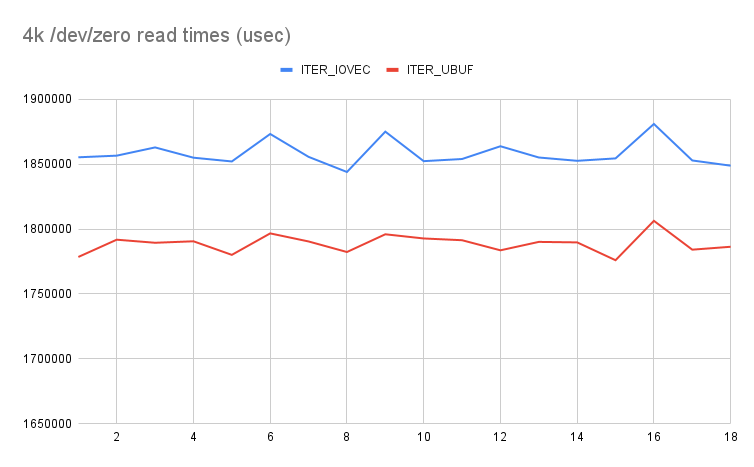
Hi, No real changes since v6, just sending it out so that whatever is in my tree matches what has been sent out upstream. Changes since v6: - Rearrange a few of the sound/IB patches to avoid them seeing ITER_UBUF in the middle of the series. End result is the same. - Correct a few comments, notably one on why __ubuf_iovec isn't const. Passes all my testing, and also re-ran the micro benchmark as it's probably more relevant than my peak testing. In short, it's reading 4k from /dev/zero in a loop with readv. Before the patches, that'd be turned into an ITER_IOVEC, and after an ITER_UBUF. Graph here: https://kernel.dk/4k-zero-read.png and in real numbers it ends up being a 3.7% reduction with using ITER_UBUF. Sadly, in absolute numbers, comparing read(2) and readv(2), the latter takes 2.11x as long in the stock kernel, and 2.01x as long with the patches. So while single segment is better now than before, it's still waaaay slower than having to copy in a single iovec. Testing was run with all security mitigations off. -- Jens Axboe
{kind=link}
