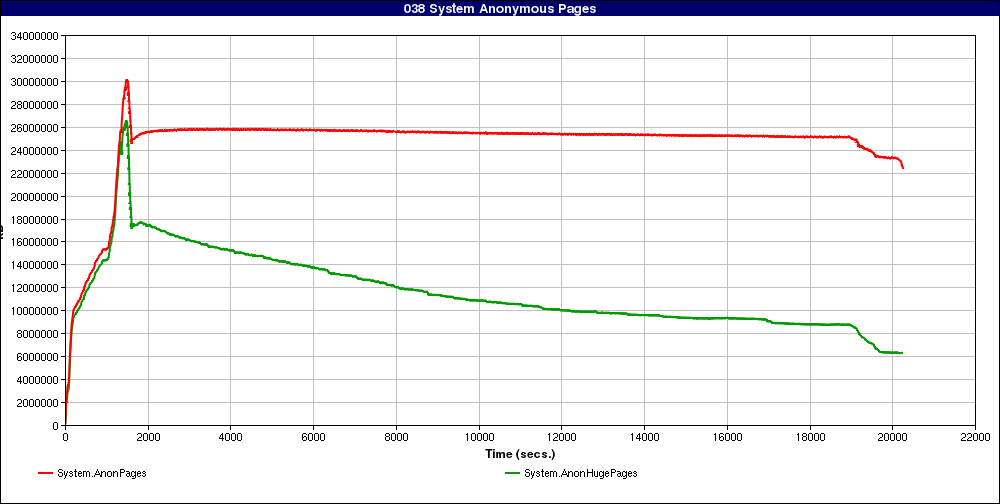
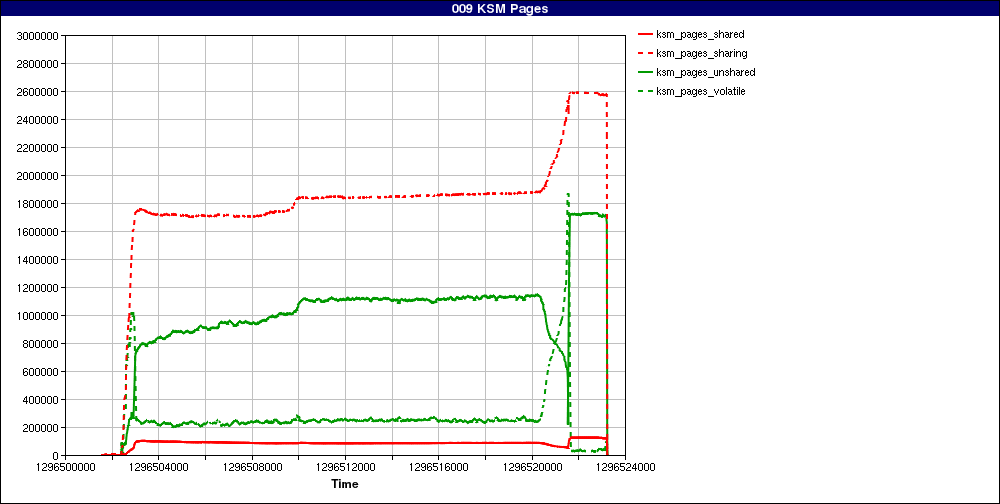
On Tue, Feb 01, 2011 at 09:15:47AM -0800, Dave Hansen wrote: > On Tue, 2011-02-01 at 16:38 +0100, Andrea Arcangeli wrote: > > On Mon, Jan 31, 2011 at 04:33:57PM -0800, Dave Hansen wrote: > > > I'm working on some more reports that transparent huge pages and > > > KSM do not play nicely together. Basically, whenever THP's are > > > present along with KSM, there is a lot of attrition over time, > > > and we do not see much overall progress keeping THP's around: > > > > > > http://sr71.net/~dave/ibm/038_System_Anonymous_Pages.png > > > > > > (That's Karl Rister's graph, thanks Karl!) > > > > Well if the pages_sharing/pages_shared count goes up, this is a > > feature not a bug.... You need to print that too in the chart to show > > this is not ok > > Here are the KSM sharing bits for the same run: > > http://sr71.net/~dave/ibm/009_KSM_Pages.png > > It bounces around a little bit on the ends, but it's fairly static > during the test, even when there's a good downward slope on the THP's. > > Hot of the presses, Karl also managed to do a run last night with the > khugepaged scanning rates turned all the way up: > > http://sr71.net/~dave/ibm/038_System_Anonymous_Pages-scan-always.png > > The THP's there are a lot more stable. I'd read that as saying that the > scanning probably just isn't keeping up with whatever is breaking the > pages up. This is exactly the case. But note that it's not obvious that keeping the hugepage number up steady is beneficial in terms of final performance: what happens now is you split and collapse (collapse requires copy so it's more costly than split) hugepages at higher frequency than before (the hugepages are still split but now they're collapsed faster and ksm has to split them again). So now the speedup from hugepages needs to also offset the cost of the more frequent split/collapse events that didn't happen before. So I guess considering the time is of the order of 2/3 hours and there are "only" 88G of memory, speeding up khugepaged is going to be beneficial considering how big boost hugepages gives to the guest with NPT/EPT and even bigger boost for regular shadow paging, but it also depends on guest. In short khugepaged by default is tuned in a way that can't run in the way of the CPU. I recall Avi once suggested someday we'd need khugepaged running at 100% load cpu like it may happen for ksmd. It's not needed yet though but this is just to say you're perfectly right assuming the default scanning rate may be too slow. But it's really meant to be tuned depending on the size of the system, how many cores, how many gb of ram to scan etc, if KSM is on, etc... KSM internal checksum check before adding rmap_items to the unstable tree already should prevent false sharing between ksm and khugepaged. Plus khugepaged will stay away if the page is shared by KSM. So because of this the risk of false sharing is low even running both at 100% load on the same VM. khugepaged default scan rate may be good idea to increase too for large systems with lots of cpus and lots of memory, the default is super paranoid and to be optimistic to still get a net gain for the netbooks and cellphones if any collapse happens ;). I'm generally very pleased to see these charts. It reminds me that Microsoft and Oracle can't support hugepages and KSM simultaneously, and at least Oracle Xen doesn't even have KSM at all (there's some attempt to share guest cache or find equal I/O or stuff like that but it won't help for guest anonymous memory which incidentally is where HPC at places like LHC needs KSM running). Xen doesn't even support swapping (easy to use THP in hypervisor if you don't support swapping, of