_start+0xb0/0xf6
[17985.558732] [<ffffffff811f7ad7>] ? ext4_dirty_inode+0x1d/0x4c
[17985.565716] [<ffffffff81230f67>] jbd2_journal_start+0x13/0x15
[17985.572703] [<ffffffff8120e3e9>] ext4_journal_start_sb+0x13f/0x157
[17985.580172] [<ffffffff8109660d>] ? local_clock+0x41/0x5a
[17985.586680] [<ffffffff811f7ad7>] ext4_dirty_inode+0x1d/0x4c
[17985.593472] [<ffffffff81176827>] __mark_inode_dirty+0x2e/0x1cc
[17985.600552] [<ffffffff81168e84>] file_update_time+0xe4/0x106
[17985.607441] [<ffffffff811079f6>] __generic_file_aio_write+0x254/0x364
[17985.615202] [<ffffffff81a565da>] ? mutex_lock_nested+0x2e4/0x2f3
[17985.622488] [<ffffffff81107b50>] ? generic_file_aio_write+0x4a/0xc1
[17985.630057] [<ffffffff81107b6c>] generic_file_aio_write+0x66/0xc1
[17985.637442] [<ffffffff811ef72b>] ext4_file_write+0x1f9/0x251
[17985.644330] [<ffffffff8109660d>] ? local_clock+0x41/0x5a
[17985.650835] [<ffffffff8118809e>] ? fsnotify+0x222/0x27b
[17985.657238] [<ffffffff81153612>] do_sync_write+0xce/0x10b
[17985.663844] [<ffffffff8118809e>] ? fsnotify+0x222/0x27b
[17985.670243] [<ffffffff81187ef8>] ? fsnotify+0x7c/0x27b
[17985.676561] [<ffffffff81153dbe>] vfs_write+0xb8/0x157
[17985.682767] [<ffffffff81154075>] sys_write+0x4d/0x77
[17985.688878] [<ffffffff81a5fce9>] system_call_fastpath+0x16/0x1b
and jbd2 in
[17983.623657] jbd2/sda1-8 D 0000000000000000 5464 51294 2 0x00000000
[17983.632173] ffff88040b097c70 0000000000000046 ffff880823032310 ffff88040b096000
[17983.641640] 00000000001d2f00 00000000001d2f00 ffff8808230322a0 00000000001d2f00
[17983.651119] ffff88040b097fd8 00000000001d2f00 ffff88040b097fd8 00000000001d2f00
[17983.660603] Call Trace:
[17983.663808] [<ffffffff8103d4af>] ? native_sched_clock+0x29/0x70
[17983.670997] [<ffffffff81232aab>] ? jbd2_journal_commit_transaction+0x1d0/0x1281
[17983.680124] [<ffffffff8109660d>] ? local_clock+0x41/0x5a
[17983.686638] [<ffffffff810b0ddd>] ? lock_release_holdtime+0xa3/0xac
[17983.694108] [<ffffffff81232aab>] ? jbd2_journal_commit_transaction+0x1d0/0x1281
[17983.703243] [<ffffffff81a57904>] schedule+0x5a/0x5c
[17983.709262] [<ffffffff81232ab0>] jbd2_journal_commit_transaction+0x1d5/0x1281
[17983.718195] [<ffffffff8103d4af>] ? native_sched_clock+0x29/0x70
[17983.725392] [<ffffffff810738ce>] ? try_to_del_timer_sync+0xba/0xc8
[17983.732867] [<ffffffff8109660d>] ? local_clock+0x41/0x5a
[17983.739374] [<ffffffff8108683a>] ? wake_up_bit+0x2a/0x2a
[17983.745864] [<ffffffff810738ce>] ? try_to_del_timer_sync+0xba/0xc8
[17983.753343] [<ffffffff81073a6f>] ? del_timer_sync+0xbb/0xce
[17983.760137] [<ffffffff810739b4>] ? process_timeout+0x10/0x10
[17983.767041] [<ffffffff81237bc1>] kjournald2+0xcf/0x242
[17983.773361] [<ffffffff8108683a>] ? wake_up_bit+0x2a/0x2a
[17983.779863] [<ffffffff81237af2>] ? commit_timeout+0x10/0x10
[17983.786665] [<ffffffff81086384>] kthread+0x95/0x9d
[17983.792585] [<ffffffff81a61134>] kernel_thread_helper+0x4/0x10
[17983.799670] [<ffffffff81a591b4>] ? retint_restore_args+0x13/0x13
[17983.806948] [<ffffffff810862ef>] ? __init_kthread_worker+0x5b/0x5b
Here is the updated patch used in the new tests. It moves
congestion_wait() out of the page lock and make flush_inode_page() no
longer wait for memory allocation (looks unnecessary).
