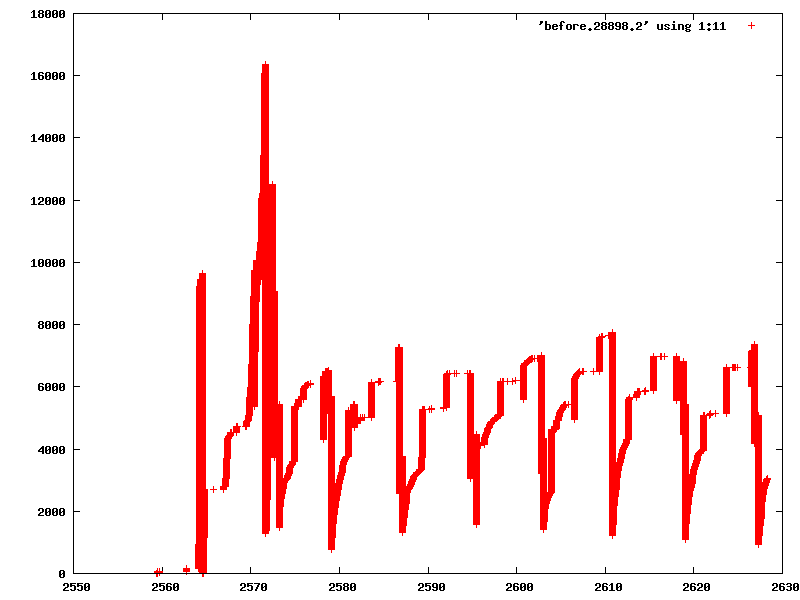
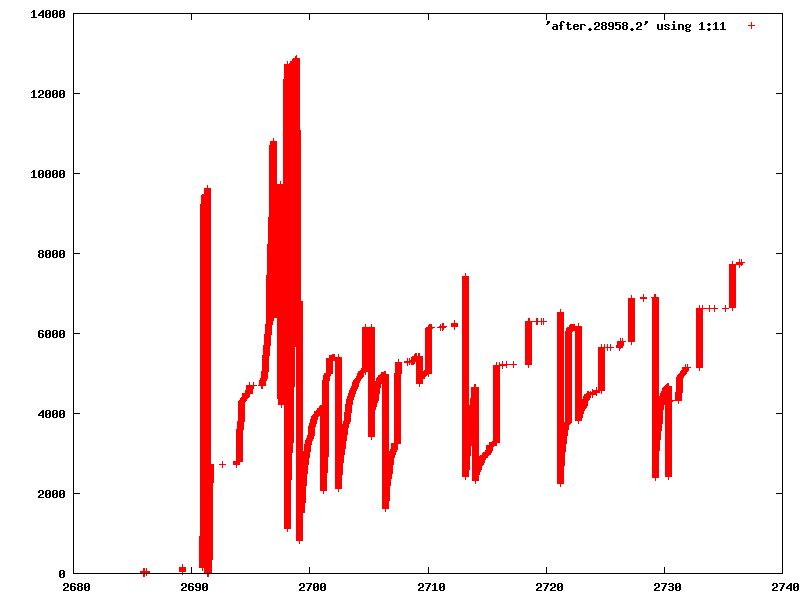
Hello, it seems to me that the reclaim mechanism for shadow page table pages is sub- optimal. The arch.active_mmu_pages list that is used for reclaiming does not move up parent shadow page tables when a child is added so when we need a new shadow page we zap the oldest - which can well be a directory level page holding a just added table level page. Attached is a proof-of-concept diff and two plots before and after. The plots show referenced guest pages over time. As you can see there is less saw- toothing in the after plot and also fewer changes overall (because we don't zap mappings that are still in use as often). This is with a limit of 64 for the shadow page table to increase the effect and vmx/ept. I realize that the list_move and parent walk are quite expensive and that kvm_mmu_alloc_page is only half the story. It should really be done every time a new guest page table is mapped - maybe via rmap_add. This would obviously completely kill performance-wise, though. Another idea would be to improve the reclaim logic in a way that it prefers "old" PT_PAGE_TABLE_LEVEL over directories. Though I'm not sure how to code that up sensibly, either. As I said, this is proof-of-concept and RFC. So any comments welcome. For my use case the proof-of-concept diff seems to do well enough, though. Thanks, -- /"\ Best regards, | mlaier@xxxxxxxxxxx \ / Max Laier | ICQ #67774661 X http://pf4freebsd.love2party.net/ | mlaier@EFnet / \ ASCII Ribbon Campaign | Against HTML Mail and News
Attachment:
before.png
Description: PNG image
Attachment:
after.png
Description: PNG image
diff --git a/arch/x86/kvm/mmu.c b/arch/x86/kvm/mmu.c
index 95d5329..0a63570 100644
--- a/arch/x86/kvm/mmu.c
+++ b/arch/x86/kvm/mmu.c
@@ -190,6 +190,8 @@ struct kvm_unsync_walk {
};
typedef int (*mmu_parent_walk_fn) (struct kvm_vcpu *vcpu, struct kvm_mmu_page *sp);
+static void mmu_parent_walk(struct kvm_vcpu *vcpu, struct kvm_mmu_page *sp,
+ mmu_parent_walk_fn fn);
static struct kmem_cache *pte_chain_cache;
static struct kmem_cache *rmap_desc_cache;
@@ -900,6 +902,12 @@ static unsigned kvm_page_table_hashfn(gfn_t gfn)
return gfn & ((1 << KVM_MMU_HASH_SHIFT) - 1);
}
+static int move_up_walk_fn(struct kvm_vcpu *vcpu, struct kvm_mmu_page *sp)
+{
+ list_move(&sp->link, &vcpu->kvm->arch.active_mmu_pages);
+ return 1;
+}
+
static struct kvm_mmu_page *kvm_mmu_alloc_page(struct kvm_vcpu *vcpu,
u64 *parent_pte)
{
@@ -918,6 +926,10 @@ static struct kvm_mmu_page *kvm_mmu_alloc_page(struct kvm_vcpu *vcpu,
bitmap_zero(sp->slot_bitmap, KVM_MEMORY_SLOTS + KVM_PRIVATE_MEM_SLOTS);
sp->multimapped = 0;
sp->parent_pte = parent_pte;
+#if 1
+ if (parent_pte)
+ mmu_parent_walk(vcpu, sp, move_up_walk_fn);
+#endif
--vcpu->kvm->arch.n_free_mmu_pages;
return sp;
}

{kind=link}
{kind=link}