Hi,
This is a work-in-progress of what I presented at LSF/MM this year[0] to
greatly reduce contention on lru_lock, allowing it to scale on large systems.
This is completely different from the lru_lock series posted last January[1].
I'm hoping for feedback on the overall design and general direction as I do
more real-world performance testing and polish the code. Is this a workable
approach?
Thanks,
Daniel
---
Summary: lru_lock can be one of the hottest locks in the kernel on big
systems. It guards too much state, so introduce new SMP-safe list functions to
allow multiple threads to operate on the LRUs at once. The SMP list functions
are provided in a standalone API that can be used in other parts of the kernel.
When lru_lock and zone->lock are both fixed, the kernel can do up to 73.8% more
page faults per second on a 44-core machine.
---
On large systems, lru_lock can become heavily contended in memory-intensive
workloads such as decision support, applications that manage their memory
manually by allocating and freeing pages directly from the kernel, and
workloads with short-lived processes that force many munmap and exit
operations. lru_lock also inhibits scalability in many of the MM paths that
could be parallelized, such as freeing pages during exit/munmap and inode
eviction.
The problem is that lru_lock is too big of a hammer. It guards all the LRUs in
a pgdat's lruvec, needlessly serializing add-to-front, add-to-tail, and delete
operations that are done on disjoint parts of an LRU, or even completely
different LRUs.
This RFC series, developed in collaboration with Yossi Lev and Dave Dice,
offers a two-part solution to this problem.
First, three new list functions are introduced to allow multiple threads to
operate on the same linked list simultaneously under certain conditions, which
are spelled out in more detail in code comments and changelogs. The functions
are smp_list_del, smp_list_splice, and smp_list_add, and do the same things as
their non-SMP-safe counterparts. These primitives may be used elsewhere in the
kernel as the need arises; for example, in the page allocator free lists to
scale zone->lock[2], or in file system LRUs[3].
Second, lru_lock is converted from a spinlock to a rwlock. The idea is to
repurpose rwlock as a two-mode lock, where callers take the lock in shared
(i.e. read) mode for code using the SMP list functions, and exclusive (i.e.
write) mode for existing code that expects exclusive access to the LRUs.
Multiple threads are allowed in under the read lock, of course, and they use
the SMP list functions to synchronize amongst themselves.
The rwlock is scaffolding to facilitate the transition from big-hammer lru_lock
as it exists today to just using the list locking primitives and getting rid of
lru_lock entirely. Such an approach allows incremental conversion of lru_lock
writers until everything uses the SMP list functions and takes the lock in
shared mode, at which point lru_lock can just go away.
This RFC series is incomplete. More, and more realistic, performance
numbers are needed; for now, I show only will-it-scale/page_fault1.
Also, there are extensions I'd like to make to the locking scheme to
handle certain lru_lock paths--in particular, those where multiple
threads may delete the same node from an LRU. The SMP list functions
now handle only removal of _adjacent_ nodes from an LRU. Finally, the
diffstat should become more supportive after I remove some of the code
duplication in patch 6 by converting the rest of the per-CPU pagevec
code in mm/swap.c to use the SMP list functions.
Series based on 4.17.
Performance Numbers
-------------------
In the artificial benchmark will-it-scale/page_fault1, N tasks mmap, touch each
4K page in, and munmap an anonymous 128M memory region. The test is run in
process and thread modes on a 44-core Xeon E5-2699 v4 with 503G memory and
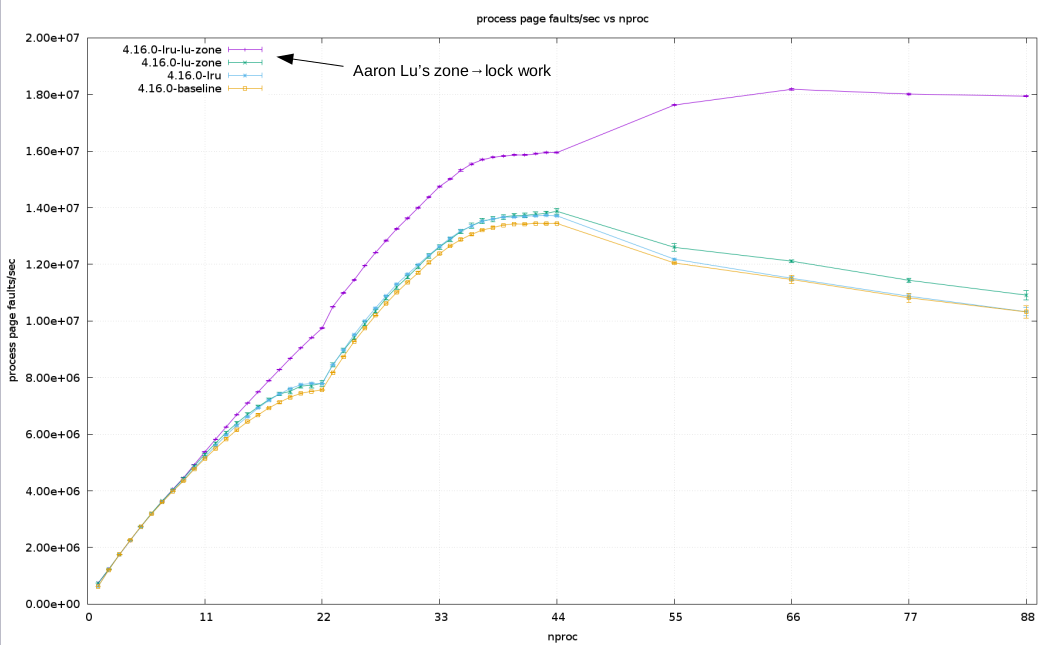
using a 4.16 baseline kernel. The table of results below is also graphed at:
https://raw.githubusercontent.com/danieljordan10/lru_lock-scalability/master/rfc-v2/graph.png
The lu-zone kernel refers to Aaron Lu's work from [4], the lru kernel is this
work, and the lru-lu-zone kernel contains both.