Thanks,
Fengguang
---
Subject: writeback: introduce the pageout work
Date: Thu Jul 29 14:41:19 CST 2010
This relays file pageout IOs to the flusher threads.
The ultimate target is to gracefully handle the LRU lists full of
dirty/writeback pages.
1) I/O efficiency
The flusher will piggy back the nearby ~10ms worth of dirty pages for I/O.
This takes advantage of the time/spacial locality in most workloads: the
nearby pages of one file are typically populated into the LRU at the same
time, hence will likely be close to each other in the LRU list. Writing
them in one shot helps clean more pages effectively for page reclaim.
2) OOM avoidance and scan rate control
Typically we do LRU scan w/o rate control and quickly get enough clean
pages for the LRU lists not full of dirty pages.
Or we can still get a number of freshly cleaned pages (moved to LRU tail
by end_page_writeback()) when the queued pageout I/O is completed within
tens of milli-seconds.
However if the LRU list is small and full of dirty pages, it can be
quickly fully scanned and go OOM before the flusher manages to clean
enough pages.
A simple yet reliable scheme is employed to avoid OOM and keep scan rate
in sync with the I/O rate:
if (PageReclaim(page))
congestion_wait(HZ/10);
PG_reclaim plays the key role. When dirty pages are encountered, we
queue I/O for it, set PG_reclaim and put it back to the LRU head.
So if PG_reclaim pages are encountered again, it means the dirty page
has not yet been cleaned by the flusher after a full zone scan. It
indicates we are scanning more fast than I/O and shall take a snap.
The runtime behavior on a fully dirtied small LRU list would be:
It will start with a quick scan of the list, queuing all pages for I/O.
Then the scan will be slowed down by the PG_reclaim pages *adaptively*
to match the I/O bandwidth.
3) writeback work coordinations
To avoid memory allocations at page reclaim, a mempool for struct
wb_writeback_work is created.
wakeup_flusher_threads() is removed because it can easily delay the
more oriented pageout works and even exhaust the mempool reservations.
It's also found to not I/O efficient by frequently submitting writeback
works with small ->nr_pages.
Background/periodic works will quit automatically, so as to clean the
pages under reclaim ASAP. However for now the sync work can still block
us for long time.
Jan Kara: limit the search scope. Note that the limited search and work
pool is not a big problem: 1000 IOs under flight are typically more than
enough to saturate the disk. And the overheads of searching in the work
list didn't even show up in the perf report.
4) test case
Run 2 dd tasks in a 100MB memcg (a very handy test case from Greg Thelen):
mkdir /cgroup/x
echo 100M > /cgroup/x/memory.limit_in_bytes
echo $$ > /cgroup/x/tasks
for i in `seq 2`
do
dd if=/dev/zero of=/fs/f$i bs=1k count=1M &
done
Before patch, the dd tasks are quickly OOM killed.
