Hi Marc,
Thanks for the reply! (And sorry for a late reply...)
On Sun, Dec 5, 2021 at 2:30 AM Marc Zyngier <maz@xxxxxxxxxx> wrote:
>
> Hi Hikaru,
>
> Apologies for the much delayed reply.
>
> > The problems described by Thomas in the thread was:
> > - User space or kernel space can observe the stale timestamp before
> > the adjustment
> > - Moving CLOCK_MONOTONIC forward will trigger all sorts of timeouts,
> > watchdogs, etc...
> > - The last attempt to make CLOCK_MONOTONIC behave like CLOCK_BOOTTIME
> > was reverted within 3 weeks. a3ed0e4393d6 ("Revert: Unify
> > CLOCK_MONOTONIC and CLOCK_BOOTTIME")
> > - CLOCK_MONOTONIC correctness (stops during the suspend) should be maintained.
> >
> > I agree with the points above. And, the current CLOCK_MONOTONIC
> > behavior in the KVM guest is not aligned with the statements above.
> > (it advances during the host's suspension.)
> > This causes the problems described above (triggering watchdog
> > timeouts, etc...) so my patches are going to fix this by 2 steps
> > roughly:
> > 1. Stopping the guest's clocks during the host's suspension
> > 2. Adjusting CLOCK_BOOTTIME later
> > This will make the clocks behave like the host does, not making
> > CLOCK_MONOTONIC behave like CLOCK_BOOTTIME.
> >
> > First one is a bit tricky since the guest can use a timestamp counter
> > in each CPUs (TSC in x86) and we need to adjust it without stale
> > values are observed by the guest kernel to prevent rewinding of
> > CLOCK_MONOTONIC (which is our top priority to make the kernel happy).
> > To achieve this, my patch adjusts TSCs (and a kvm-clock) before the
> > first vcpu runs of each vcpus after the resume.
> >
> > Second one is relatively safe: since jumping CLOCK_BOOTTIME forward
> > can happen even before my patches when suspend/resume happens, and
> > that will not break the monotonicity of the clocks, we can do that
> > through IRQ.
> >
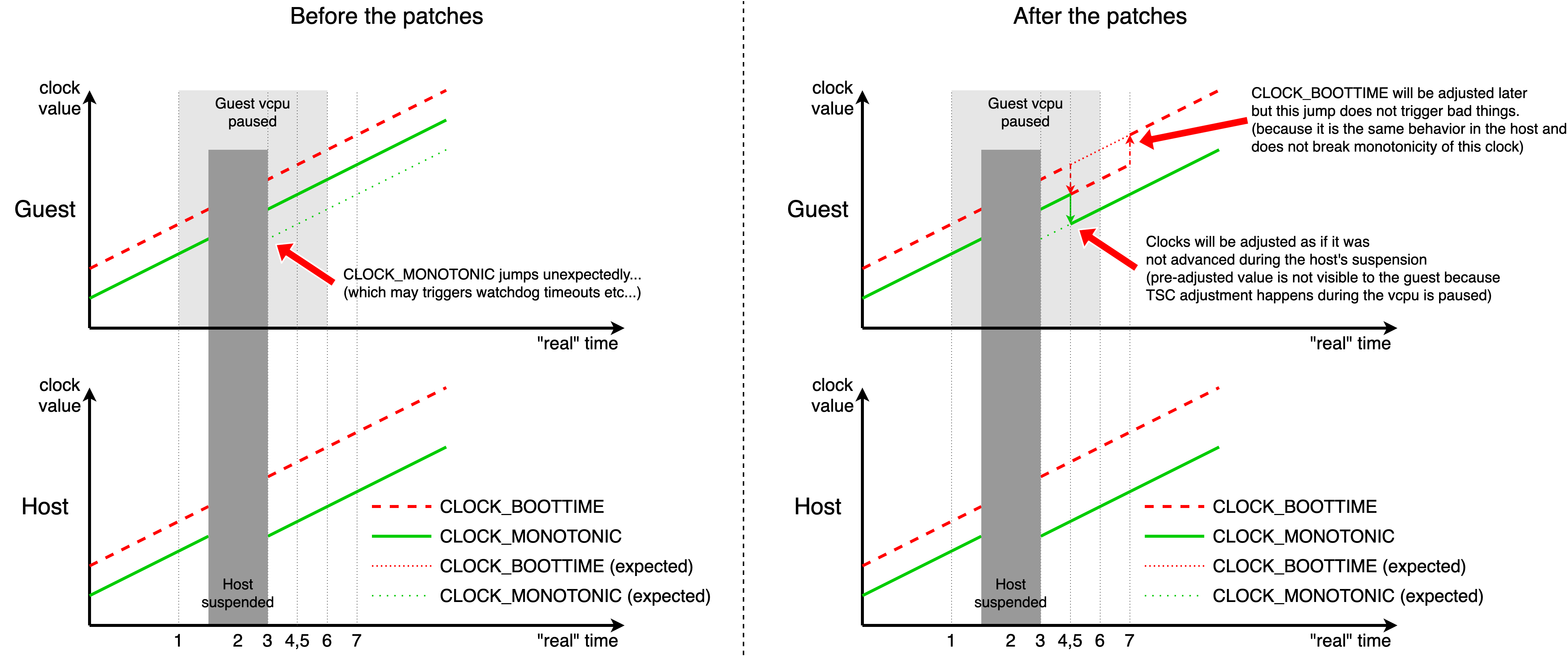
> > [1] shows the flow of the adjustment logic, and [2] shows how the
> > clocks behave in the guest and the host before/after my patches.
> > The numbers on each step in [1] corresponds to the timing shown in [2].
