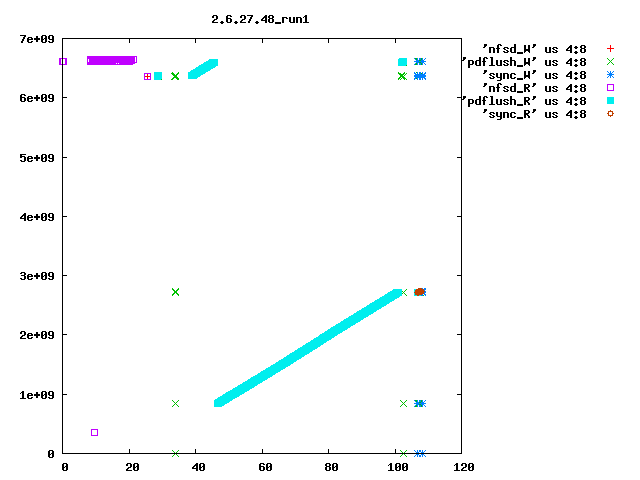
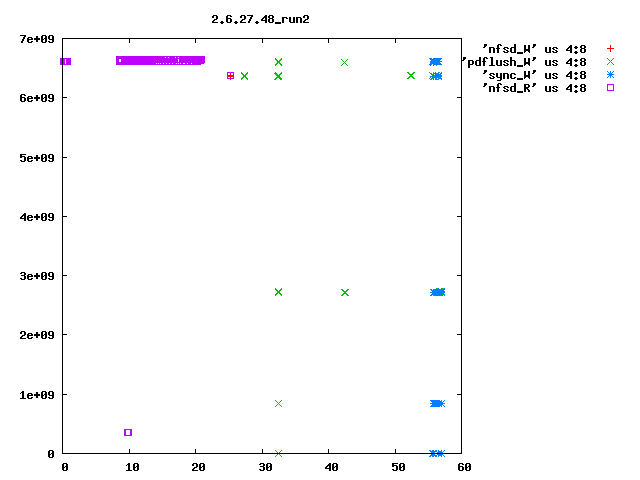
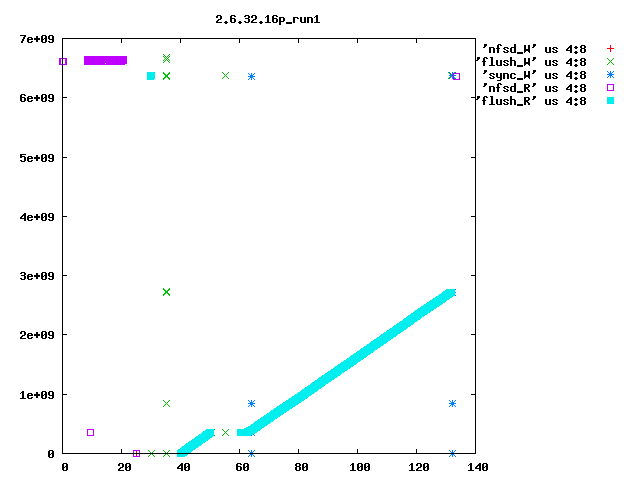
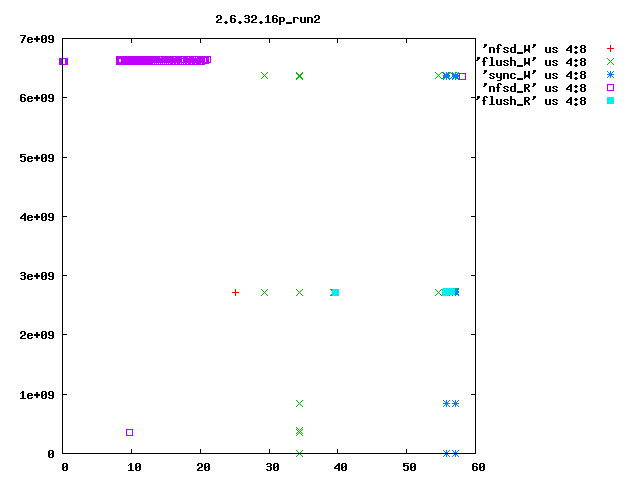
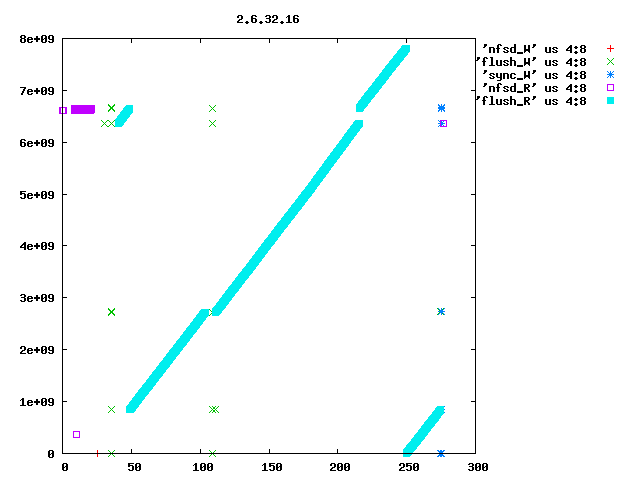
Eric Sandeen schrieb: > On 08/02/2010 09:52 AM, Kay Diederichs wrote: >> Dave, >> >> as you suggested, we reverted "ext4: Avoid group preallocation for >> closed files" and this indeed fixes a big part of the problem: after >> booting the NFS server we get >> >> NFS-Server: turn5 2.6.32.16p i686 >> NFS-Client: turn10 2.6.18-194.8.1.el5 x86_64 >> >> exported directory on the nfs-server: >> /dev/md5 /mnt/md5 ext4 >> rw,seclabel,noatime,barrier=1,stripe=512,data=writeback 0 0 >> >> 48 seconds for preparations >> 28 seconds to rsync 100 frames with 597M from nfs directory >> 57 seconds to rsync 100 frames with 595M to nfs directory >> 70 seconds to untar 24353 kernel files with 323M to nfs directory >> 57 seconds to rsync 24353 kernel files with 323M from nfs directory >> 133 seconds to run xds_par in nfs directory >> 425 seconds to run the script > > Interesting, I had found this commit to be a problem for small files > which are constantly created & deleted; the commit had the effect of > packing the newly created files in the first free space that could be > found, rather than walking down the disk leaving potentially fragmented > freespace behind (see seekwatcher graph attached). Reverting the patch > sped things up for this test, but left the filesystem freespace in bad > shape. > > But you seem to see one of the largest effects in here: > > 261 seconds to rsync 100 frames with 595M to nfs directory > vs > 57 seconds to rsync 100 frames with 595M to nfs directory > > with the patch reverted making things go faster. So you are doing 100 > 6MB writes to the server, correct? Is the filesystem mkfs'd fresh > before each test, or is it aged? If not mkfs'd, is it at least > completely empty prior to the test, or does data remain on it? I'm just > wondering if fragmented freespace is contributing to this behavior as > well. If there is fragmented freespace, then with the patch I think the > allocator is more likely