After patch, they run well with reasonably good performance and overheads:
1073741824 bytes (1.1 GB) copied, 22.2196 s, 48.3 MB/s
1073741824 bytes (1.1 GB) copied, 22.4675 s, 47.8 MB/s
iostat -kx 1
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 0.00 0.00 178.00 0.00 89568.00 1006.38 74.35 417.71 4.80 85.40
sda 0.00 2.00 0.00 191.00 0.00 94428.00 988.77 53.34 219.03 4.34 82.90
sda 0.00 20.00 0.00 196.00 0.00 97712.00 997.06 71.11 337.45 4.77 93.50
sda 0.00 5.00 0.00 175.00 0.00 84648.00 967.41 54.03 316.44 5.06 88.60
sda 0.00 0.00 0.00 186.00 0.00 92432.00 993.89 56.22 267.54 5.38 100.00
sda 0.00 1.00 0.00 183.00 0.00 90156.00 985.31 37.99 325.55 4.33 79.20
sda 0.00 0.00 0.00 175.00 0.00 88692.00 1013.62 48.70 218.43 4.69 82.10
sda 0.00 0.00 0.00 196.00 0.00 97528.00 995.18 43.38 236.87 5.10 100.00
sda 0.00 0.00 0.00 179.00 0.00 88648.00 990.48 45.83 285.43 5.59 100.00
sda 0.00 0.00 0.00 178.00 0.00 88500.00 994.38 28.28 158.89 4.99 88.80
sda 0.00 0.00 0.00 194.00 0.00 95852.00 988.16 32.58 167.39 5.15 100.00
sda 0.00 2.00 0.00 215.00 0.00 105996.00 986.01 41.72 201.43 4.65 100.00
sda 0.00 4.00 0.00 173.00 0.00 84332.00 974.94 50.48 260.23 5.76 99.60
sda 0.00 0.00 0.00 182.00 0.00 90312.00 992.44 36.83 212.07 5.49 100.00
sda 0.00 8.00 0.00 195.00 0.00 95940.50 984.01 50.18 221.06 5.13 100.00
sda 0.00 1.00 0.00 220.00 0.00 108852.00 989.56 40.99 202.68 4.55 100.00
sda 0.00 2.00 0.00 161.00 0.00 80384.00 998.56 37.19 268.49 6.21 100.00
sda 0.00 4.00 0.00 182.00 0.00 90830.00 998.13 50.58 239.77 5.49 100.00
sda 0.00 0.00 0.00 197.00 0.00 94877.00 963.22 36.68 196.79 5.08 100.00
avg-cpu: %user %nice %system %iowait %steal %idle
0.25 0.00 15.08 33.92 0.00 50.75
0.25 0.00 14.54 35.09 0.00 50.13
0.50 0.00 13.57 32.41 0.00 53.52
0.50 0.00 11.28 36.84 0.00 51.38
0.50 0.00 15.75 32.00 0.00 51.75
0.50 0.00 10.50 34.00 0.00 55.00
0.50 0.00 17.63 27.46 0.00 54.41
0.50 0.00 15.08 30.90 0.00 53.52
0.50 0.00 11.28 32.83 0.00 55.39
0.75 0.00 16.79 26.82 0.00 55.64
0.50 0.00 16.08 29.15 0.00 54.27
0.50 0.00 13.50 30.50 0.00 55.50
0.50 0.00 14.32 35.18 0.00 50.00
0.50 0.00 12.06 33.92 0.00 53.52
0.50 0.00 17.29 30.58 0.00 51.63
0.50 0.00 15.08 29.65 0.00 54.77
0.50 0.00 12.53 29.32 0.00 57.64
0.50 0.00 15.29 31.83 0.00 52.38
The global dd numbers for comparison:
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 0.00 0.00 189.00 0.00 95752.00 1013.25 143.09 684.48 5.29 100.00
sda 0.00 0.00 0.00 208.00 0.00 105480.00 1014.23 143.06 733.29 4.81 100.00
sda 0.00 0.00 0.00 161.00 0.00 81924.00 1017.69 141.71 757.79 6.21 100.00
sda 0.00 0.00 0.00 217.00 0.00 109580.00 1009.95 143.09 749.55 4.61 100.10
sda 0.00 0.00 0.00 187.00 0.00 94728.00 1013.13 144.31 773.67 5.35 100.00
sda 0.00 0.00 0.00 189.00 0.00 95752.00 1013.25 144.14 742.00 5.29 100.00
sda 0.00 0.00 0.00 177.00 0.00 90032.00 1017.31 143.32 656.59 5.65 100.00
sda 0.00 0.00 0.00 215.00 0.00 108640.00 1010.60 142.90 817.54 4.65 100.00
sda 0.00 2.00 0.00 166.00 0.00 83858.00 1010.34 143.64 808.61 6.02 100.00