> > The left side of [2] is showing the behavior of the clocks before the
> > patches, and the right side shows after the patches. Also, upper
> > charts show the guest clocks, and bottom charts are host clocks.
> >
> > Before the patches(left side), CLOCK_MONOTONIC seems to be jumped from
> > the guest's perspective after the host's suspension. As Thomas says,
> > large jumps of CLOCK_MONOTONIC may lead to watchdog timeouts and other
> > bad things that we want to avoid.
> > With the patches(right side), both clocks will be adjusted (t=4,5) as
> > if they are stopped during the suspension. This adjustment is done by
> > the host side and invisible to the guest since it is done before the
> > first vcpu run after the resume. After that, CLOCK_BOOTTIME will be
> > adjusted from the guest side, triggered by the IRQ sent from the host.
> >
> > [1]: https://hikalium.com/files/kvm_virt_suspend_time_seq.png
> > [2]: https://hikalium.com/files/kvm_virt_suspend_time_clocks.png
>
> Thanks for the very detailed explanation. You obviously have though
> about this, and it makes sense.
>
> My worry is that this looks to be designed for the needs of Linux on
> x86, and does not match the reality of KVM on arm64, where there is no
> KVM clock (there is no need for it, and I have no plan to support it),
> and there is more than a single counter visible to the guest (at least
> two, and up to four with NV, all with various offsets). This also
> deals with concepts that are Linux-specific. How would it work for
> another (arbitrary) guest operating system?
Whether the architecture has a kvm-clock or not will not be a problem.
The high-level requirements for implementing this feature are:
- host hypervisor can adjust the offset of the virtualized hardware
clocks (tsc and kvm-clock in x86, generic timer in aarch64)
- host hypervisor can notify guest kernel about the host suspension
(interrupts etc.)
- host hypervisor can share the duration to be injected with the guest
(by shared memory or registers etc...)
so I believe it can be implemented on aarch64 as well.
This logic is only designed for Linux since the problem we want to
solve is linux specific.
