On Wed, Sep 07, 2011 at 08:17:42AM +0800, Jan Kara wrote:
> On Sun 04-09-11 09:53:20, Wu Fengguang wrote:
> > It's a years long problem that a large number of short-lived dirtiers
> > (eg. gcc instances in a fast kernel build) may starve long-run dirtiers
> > (eg. dd) as well as pushing the dirty pages to the global hard limit.
> I don't think it's years long problem. When we do per-cpu ratelimiting,
> short lived processes have the same chance (proportional to the number of
> pages dirtied) of hitting balance_dirty_pages() as long-run dirtiers have.
You are right in that all tasks will hit balance_dirty_pages().
However the caveat is, short lived tasks will see higher
task_bdi_thresh and hence immediately break out of the loop based on
condition !dirty_exceeded.
> So this problem seems to be introduced by your per task dirty ratelimiting?
> But given that you kept per-cpu ratelimiting in the end, is this still an
> issue?
The per-cpu ratelimit now (see "writeback: per task dirty rate limit")
only serves to backup the per-task ratelimit in case the latter fails.
In particular, the per-cpu thresh will typically be much higher than
the per-task thresh and the per-cpu counter will be reset each time
balance_dirty_pages() is called. So in practice the per-cpu thresh
will hardly trigger balance_dirty_pages(), which is exactly the
desired behavior: it will only kick in when the per-task thresh is not
working effectively due to sudden start of too many tasks.
> Do you have some numbers for this patch?
Good question! When trying to do so, I find it only works as expected
after applying this fix (well the zero current->dirty_paused_when
issue once hit my mind and unfortunately slip off later...):
@@ -1103,7 +1103,10 @@ static void balance_dirty_pages(struct a
task_ratelimit = (u64)dirty_ratelimit *
pos_ratio >> RATELIMIT_CALC_SHIFT;
period = (HZ * pages_dirtied) / (task_ratelimit | 1);
- pause = current->dirty_paused_when + period - now;
+ if (current->dirty_paused_when)
+ pause = current->dirty_paused_when + period - now;
+ else
+ pause = period;
/*
* For less than 1s think time (ext3/4 may block the dirtier
* for up to 800ms from time to time on 1-HDD; so does xfs,
The test case is to run one normal dd and two series of short lived dd's:
dd $DD_OPTS bs=${bs:-1M} if=/dev/zero of=$mnt/zero-$i &
(
file=$mnt/zero-append
touch $file
while test -f $file
do
dd $DD_OPTS oflag=append conv=notrunc if=/dev/zero of=$file bs=8k count=8
done
) &
(
file=$mnt/zero-append-2
touch $file
while test -f $file
do
dd $DD_OPTS oflag=append conv=notrunc if=/dev/zero of=$file bs=8k count=8
done
) &
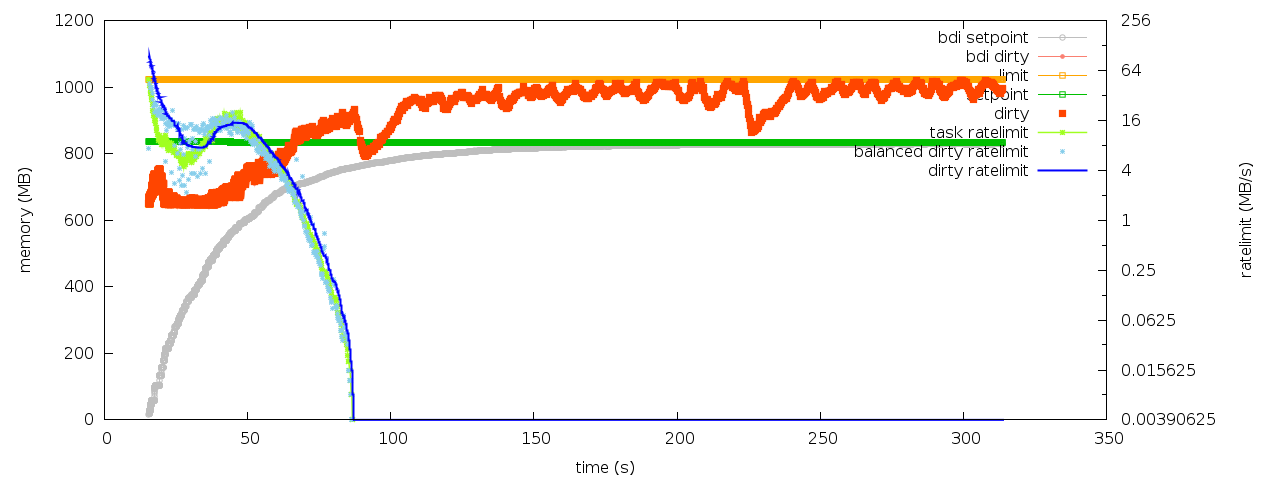
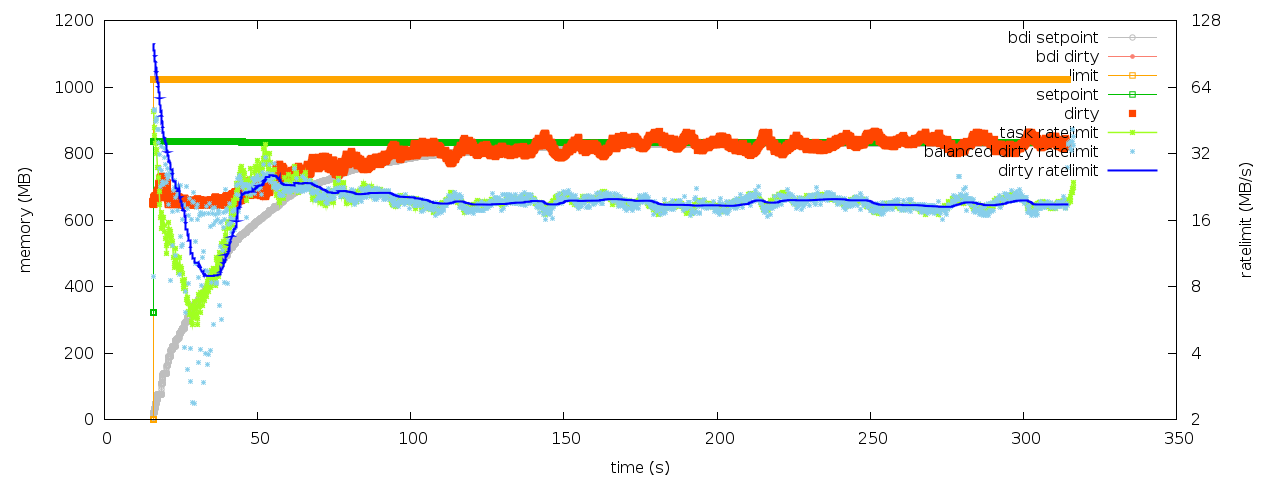
The attached figures show the behaviors before/after patch. Without
patch, the dirty pages hits @limit and bdi->dirty_ratelimit hits 1;
with the patch, the position&rate balances are effectively restored.
Thanks,
Fengguang
Attachment:
balance_dirty_pages-pages.png
Description: PNG image
{kind=link}
Attachment:
balance_dirty_pages-pages.png
Description: PNG image
{kind=link}