sda 0.00 0.00 0.00 186.00 0.00 92813.00 997.99 141.18 736.95 5.38 100.00
sda 0.00 0.00 0.00 206.00 0.00 104456.00 1014.14 146.27 729.33 4.85 100.00
sda 0.00 0.00 0.00 213.00 0.00 107024.00 1004.92 143.25 705.70 4.69 100.00
sda 0.00 0.00 0.00 188.00 0.00 95748.00 1018.60 141.82 764.78 5.32 100.00
avg-cpu: %user %nice %system %iowait %steal %idle
0.51 0.00 11.22 52.30 0.00 35.97
0.25 0.00 10.15 52.54 0.00 37.06
0.25 0.00 5.01 56.64 0.00 38.10
0.51 0.00 15.15 43.94 0.00 40.40
0.25 0.00 12.12 48.23 0.00 39.39
0.51 0.00 11.20 53.94 0.00 34.35
0.26 0.00 9.72 51.41 0.00 38.62
0.76 0.00 9.62 50.63 0.00 38.99
0.51 0.00 10.46 53.32 0.00 35.71
0.51 0.00 9.41 51.91 0.00 38.17
0.25 0.00 10.69 49.62 0.00 39.44
0.51 0.00 12.21 52.67 0.00 34.61
0.51 0.00 11.45 53.18 0.00 34.86
XXX: commit NFS unstable pages via write_inode()
XXX: the added congestion_wait() may be undesirable in some situations
CC: Jan Kara <jack@xxxxxxx>
CC: Mel Gorman <mgorman@xxxxxxx>
Acked-by: Rik van Riel <riel@xxxxxxxxxx>
CC: Greg Thelen <gthelen@xxxxxxxxxx>
CC: Minchan Kim <minchan.kim@xxxxxxxxx>
Signed-off-by: Wu Fengguang <fengguang.wu@xxxxxxxxx>
---
fs/fs-writeback.c | 169 ++++++++++++++++++++++++++++-
include/linux/writeback.h | 4
include/trace/events/writeback.h | 12 +-
mm/vmscan.c | 35 ++++--
4 files changed, 202 insertions(+), 18 deletions(-)
- move congestion_wait() out of the page lock: it's blocking btrfs lock_delalloc_pages()
--- linux.orig/mm/vmscan.c 2012-02-12 21:27:28.000000000 +0800
+++ linux/mm/vmscan.c 2012-02-13 12:14:20.000000000 +0800
@@ -767,7 +767,8 @@ static unsigned long shrink_page_list(st
struct scan_control *sc,
int priority,
unsigned long *ret_nr_dirty,
- unsigned long *ret_nr_writeback)
+ unsigned long *ret_nr_writeback,
+ unsigned long *ret_nr_pgreclaim)
{
LIST_HEAD(ret_pages);
LIST_HEAD(free_pages);
@@ -776,6 +777,7 @@ static unsigned long shrink_page_list(st
unsigned long nr_congested = 0;
unsigned long nr_reclaimed = 0;
unsigned long nr_writeback = 0;
+ unsigned long nr_pgreclaim = 0;
cond_resched();
@@ -813,6 +815,10 @@ static unsigned long shrink_page_list(st
if (PageWriteback(page)) {
nr_writeback++;
+ if (PageReclaim(page))
+ nr_pgreclaim++;
+ else
+ SetPageReclaim(page);
/*
* Synchronous reclaim cannot queue pages for
* writeback due to the possibility of stack overflow
@@ -874,12 +880,15 @@ static unsigned long shrink_page_list(st
nr_dirty++;
/*
- * Only kswapd can writeback filesystem pages to
- * avoid risk of stack overflow but do not writeback
- * unless under significant pressure.
+ * run into the visited page again: we are scanning
+ * faster than the flusher can writeout dirty pages
*/
- if (page_is_file_cache(page) &&
- (!current_is_kswapd() || priority >= DEF_PRIORITY - 2)) {
+ if (page_is_file_cache(page) && PageReclaim(page)) {
+ nr_pgreclaim++;
+ goto keep_locked;
+ }
+ if (page_is_file_cache(page) && mapping &&
+ flush_inode_page(mapping, page, false) >= 0) {
/*
* Immediately reclaim when written back.