course Oracle Xen wouldn't support swapping even if it would use 4k pages.. ;). So current status of KSM over THP, where KSM scans inside THP pages, and where 2m pages, 4k regular pages, and 4k KSM nonlinar pages with special rmap_item are mixed in the same VMA, and where both regular 4k pages, 2m pages and even the ksm pages are all swappable, and with mmu notifier keeping shadow MMU or NPT/EPT in full synchrony with the Linux VM so that both the KSM and THP algorithms are 100% secondary-mmu agnostic, is quite a milestone for 2.6.38 and I hope this will be a good proof of how the KVM design is superior and with less effort we can achieve things that they may never support with equal or better performance (in the KSM case our shared guest filesystem cache remains readonly mapped and natively handled by guest without any paravirt, like if KSM didn't merge anything). > I'm happy to hold on to them for another release. I'm actually going to > go look at the freezes I saw now that I have these out in the wild. I'm also going to have a closer look. The other report you can see search for subject "khugepaged" in lkml from JindÅich (I think compaction is too heavy, a walk in the park compared to lumpy reclaim but we need to make it more latency friendly, I also got a report that latency increases with heavy I/O that I think is the same thing that JindÅich sees). Yet another report shows a full hang with khugepaged waiting on mmap_sem but I think that is not related to THP, maybe something hung on the mmap_sem, khugepaged doesn't seem the holder of it. I myself had an issue with PROVE_LOCKING and I deadlocked inside _raw_spin_unlock_irq (how can I possibly deadlock inside unlock? must be prove locking bug? I didn't yet check if there have been updates in that area). There is also a known bug that I didn't fix yet and it's the next thing I need to address and it's the pgd_lock hold with irq disabled taking the page_table_lock. That is buggy with THP=off too, but it only triggers with NR_CPUS small enough so to disable PT locks (for small smp builds PT lock becomes the page_table_lock and then it'll deadlock when sending IPI with page_table_lock hold because the vmalloc fault will take pgd_lock with irqs disabled). I've no idea why pgd_lock is taken with irq disabled. No other issue. It's not as bad as it seems, likely turning congestion_wait in compaction and breaking the compaction look and a few other tweaks to compaction will solve the latency issue with lots of dirty cache. the pgd_lock is likely easily fixable too. Your issue and the mmap_sem read mode hang I didn't look into yet but they may not be related to this. Also your issue looked like the pgd_lock bug that I already know about, so maybe it's nothing new (maybe the mmap_sem too, I've no idea at the moment). I never reproduced this myself yet. Anyway there's nothing really concerning, no mm corruption or weird oops whatsoever ever reported, a spinlock or mmap_sem deadlock not enough to worry me ;). > I'll probably stick them in a git tree and keep them up to date. > > Are there any other THP issues you're chasing at the moment? I reviewed it too, and I see no problems. So if you fix those two bits that Johannes pointed out (remove the split that is superfluous after wait_ if you hold mmap_sem or rmap lock and add the split to the other walkers not yet covered) I think they can go in now without waiting. -- To unsubscribe, send a message with 'unsubscribe linux-mm' in the body to majordomo@xxxxxxxxxx For more info on Linux MM, see: http://www.linux-mm.org/ . Fight unfair telecom policy in Canada: sign http://dissolvethecrtc.ca/ Don't email: <a href=mailto:"dont@xxxxxxxxx";> email@xxxxxxxxx </a>
{kind=link}
{kind=link}
{kind=link}