(CLOCK_MONOTONIC vs CLOCK_BOOTTIME)
>
> Can we please take a step back and look at what we want to expose from
> a hypervisor PoV? It seems to me that all we want is:
>
> (1) tell the guest that time has moved forward
> (2) tell the guest by how much time has moved forward
>
> In a way, this isn't different from stolen time, only that it affects
> the whole VM and not just a single CPU (and for a much longer quantum
> of time).
>
(1) and (2) in the above may be implemented out of the host kernel,
but there is another most important step (0) is existed:
(0) adjust the clocks to compensate for how much the clocks have
incremented over a period of suspension, *before* any vcpu resume.
(0) is not possible to be done from outside of the host kernel (as far
as I tried) since there is no way to ensure that we can do the
adjustment "before the first vcpu runs after the host's resume" in the
userland.
Suspending a VM from VMM before the host's suspend will not always
work, since we can't guarantee that the VMM stopped the VM before the
host kernel enters into suspend.
That's why we implemented this feature with a modification in the host side.
As described in the above, just telling the guest about the time has
moved forward is not enough to solve the problem (a large jump of
CLOCK_MONOTONIC forward after the host's suspension will happen, which
can cause bad things like watchdog timeouts etc...).
> How the event is handled by the guest (what it means for its clocks
> and all that) is a guest problem. Why should KVM itself adjust the
> counters? This goes against what the architecture specifies (the
> counter is in an always-on domain that keeps counting when suspended),
> and KVM must preserve the architectural guarantees instead of
> deviating from them.
>
The counters need to be adjusted by KVM because:
1. We cannot adjust the guest's CLOCK_MONOTONIC from the guest side
since it breaks its monotonicity.
2. The counters are used by the guest userland to provide a fast
interface to read the clocks (vdso)
so the only way to adjust the counters without breaking their
monotonicity is doing that adjustment outside of the guest.
Let's think about this in a different way... For VM migrations, TSC
offset can be modified since we need to adjust it.
My patches are doing a similar thing, maybe we can say our patches are
doing "VM migration on the timeline". In this perspective, the
architectural restriction from the guest side is not broken since we
can consider that the VM has been time-traveled forward.
> > > Assuming you solve these, you should model the guest memory access
> > > similarly to what we do for stolen time. As for injecting an
> > > interrupt, why can't this be a userspace thing?
> >
> > Since CLOCK_BOOTTIME is calculated by adding a gap
> > (tk->monotonic_to_boot) to CLOCK_MONOTONIC, and there are no way to
> > change the value from the outside of the guest kernel, we should
> > implement some mechanism in the kernel to adjust it.
> > (Actually, I tried to add a sysfs interface to modify the gap [3], but
> > I learned that that is not a good idea...)
>
> It is not what I was suggesting.
>
> My suggestion was to have a shared memory between the VMM and the
> guest again, similar to the way we handle stolen time), let the VMM
> expose the drift in this shared memory, and inject an interrupt from
> userspace to signify a wake-up. All this requires is that on suspend,
> you force the vcpus to exit. On resume, the VMM update the guest
> visible drift, posts an interrupt, and let things rip.
>
> This requires very minimal KVM support, and squarely places the logic
> in the guest. Why doesn't this work?
Is there a way to know the host is going to suspend from host'
userland applications?
If there is a way to do that, it may be possible to implement the
feature outside of KVM but my knowledge about the Linux kernel was not
enough to find out how to do that. I would really appreciate it if you
could tell me how to do that.
>
> Another question is maybe even more naive: on bare metal, we don't
> need any of this. The system suspends, resumes, and recovers well
> enough. Nobody hides anything, and yet everything works just fine.
> That's because the kernel knows it is being suspended, and it acts
> accordingly. It looks to me that there is some value in following the
> same principles, even if this means that the host suspend has to
> synchronise with the guest being suspended.
>
> Thanks,
>
> M.
>
> --
> Without deviation from the norm, progress is not possible.
Thank you,
--
Hikaru Nishida
{kind=link}
{kind=link}
