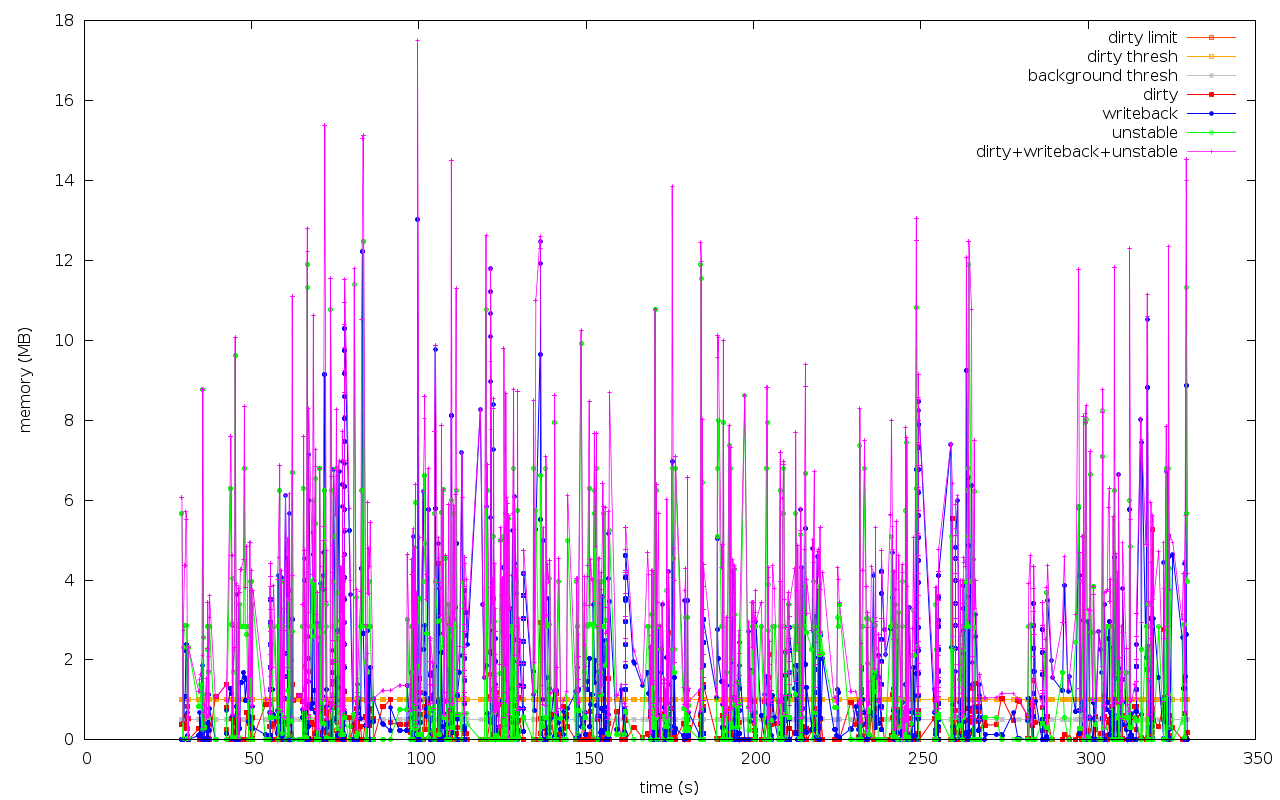
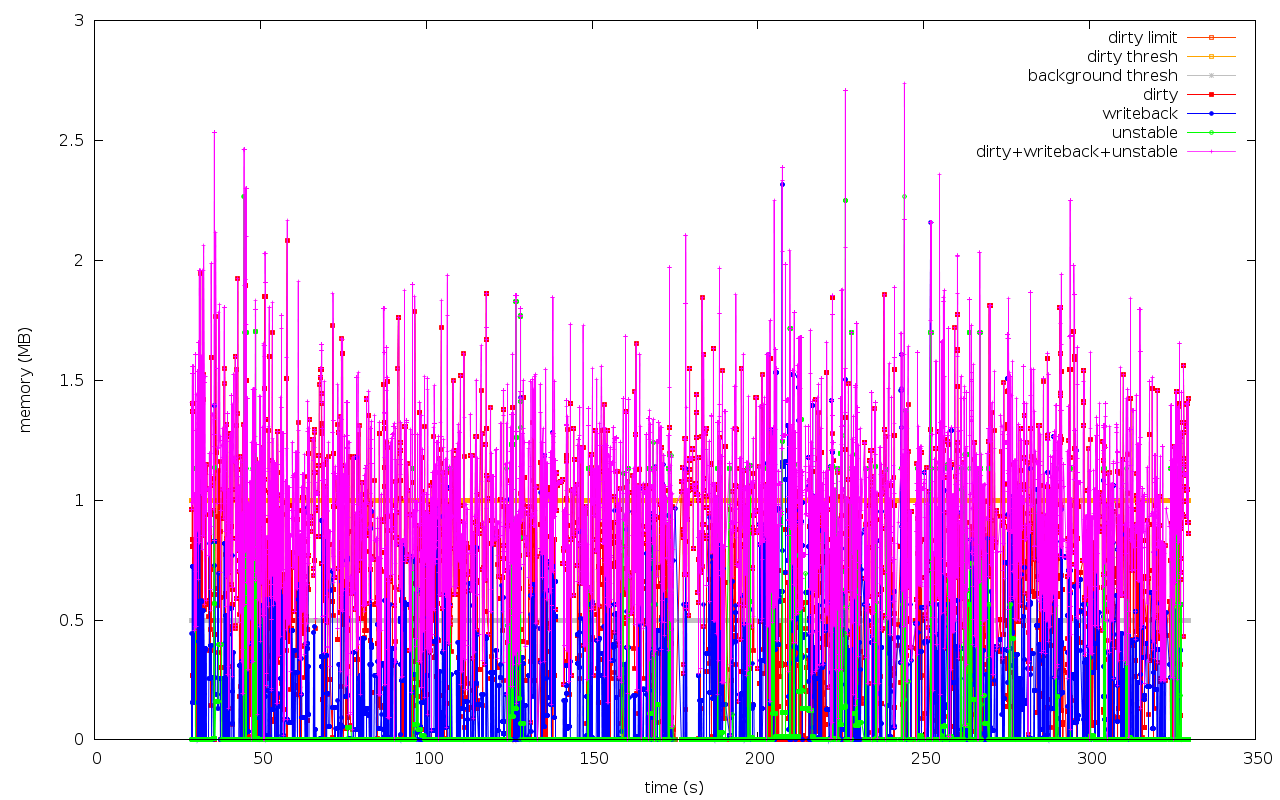
Hi, Aside from the big improvements in the 1G,100M,10M cases, the thresh=1M cases show big regressions. But there is a good reason. > 3.1.0-rc8-vanilla+ 3.1.0-rc8-nfs-wq4+ > ------------------------ ------------------------ > 21.85 +97.9% 43.23 NFS-thresh=100M/nfs-10dd-4k-32p-32768M-100M:10-X > 51.38 +42.6% 73.26 NFS-thresh=100M/nfs-1dd-4k-32p-32768M-100M:10-X > 28.81 +145.3% 70.68 NFS-thresh=100M/nfs-2dd-4k-32p-32768M-100M:10-X > 13.74 +57.1% 21.59 NFS-thresh=10M/nfs-10dd-4k-32p-32768M-10M:10-X > 29.11 -0.3% 29.02 NFS-thresh=10M/nfs-1dd-4k-32p-32768M-10M:10-X > 16.68 +90.5% 31.78 NFS-thresh=10M/nfs-2dd-4k-32p-32768M-10M:10-X > 48.88 +41.2% 69.01 NFS-thresh=1G/nfs-10dd-4k-32p-32768M-1024M:10-X > 57.85 +32.7% 76.74 NFS-thresh=1G/nfs-1dd-4k-32p-32768M-1024M:10-X > 47.13 +63.1% 76.87 NFS-thresh=1G/nfs-2dd-4k-32p-32768M-1024M:10-X > 9.82 -33.0% 6.58 NFS-thresh=1M/nfs-10dd-4k-32p-32768M-1M:10-X > 13.72 -18.1% 11.24 NFS-thresh=1M/nfs-1dd-4k-32p-32768M-1M:10-X > 15.68 -65.0% 5.48 NFS-thresh=1M/nfs-2dd-4k-32p-32768M-1M:10-X > 354.65 +45.4% 515.48 TOTAL write_bw The regressions in the thresh=1M cases are reasonably caused by the much reduced dirty/writeback/unstable pages. The attached graphs for the NFS-thresh=1M/nfs-10dd cases show the differences. The vanilla kernel (first graph) is much more permissive to allow dirty pages to exceed the global dirty limit, while the IO-less one applies the global dirty limit much more rigidly. Given the 18MB vs. 3MB max dirty+writeback+unstable pages, it's not surprising to see the better performance in the vanilla kernel. And it does not mean anything inherently wrong in the IO-less logic. Thanks, Fengguang
Attachment:
global_dirty_state.png
Description: PNG image
{kind=link}
Attachment:
global_dirty_state.png
Description: PNG image
{kind=link}