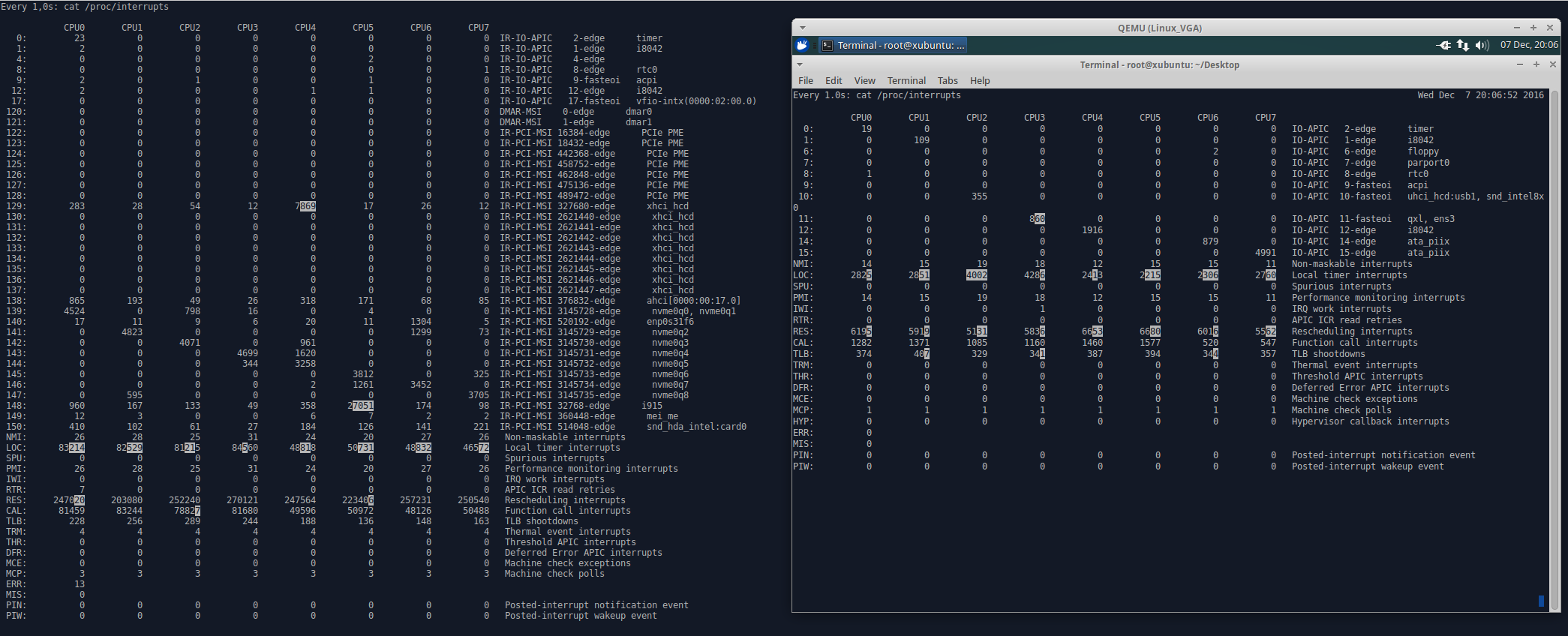
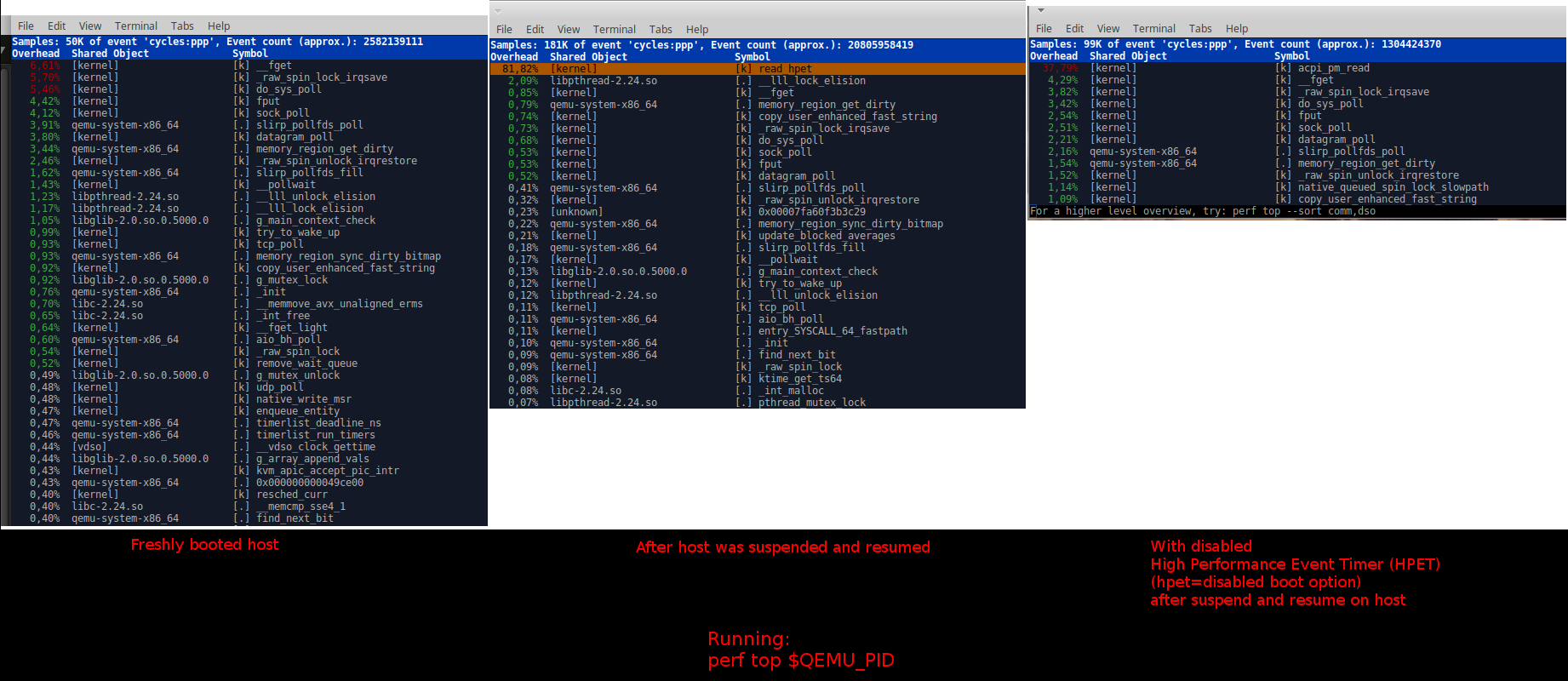
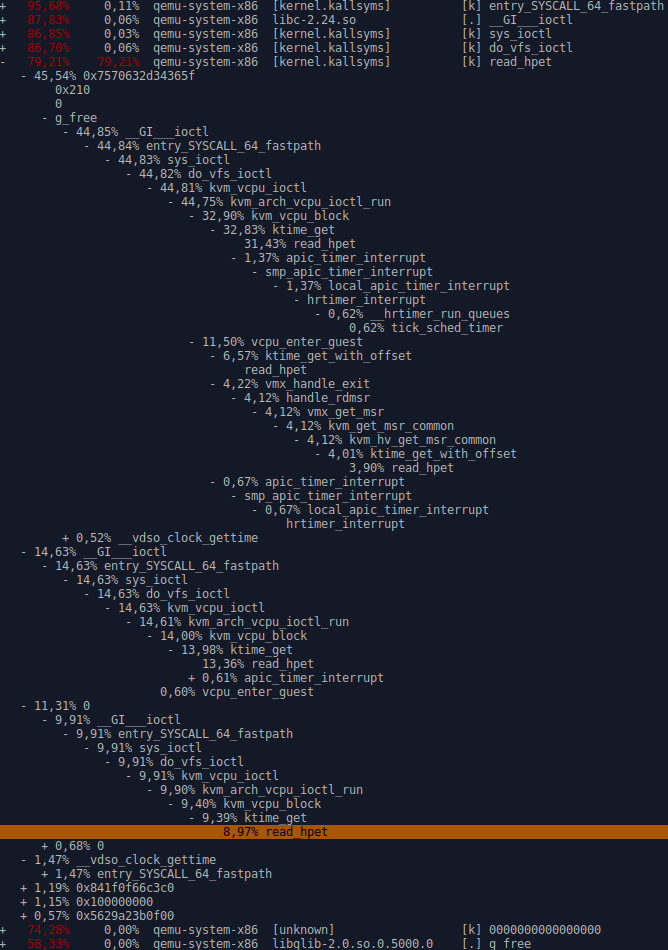
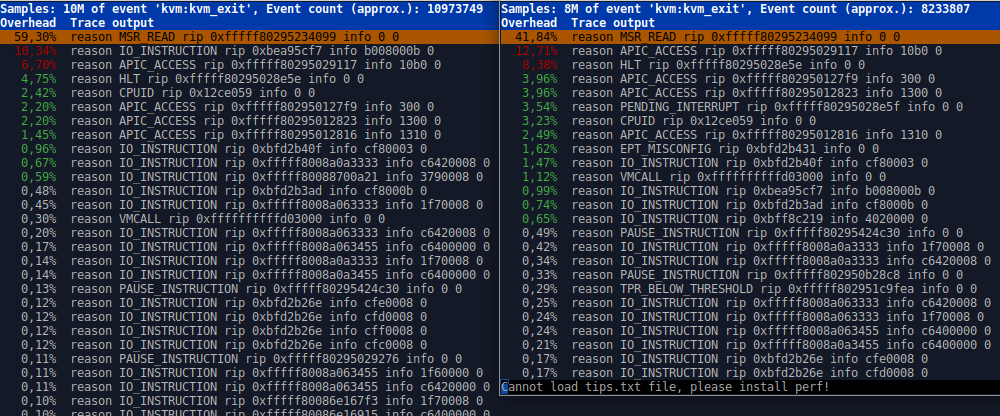
Following Stefan's suggestion I've investigated the possibility of potential problems with interrupts. Unfortunately, I can see no differences between both scenarios regarding the interrupt counter growth (c.f. https://evonide.com/images/qemu_proc_interrupts.png). After a short conversation with him I think we can exclude this as a problem source. Please let me know if you have any further advice how I should proceed further in order to triage this bug. On Wed, Dec 7, 2016 at 7:49 PM, Stefan Hajnoczi <stefanha@xxxxxxxxx> wrote: > On Sun, Dec 4, 2016 at 10:52 PM, Ruslan Habalov <3v0n1d3@xxxxxxxxx> wrote: >> Hi everyone, >> >> I'm having the following qemu issue since about February on Xubuntu. >> >> Steps to reproduce: >> 1) Boot host and boot qemu guest - everything works perfect >> 2) Shutdown qemu guest >> 3) Suspend host and resume host >> 4) Boot qemu guest again - the guest is now extremely slow >> >> Current system setup: >> host: kernel 4.8.0-27-generic (also reproducible with older kernel versions) >> qemu guest: Linux or Windows affected (tested both) >> >> I've tried to