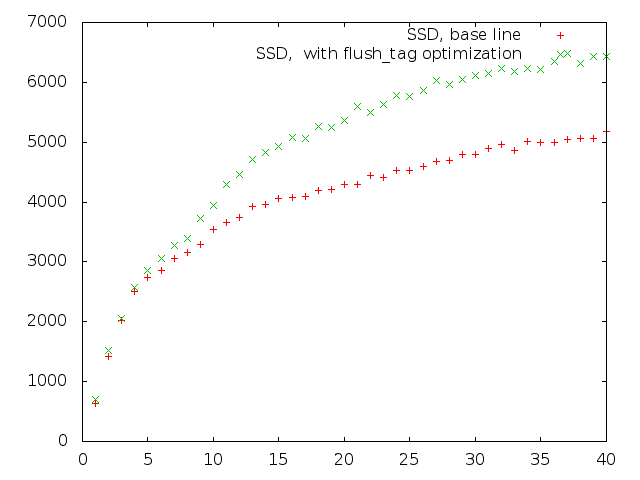
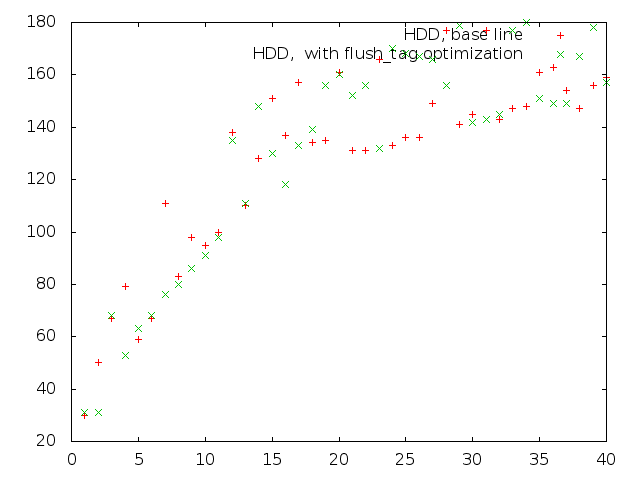
Some filesystems try to optimize barrier flushes by maintaining fs-specific generation counters, but if we introduce generic flush generation counter for block device filesystems may use it for fdatasync(2) optimization. Optimization should works if userspace performs mutli-threaded IO with a lot of fdatasync() Here are graphs for a test where each task performs random buffered writes to dedicated file and performs fdatasync(2) after each operation. Axis: x=nr_tasks, y=write_iops
# Chunk server simulation workload
# Files 'chunk.$NUM_JOB.0' should be precreated before the test
#
[global]
bs=4k
ioengine=psync
filesize=64M
size=8G
direct=0
runtime=30
directory=/mnt
fdatasync=1
group_reporting=1
[chunk]
overwrite=1
new_group=1
write_bw_log=bw.log
rw=randwrite
numjobs=${NUM_JOBS}
fsync=1
stonewall
Attachment:
ssd-fsync.png
Description: PNG image
Attachment:
hdd-fsync.png
Description: PNG image
TOC: 0001 blkdev: add flush generation counter 0002 ext4: Add fdatasync scalability optimization

{kind=link}
{kind=link}