* Similar in principal to deactivate_page()
@@ -1028,6 +1037,7 @@ keep_lumpy:
count_vm_events(PGACTIVATE, pgactivate);
*ret_nr_dirty += nr_dirty;
*ret_nr_writeback += nr_writeback;
+ *ret_nr_pgreclaim += nr_pgreclaim;
return nr_reclaimed;
}
@@ -1087,8 +1097,10 @@ int __isolate_lru_page(struct page *page
*/
if (mode & (ISOLATE_CLEAN|ISOLATE_ASYNC_MIGRATE)) {
/* All the caller can do on PageWriteback is block */
- if (PageWriteback(page))
+ if (PageWriteback(page)) {
+ SetPageReclaim(page);
return ret;
+ }
if (PageDirty(page)) {
struct address_space *mapping;
@@ -1509,6 +1521,7 @@ shrink_inactive_list(unsigned long nr_to
unsigned long nr_file;
unsigned long nr_dirty = 0;
unsigned long nr_writeback = 0;
+ unsigned long nr_pgreclaim = 0;
isolate_mode_t reclaim_mode = ISOLATE_INACTIVE;
struct zone *zone = mz->zone;
@@ -1559,13 +1572,13 @@ shrink_inactive_list(unsigned long nr_to
spin_unlock_irq(&zone->lru_lock);
nr_reclaimed = shrink_page_list(&page_list, mz, sc, priority,
- &nr_dirty, &nr_writeback);
+ &nr_dirty, &nr_writeback, &nr_pgreclaim);
/* Check if we should syncronously wait for writeback */
if (should_reclaim_stall(nr_taken, nr_reclaimed, priority, sc)) {
set_reclaim_mode(priority, sc, true);
nr_reclaimed += shrink_page_list(&page_list, mz, sc,
- priority, &nr_dirty, &nr_writeback);
+ priority, &nr_dirty, &nr_writeback, &nr_pgreclaim);
}
spin_lock_irq(&zone->lru_lock);
@@ -1608,6 +1621,8 @@ shrink_inactive_list(unsigned long nr_to
*/
if (nr_writeback && nr_writeback >= (nr_taken >> (DEF_PRIORITY-priority)))
wait_iff_congested(zone, BLK_RW_ASYNC, HZ/10);
+ if (nr_pgreclaim)
+ congestion_wait(BLK_RW_ASYNC, HZ/10);
trace_mm_vmscan_lru_shrink_inactive(zone->zone_pgdat->node_id,
zone_idx(zone),
@@ -2382,8 +2397,6 @@ static unsigned long do_try_to_free_page
*/
writeback_threshold = sc->nr_to_reclaim + sc->nr_to_reclaim / 2;
if (total_scanned > writeback_threshold) {
- wakeup_flusher_threads(laptop_mode ? 0 : total_scanned,
- WB_REASON_TRY_TO_FREE_PAGES);
sc->may_writepage = 1;
}
--- linux.orig/fs/fs-writeback.c 2012-02-12 21:27:28.000000000 +0800
+++ linux/fs/fs-writeback.c 2012-02-13 12:15:50.000000000 +0800
@@ -41,6 +41,8 @@ struct wb_writeback_work {
long nr_pages;
struct super_block *sb;
unsigned long *older_than_this;
+ struct inode *inode;
+ pgoff_t offset;
enum writeback_sync_modes sync_mode;
unsigned int tagged_writepages:1;
unsigned int for_kupdate:1;
@@ -65,6 +67,27 @@ struct wb_writeback_work {
*/
int nr_pdflush_threads;
+static mempool_t *wb_work_mempool;
+
+static void *wb_work_alloc(gfp_t gfp_mask, void *pool_data)
+{
+ /*
+ * bdi_flush_inode_range() may be called on page reclaim
+ */
+ if (current->flags & PF_MEMALLOC)
+ return NULL;
+
+ return kmalloc(sizeof(struct wb_writeback_work), gfp_mask);
+}
+
+static __init int wb_work_init(void)
+{
+ wb_work_mempool = mempool_create(1024,
+ wb_work_alloc, mempool_kfree, NULL);
+ return wb_work_mempool ? 0 : -ENOMEM;
+}
+fs_initcall(wb_work_init);
+
/**
* writeback_in_progress - determine whether there is writeback in progress
* @bdi: the device's backing_dev_info structure.