debug the issue on my own with the following results: >> ------------------------------------------------------------------------------------------------------------------------------ >> https://www.evonide.com/images/qemu_problem.png >> - This shows "perf top $QEMU_PID" from guest boot to shutdown for three >> different scenarios: >> Left: normal guest behavior after fresh boot of host system >> Middle: very slow guest after host was suspended and resumed >> Right: test run with disabled HPET (since I initially assumed some >> problems with HPET) >> >> https://www.evonide.com/images/qemu_hpet_investigation.png >> - Results of "perf record -g" and "perf report" >> According to stefanha (qemu IRC) this doesn't seem to indicate any error >> sources. >> >> https://www.evonide.com/images/qemu_vm_exit_healthy_vs_unhealthy.png >> - Results of running: "perf record -a -e kvm:kvm_exit" and "perf >> report" from guest boot to shutdown >> - Left: normal situation (after fresh host boot) >> - Right: bad situation (after suspend and resume on host and boot of >> qemu guest) >> There were ~300 out of order events reported by perf for the "bad" >> scenario (vs. only 2 for the "good" scenario). >> ------------------------------------------------------------------------------------------------------------------------------ >> I was also recommended to check the host timers (e.g. /proc/timer_list). >> However, this file has more than 800 lines and I am unsure what to look for. >> >> Please let me know if you need further information on this issue. > > Unfortunately I don't see an obvious pattern in the kvm_exit reasons. > Maybe someone on kvm@xxxxxxxxxxxxxxx can help, I have CCed the list. > > One idea that might explain the read_hpet trace you collected is an > interrupt storm. That means an interrupt is firing all the time > without doing useful work. This could explain why the vcpu keeps > halting (leading to many ktime_get() calls on the host). > > You can check the interrupt storm theory by collecting > /proc/interrupts on the host and inside the guest. If you compare the > healthy system against the slowed system there might be an obvious > difference in the interrupt counters. That would allow you to track > down which device keeps firing an interrupt. > > Stefan -- To unsubscribe from this list: send the line "unsubscribe kvm" in the body of a message to majordomo@xxxxxxxxxxxxxxx More majordomo info at http://vger.kernel.org/majordomo-info.html
{kind=link}
{kind=link}
{kind=link}
{kind=link}