kernel (#) ntask proc thr proc stdev thr stdev
speedup speedup pgf/s pgf/s
baseline (1) 1 626,944 910 625,509 756
lu-zone (2) 1 18.0% 17.6% 739,659 2,038 735,896 2,139
lru (3) 1 0.1% -0.1% 627,490 878 625,162 770
lru-lu-zone (4) 1 17.4% 17.2% 735,983 2,349 732,936 2,640
baseline (1) 2 1,206,238 4,012 1,083,497 4,571
lu-zone (2) 2 2.4% 1.3% 1,235,318 3,158 1,097,745 8,919
lru (3) 2 0.1% 0.4% 1,207,246 4,988 1,087,846 5,700
lru-lu-zone (4) 2 2.4% 0.0% 1,235,271 3,005 1,083,578 6,915
baseline (1) 3 1,751,889 5,887 1,443,610 11,049
lu-zone (2) 3 -0.0% 1.9% 1,751,247 5,646 1,470,561 13,407
lru (3) 3 -0.4% 0.5% 1,744,999 7,040 1,451,507 13,186
lru-lu-zone (4) 3 -0.3% 0.2% 1,747,431 4,420 1,447,024 9,847
baseline (1) 4 2,260,201 11,482 1,769,095 16,576
lu-zone (2) 4 -0.5% 2.7% 2,249,463 14,628 1,816,409 10,988
lru (3) 4 -0.5% -0.8% 2,248,302 7,457 1,754,936 13,288
lru-lu-zone (4) 4 -0.8% 1.2% 2,243,240 10,386 1,790,833 11,186
baseline (1) 5 2,735,351 9,731 2,022,303 18,199
lu-zone (2) 5 -0.0% 3.1% 2,734,270 13,779 2,084,468 11,230
lru (3) 5 -0.5% -2.6% 2,721,069 8,417 1,970,701 14,747
lru-lu-zone (4) 5 0.0% -0.3% 2,736,317 11,533 2,016,043 10,324
baseline (1) 6 3,186,435 13,939 2,241,910 22,103
lu-zone (2) 6 0.7% 3.1% 3,207,879 17,603 2,311,070 12,345
lru (3) 6 -0.1% -1.6% 3,183,244 9,285 2,205,632 22,457
lru-lu-zone (4) 6 0.2% -0.2% 3,191,478 10,418 2,236,722 10,814
baseline (1) 7 3,596,306 17,419 2,374,538 29,782
lu-zone (2) 7 1.1% 5.6% 3,637,085 21,485 2,506,351 11,448
lru (3) 7 0.1% -1.2% 3,600,797 9,867 2,346,063 22,613
lru-lu-zone (4) 7 1.1% 1.6% 3,635,861 12,439 2,413,326 15,745
baseline (1) 8 3,986,712 15,947 2,519,189 30,129
lu-zone (2) 8 1.3% 3.7% 4,038,783 30,921 2,613,556 8,244
lru (3) 8 0.3% -0.8% 3,997,520 11,823 2,499,498 28,395
lru-lu-zone (4) 8 1.7% 4.3% 4,054,638 11,798 2,626,450 9,534
baseline (1) 11 5,138,494 17,634 2,932,708 31,765
lu-zone (2) 11 3.0% 6.6% 5,292,452 40,896 3,126,170 21,254
lru (3) 11 1.1% -1.1% 5,193,843 11,302 2,900,615 24,055
lru-lu-zone (4) 11 4.6% 2.4% 5,374,562 10,654 3,002,084 24,255
baseline (1) 22 7,569,187 13,649 3,134,116 58,149
lu-zone (2) 22 3.0% 9.6% 7,799,567 97,785 3,436,117 33,450
lru (3) 22 2.9% -0.8% 7,785,212 15,388 3,109,155 41,575
lru-lu-zone (4) 22 28.8% 7.6% 9,747,634 17,156 3,372,679 38,762
baseline (1) 33 12,375,135 30,387 2,180,328 56,529
lu-zone (2) 33 1.9% 8.9% 12,613,466 77,903 2,373,756 30,706
lru (3) 33 2.1% 3.1% 12,637,508 22,712 2,248,516 42,622
lru-lu-zone (4) 33 19.2% 9.1% 14,749,004 25,344 2,378,286 29,552
baseline (1) 44 13,446,153 14,539 2,365,487 53,966
lu-zone (2) 44 3.2% 7.8% 13,876,101 112,976 2,549,351 50,656
lru (3) 44 2.0% -8.1% 13,717,051 16,931 2,173,398 46,818
lru-lu-zone (4) 44 18.6% 7.4% 15,947,859 26,001 2,540,516 56,259
baseline (1) 55 12,050,977 30,210 2,372,251 58,151
lu-zone (2) 55 4.6% 3.2% 12,602,426 132,027 2,448,653 74,321
lru (3) 55 1.1% 1.5% 12,184,481 34,199 2,408,744 76,854
lru-lu-zone (4) 55 46.3% 3.1% 17,628,736 25,595 2,446,613 60,293
baseline (1) 66 11,464,526 146,140 2,389,751 55,417
lu-zone (2) 66 5.7% 17.5% 12,114,164 41,711 2,806,805 38,868
lru (3) 66 0.4% 13.2% 11,510,009 74,300 2,704,305 46,038