@@ -129,7 +152,7 @@ __bdi_start_writeback(struct backing_dev
* This is WB_SYNC_NONE writeback, so if allocation fails just
* wakeup the thread for old dirty data writeback
*/
- work = kzalloc(sizeof(*work), GFP_ATOMIC);
+ work = mempool_alloc(wb_work_mempool, GFP_NOWAIT);
if (!work) {
if (bdi->wb.task) {
trace_writeback_nowork(bdi);
@@ -138,6 +161,7 @@ __bdi_start_writeback(struct backing_dev
return;
}
+ memset(work, 0, sizeof(*work));
work->sync_mode = WB_SYNC_NONE;
work->nr_pages = nr_pages;
work->range_cyclic = range_cyclic;
@@ -186,6 +210,125 @@ void bdi_start_background_writeback(stru
spin_unlock_bh(&bdi->wb_lock);
}
+static bool extend_writeback_range(struct wb_writeback_work *work,
+ pgoff_t offset,
+ unsigned long write_around_pages)
+{
+ pgoff_t end = work->offset + work->nr_pages;
+
+ if (offset >= work->offset && offset < end)
+ return true;
+
+ /*
+ * for sequential workloads with good locality, include up to 8 times
+ * more data in one chunk
+ */
+ if (work->nr_pages >= 8 * write_around_pages)
+ return false;
+
+ /* the unsigned comparison helps eliminate one compare */
+ if (work->offset - offset < write_around_pages) {
+ work->nr_pages += write_around_pages;
+ work->offset -= write_around_pages;
+ return true;
+ }
+
+ if (offset - end < write_around_pages) {
+ work->nr_pages += write_around_pages;
+ return true;
+ }
+
+ return false;
+}
+
+/*
+ * schedule writeback on a range of inode pages.
+ */
+static struct wb_writeback_work *
+bdi_flush_inode_range(struct backing_dev_info *bdi,
+ struct inode *inode,
+ pgoff_t offset,
+ pgoff_t len,
+ bool wait)
+{
+ struct wb_writeback_work *work;
+
+ if (!igrab(inode))
+ return ERR_PTR(-ENOENT);
+
+ work = mempool_alloc(wb_work_mempool, wait ? GFP_NOIO : GFP_NOWAIT);
+ if (!work) {
+ trace_printk("wb_work_mempool alloc fail\n");
+ return ERR_PTR(-ENOMEM);
+ }
+
+ memset(work, 0, sizeof(*work));
+ work->sync_mode = WB_SYNC_NONE;
+ work->inode = inode;
+ work->offset = offset;
+ work->nr_pages = len;
+ work->reason = WB_REASON_PAGEOUT;
+
+ bdi_queue_work(bdi, work);
+
+ return work;
+}
+
+/*
+ * Called by page reclaim code to flush the dirty page ASAP. Do write-around to
+ * improve IO throughput. The nearby pages will have good chance to reside in
+ * the same LRU list that vmscan is working on, and even close to each other
+ * inside the LRU list in the common case of sequential read/write.
+ *
+ * ret > 0: success, found/reused a previous writeback work
+ * ret = 0: success, allocated/queued a new writeback work
+ * ret < 0: failed
+ */
+long flush_inode_page(struct address_space *mapping,
+ struct page *page,
+ bool wait)
+{
+ struct backing_dev_info *bdi = mapping->backing_dev_info;
+ struct inode *inode = mapping->host;
+ struct wb_writeback_work *work;
+ unsigned long write_around_pages;
+ pgoff_t offset = page->index;
+ int i;
+ long ret = 0;
+
+ if (unlikely(!inode))
+ return -ENOENT;
+
+ /*
+ * piggy back 8-15ms worth of data
+ */
+ write_around_pages = bdi->avg_write_bandwidth + MIN_WRITEBACK_PAGES;
+ write_around_pages = rounddown_pow_of_two(write_around_pages) >> 6;
+
+ i = 1;
+ spin_lock_bh(&bdi->wb_lock);
+ list_for_each_entry_reverse(work, &bdi->work_list, list) {
+ if (work->inode != inode)
+ continue;
+ if (extend_writeback_range(work, offset, write_around_pages)) {
+ ret = i;
+ break;
+ }
+ if (i++ > 100) /* limit search depth */
+ break;
+ }
+ spin_unlock_bh(&bdi->wb_lock);
+
+ if (!ret) {
+ offset = round_down(offset, write_around_pages);
+ work = bdi_flush_inode_range(bdi, inode,
+ offset, write_around_pages, wait);
+ if (IS_ERR(work))
+ ret = PTR_ERR(work);
+ }
+ return ret;
+}
+
/*
* Remove the inode from the writeback list it is on.