to hunt around for small discontiguous chunks > of free sapce, rather than going further out in the disk looking for a > large area to allocate from. > > It might be interesting to use seekwatcher on the server to visualize > the allocation/IO patterns for the test running just this far? > > -Eric > > > ------------------------------------------------------------------------ > Eric, seekwatcher does not seem to understand the blktrace output of old kernels, so I rolled my own primitive plotting, e.g. blkparse -i md5.xds_par.2.6.32.16p_run1 > blkparse.out grep flush blkparse.out | grep W > flush_W grep flush blkparse.out | grep R > flush_R grep nfsd blkparse.out | grep R > nfsd_R grep nfsd blkparse.out | grep W > nfsd_W grep sync blkparse.out | grep R > sync_R grep sync blkparse.out | grep W > sync_W gnuplot<<EOF set term png set out '2.6.32.16p_run1.png' set key outside set title "2.6.32.16p_run1" plot 'nfsd_W' us 4:8,'flush_W' us 4:8,'sync_W' us 4:8,'nfsd_R' us 4:8,'flush_R' us 4:8 EOF I attach the resulting plots for 2.6.27.48_run1 (after booting) and 2.6.27.48_run2 (after run1 ; sync; and drop_cache). They show seconds on the x axis (horizontal) and block numbers (512-byte blocks, I suppose; the ext4 filesystem has 976761344 4096-byte blocks so that would be about 8e+09 512-byte blocks) on the y axis (vertical). You'll have to do the real interpretation of the plots yourself, but even someone who does not know exactly what the pdflush (in 2.6.27.48) or flush (in 2.6.32+) kernel threads are supposed to do can tell that the kernels behave _very_ differently. In particular, stock 2.6.32.16 every time (only run1 is shown, but run2 is the same) has the flush thread visiting all of the filesystem, in steps of 263168 blocks. I have no idea why it does this. Roughly the first 1/3 of the filesystem is also visited by kernels 2.6.27.48 and the patched 2.6.32.16 that Dave Chinner suggested, but only in the first run after booting. Subsequent runs are fast and do not employ the flush thread much. Hope this helps to pin down the regression. thanks, Kay
Attachment:
smime.p7s
Description: S/MIME Cryptographic Signature
