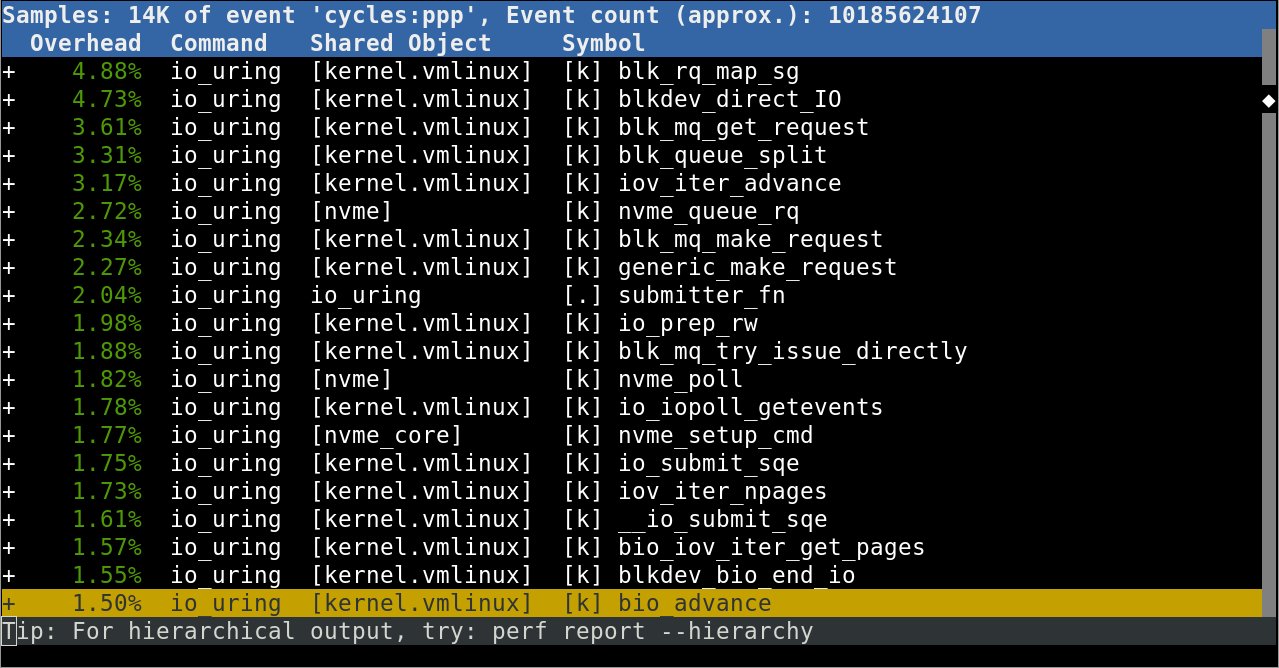
On 2/26/19 6:57 PM, Jens Axboe wrote: > Speaking of this, I took a quick look at why we've now regressed a lot > on IOPS perf with the multipage work. It looks like it's all related to > the (much) fatter setup around iteration, which is related to this very > topic too. > > Basically setup of things like bio_for_each_bvec() and indexing through > nth_page() is MUCH slower than before. > > We need to do something about this, it's like tossing out months of > optimizations. See attached quick profile. This is doing 4k IOS, btw, so just single segment requests. Yet we spend most of the time in blk_rq_map_sg(), and blk_queue_split() is not far behind. Between just the two of them, that's more than 8% of the total CPU utilization. As this test case is running on just one CPU for all of it, that's a LOT of wasted time. -- Jens Axboe
Attachment:
perf.jpg
Description: JPEG image

{kind=link}