*/
@@ -833,6 +976,23 @@ static unsigned long get_nr_dirty_pages(
get_nr_dirty_inodes();
}
+static long wb_flush_inode(struct bdi_writeback *wb,
+ struct wb_writeback_work *work)
+{
+ struct writeback_control wbc = {
+ .sync_mode = WB_SYNC_NONE,
+ .nr_to_write = LONG_MAX,
+ .range_start = work->offset << PAGE_CACHE_SHIFT,
+ .range_end = (work->offset + work->nr_pages - 1)
+ << PAGE_CACHE_SHIFT,
+ };
+
+ do_writepages(work->inode->i_mapping, &wbc);
+ iput(work->inode);
+
+ return LONG_MAX - wbc.nr_to_write;
+}
+
static long wb_check_background_flush(struct bdi_writeback *wb)
{
if (over_bground_thresh(wb->bdi)) {
@@ -905,7 +1065,10 @@ long wb_do_writeback(struct bdi_writebac
trace_writeback_exec(bdi, work);
- wrote += wb_writeback(wb, work);
+ if (work->inode)
+ wrote += wb_flush_inode(wb, work);
+ else
+ wrote += wb_writeback(wb, work);
/*
* Notify the caller of completion if this is a synchronous
@@ -914,7 +1077,7 @@ long wb_do_writeback(struct bdi_writebac
if (work->done)
complete(work->done);
else
- kfree(work);
+ mempool_free(work, wb_work_mempool);
}
/*
--- linux.orig/include/trace/events/writeback.h 2012-02-12 21:27:33.000000000 +0800
+++ linux/include/trace/events/writeback.h 2012-02-12 21:27:34.000000000 +0800
@@ -23,7 +23,7 @@
#define WB_WORK_REASON \
{WB_REASON_BACKGROUND, "background"}, \
- {WB_REASON_TRY_TO_FREE_PAGES, "try_to_free_pages"}, \
+ {WB_REASON_PAGEOUT, "pageout"}, \
{WB_REASON_SYNC, "sync"}, \
{WB_REASON_PERIODIC, "periodic"}, \
{WB_REASON_LAPTOP_TIMER, "laptop_timer"}, \
@@ -45,6 +45,8 @@ DECLARE_EVENT_CLASS(writeback_work_class
__field(int, range_cyclic)
__field(int, for_background)
__field(int, reason)
+ __field(unsigned long, ino)
+ __field(unsigned long, offset)
),
TP_fast_assign(
strncpy(__entry->name, dev_name(bdi->dev), 32);
@@ -55,9 +57,11 @@ DECLARE_EVENT_CLASS(writeback_work_class
__entry->range_cyclic = work->range_cyclic;
__entry->for_background = work->for_background;
__entry->reason = work->reason;
+ __entry->ino = work->inode ? work->inode->i_ino : 0;
+ __entry->offset = work->offset;
),
TP_printk("bdi %s: sb_dev %d:%d nr_pages=%ld sync_mode=%d "
- "kupdate=%d range_cyclic=%d background=%d reason=%s",
+ "kupdate=%d range_cyclic=%d background=%d reason=%s ino=%lu offset=%lu",
__entry->name,
MAJOR(__entry->sb_dev), MINOR(__entry->sb_dev),
__entry->nr_pages,
@@ -65,7 +69,9 @@ DECLARE_EVENT_CLASS(writeback_work_class
__entry->for_kupdate,
__entry->range_cyclic,
__entry->for_background,
- __print_symbolic(__entry->reason, WB_WORK_REASON)
+ __print_symbolic(__entry->reason, WB_WORK_REASON),
+ __entry->ino,
+ __entry->offset
)
);
#define DEFINE_WRITEBACK_WORK_EVENT(name) \
--- linux.orig/include/linux/writeback.h 2012-02-12 21:27:28.000000000 +0800
+++ linux/include/linux/writeback.h 2012-02-12 21:27:34.000000000 +0800
@@ -40,7 +40,7 @@ enum writeback_sync_modes {
*/
enum wb_reason {
WB_REASON_BACKGROUND,
- WB_REASON_TRY_TO_FREE_PAGES,
+ WB_REASON_PAGEOUT,
WB_REASON_SYNC,
WB_REASON_PERIODIC,
WB_REASON_LAPTOP_TIMER,
@@ -94,6 +94,8 @@ long writeback_inodes_wb(struct bdi_writ
enum wb_reason reason);
long wb_do_writeback(struct bdi_writeback *wb, int force_wait);
void wakeup_flusher_threads(long nr_pages, enum wb_reason reason);
+long flush_inode_page(struct address_space *mapping, struct page *page,
+ bool wait);
/* writeback.h requires fs.h; it, too, is not included from here. */
static inline void wait_on_inode(struct inode *inode)
Attachment:
global_dirtied_written.png
Description: PNG image
{kind=link}
Linux 3.3.0-rc3-flush-page+ (snb) 02/14/2012 _x86_64_ (32 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.03 0.00 0.05 0.38 0.00 99.54