lru-lu-zone (4) 66 58.6% 17.0% 18,185,360 27,496 2,796,004 96,458
baseline (1) 77 10,818,432 149,865 2,634,568 49,631
lu-zone (2) 77 5.7% 4.9% 11,438,010 82,363 2,764,441 42,014
lru (3) 77 0.5% 3.5% 10,874,888 80,922 2,727,729 66,843
lru-lu-zone (4) 77 66.5% 1.4% 18,016,393 23,742 2,670,715 36,931
baseline (1) 88 10,321,790 214,000 2,815,546 40,597
lu-zone (2) 88 5.7% 8.3% 10,913,729 168,111 3,048,392 51,833
lru (3) 88 0.1% -3.6% 10,328,335 142,255 2,715,226 46,835
lru-lu-zone (4) 88 73.8% -3.6% 17,942,799 22,720 2,715,442 33,006
The lru-lu-zone kernel containing both lru_lock and zone->lock enhancements
outperforms kernels with either enhancement on its own. From this it's clear
that, no matter how each lock is scaled, both locks must be fixed to get rid of
this scalability issue in page allocation and freeing.
The thread case doesn't show much improvement because mmap_sem, not
lru_lock or zone->lock, is the limiting factor.
Low task counts show slight regressions but are mostly in the noise.
There's a significant speedup in the zone->lock kernels for the 1-task case,
possibly because the pages aren't merged when they're returned to the free
lists and so the cache is more likely to be warm on the next allocation.
Apart from this artificial microbenchmark, I'm experimenting with an extended
version of the SMP list locking functions (not shown here, still working on
these) that has allowed a commercial database using 4K pages to exit 6.3x
faster. This is with only lru_lock modified, no other kernel changes. The
speedup comes from the SMP list functions allowing the many database processes
to make concurrent mark_page_accessed calls from zap_pte_range while the shared
memory region is being freed. I'll post more about this later.
[0] https://lwn.net/Articles/753058/
[1] http://lkml.kernel.org/r/20180131230413.27653-1-daniel.m.jordan@xxxxxxxxxx
[2] http://lkml.kernel.org/r/20180509085450.3524-1-aaron.lu@xxxxxxxxx
[3] http://lkml.kernel.org/r/6bd1c8a5-c682-a3ce-1f9f-f1f53b4117a9@xxxxxxxxxx
[4] http://lkml.kernel.org/r/20180320085452.24641-1-aaron.lu@xxxxxxxxx
Daniel Jordan (8):
mm, memcontrol.c: make memcg lru stats thread-safe without lru_lock
mm: make zone_reclaim_stat updates thread-safe
mm: convert lru_lock from a spinlock_t to a rwlock_t
mm: introduce smp_list_del for concurrent list entry removals
mm: enable concurrent LRU removals
mm: splice local lists onto the front of the LRU
mm: introduce smp_list_splice to prepare for concurrent LRU adds
mm: enable concurrent LRU adds
include/linux/list.h | 3 +
include/linux/memcontrol.h | 43 ++++++--
include/linux/mm_inline.h | 28 +++++
include/linux/mmzone.h | 54 +++++++++-
init/main.c | 1 +
lib/Makefile | 2 +-
lib/list.c | 204 +++++++++++++++++++++++++++++++++++++
mm/compaction.c | 99 +++++++++---------
mm/huge_memory.c | 6 +-
mm/memcontrol.c | 53 ++++------
mm/memory_hotplug.c | 1 +
mm/mlock.c | 10 +-
mm/mmzone.c | 14 +++
mm/page_alloc.c | 2 +-
mm/page_idle.c | 4 +-
mm/swap.c | 183 ++++++++++++++++++++++++++++-----
mm/vmscan.c | 84 ++++++++-------
17 files changed, 620 insertions(+), 171 deletions(-)
create mode 100644 lib/list.c
--
2.18.0
{kind=link}