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sda 0.20 33.00 0.05 2.91 0.16 1025.66 694.73 1.50 508.37 6.10 1.80
avg-cpu: %user %nice %system %iowait %steal %idle
0.90 0.00 5.72 0.00 0.00 93.38
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 0.00 1.00 0.00 8.00 0.00 16.00 0.00 1.00 1.00 0.10
avg-cpu: %user %nice %system %iowait %steal %idle
0.90 0.00 5.82 0.00 0.00 93.28
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
avg-cpu: %user %nice %system %iowait %steal %idle
0.90 0.00 5.81 0.00 0.00 93.29
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
avg-cpu: %user %nice %system %iowait %steal %idle
0.83 0.00 5.84 0.00 0.00 93.33
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
avg-cpu: %user %nice %system %iowait %steal %idle
0.83 0.00 5.94 0.00 0.00 93.23
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 370.00 0.00 71.00 0.00 12480.00 351.55 11.17 71.76 3.56 25.30
avg-cpu: %user %nice %system %iowait %steal %idle
0.80 0.00 5.84 0.00 0.00 93.35
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 65.00 0.00 51.00 0.00 13104.00 513.88 2.85 170.22 4.00 20.40
avg-cpu: %user %nice %system %iowait %steal %idle
0.87 0.00 5.93 0.00 0.00 93.20
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 379.00 0.00 134.00 0.00 30004.00 447.82 15.43 116.99 4.11 55.10
avg-cpu: %user %nice %system %iowait %steal %idle
0.90 0.00 5.91 0.00 0.00 93.19
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 133.00 0.00 114.00 0.00 12792.00 224.42 3.20 28.12 2.30 26.20
avg-cpu: %user %nice %system %iowait %steal %idle
0.83 0.00 5.96 0.00 0.00 93.21
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 367.00 0.00 114.00 0.00 24960.00 437.89 12.55 110.12 4.35 49.60
avg-cpu: %user %nice %system %iowait %steal %idle
0.80 0.00 6.03 0.03 0.00 93.14
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 205.00 0.00 163.00 0.00 16900.00 207.36 4.09 21.63 1.88 30.70
avg-cpu: %user %nice %system %iowait %steal %idle
0.87 0.00 5.98 0.00 0.00 93.16
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 219.00 0.00 182.00 0.00 19292.00 212.00 4.42 21.41 1.97 35.80
avg-cpu: %user %nice %system %iowait %steal %idle
0.93 0.00 5.87 0.00 0.00 93.20
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 201.00 0.00 135.00 0.00 21216.00 314.31 6.39 55.44 2.97 40.10
avg-cpu: %user %nice %system %iowait %steal %idle
0.93 0.00 5.99 0.00 0.00 93.08
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 329.00 0.00 166.00 0.00 24336.00 293.20 10.42 58.39 3.19 53.00
avg-cpu: %user %nice %system %iowait %steal %idle
0.80 0.00 5.96 0.00 0.00 93.24
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 258.00 0.00 181.00 0.00 16848.00 186.17 4.01 17.64 1.36 24.70
avg-cpu: %user %nice %system %iowait %steal %idle
0.90 0.00 5.92 0.00 0.00 93.18
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 166.00 0.00 88.00 0.00 20488.00 465.64 6.09 86.72 4.68 41.20
avg-cpu: %user %nice %system %iowait %steal %idle
0.86 0.00 6.05 0.00 0.00 93.08
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 566.00 0.00 194.00 0.00 34528.00 355.96 20.50 78.32 3.16 61.30
avg-cpu: %user %nice %system %iowait %steal %idle
0.86 0.00 5.79 0.00 0.00 93.34
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 0.00 0.00 12.00 0.00 5616.00 936.00 0.77 506.67 9.58 11.50
avg-cpu: %user %nice %system %iowait %steal %idle
0.90 0.00 5.93 0.00 0.00 93.18
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 259.00 0.00 173.00 0.00 22464.00 259.70 4.79 27.67 2.09 36.10
avg-cpu: %user %nice %system %iowait %steal %idle
0.74 0.00 6.16 0.00 0.00 93.10
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 190.00 0.00 163.00 0.00 18304.00 224.59 3.67 22.50 1.78 29.00