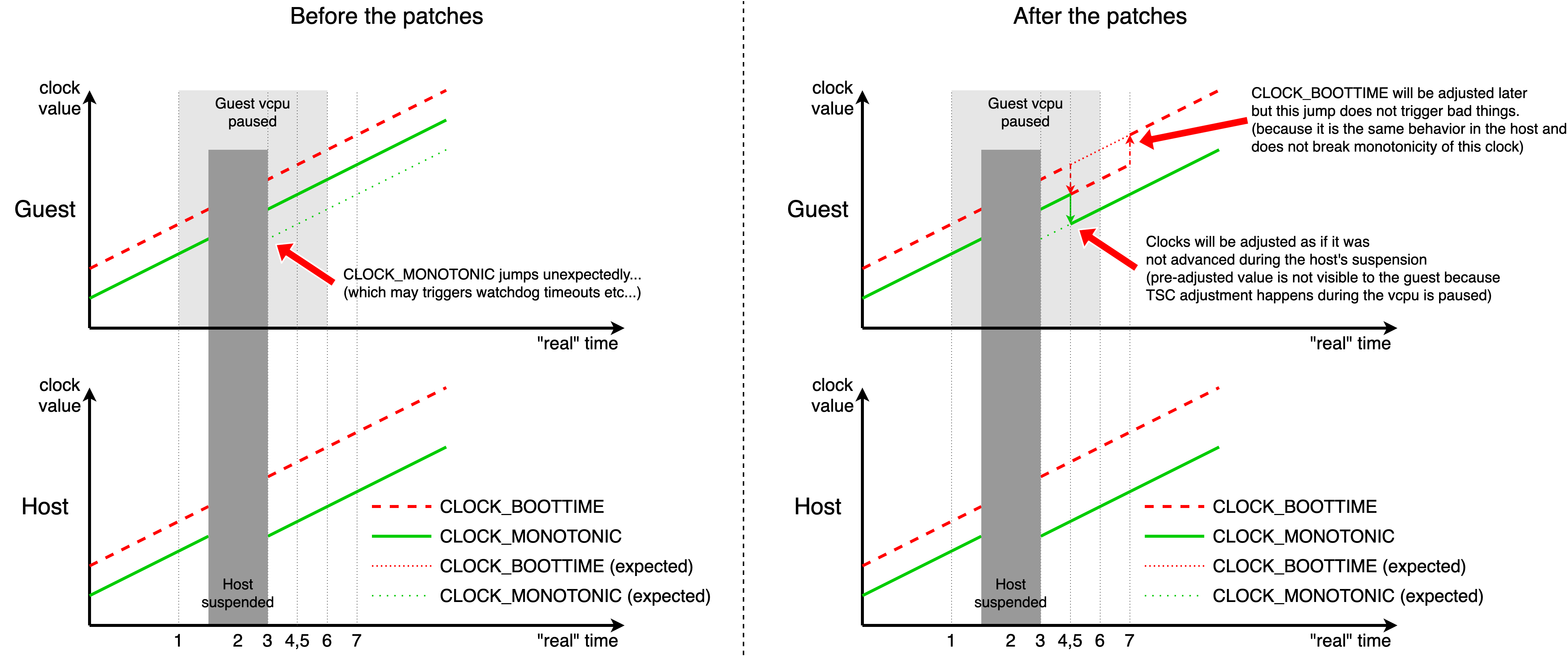
Hi Marc, Thanks for the comments! (Sorry for the late reply) On Wed, Oct 20, 2021 at 10:52 PM Marc Zyngier <maz@xxxxxxxxxx> wrote: > > Hi Hikaru, > > On Wed, 20 Oct 2021 13:04:25 +0100, > Hikaru Nishida <hikalium@xxxxxxxxxxxx> wrote: > > > > > > Hi, > > > > This patch series adds virtual suspend time injection support to KVM. > > It is an updated version of the following series: > > v2: > > https://lore.kernel.org/kvm/20210806100710.2425336-1-hikalium@xxxxxxxxxxxx/ > > v1: > > https://lore.kernel.org/kvm/20210426090644.2218834-1-hikalium@xxxxxxxxxxxx/ > > > > Please take a look again. > > > > To kvm/arm64 folks: > > I'm going to implement this mechanism to ARM64 as well but not > > sure which function should be used to make an IRQ (like kvm_apic_set_irq > > in x86) and if it is okay to use kvm_gfn_to_hva_cache / > > kvm_write_guest_cached for sharing the suspend duration. > > Before we discuss interrupt injection, I want to understand what this > is doing, and how this is doing it. And more precisely, I want to find > out how you solve the various problems described by Thomas here [1]. The problems described by Thomas in the thread was: - User space or kernel space can observe the stale timestamp before the adjustment - Moving CLOCK_MONOTONIC forward will trigger all sorts of timeouts, watchdogs, etc... - The last attempt to make CLOCK_MONOTONIC behave like CLOCK_BOOTTIME was reverted within 3 weeks. a3ed0e4393d6 ("Revert: Unify CLOCK_MONOTONIC and CLOCK_BOOTTIME") - CLOCK_MONOTONIC correctness (stops during the suspend) should be maintained. I agree with the points above. And, the current CLOCK_MONOTONIC behavior in the KVM guest is not aligned with the statements above. (it advances during the host's suspension.) This causes the problems described above (triggering watchdog timeouts, etc...) so my patches are going to fix this by 2 steps roughly: 1. Stopping the guest's clocks during the host's suspension 2. Adjusting CLOCK_BOOTTIME later This will make the clocks behave like the host does, not making CLOCK_MONOTONIC behave like CLOCK_BOOTTIME. First one is a bit tricky since the guest can use a timestamp counter in each CPUs (TSC in x86) and we need to adjust it without stale values are observed by the guest kernel to prevent rewinding of CLOCK_MONOTONIC (which is our top priority to make the kernel happy). To achieve this, my patch adjusts TSCs (and a kvm-clock) before the first vcpu runs of each vcpus after the resume. Second one is relatively safe: since jumping CLOCK_BOOTTIME forward can happen even before my patches when suspend/resume happens, and that will not break the monotonicity of the clocks, we can do that through IRQ. [1] shows the flow of the adjustment logic, and [2] shows how the clocks behave in the guest and the host before/after my patches. The numbers on each step in [1] corresponds to the timing shown in [2]. The left side of [2] is showing the behavior of the clocks before the patches, and the right side shows after the patches. Also, upper charts show the guest clocks, and bottom charts are host clocks. Before the patches(left side), CLOCK_MONOTONIC seems to be jumped from the guest's perspective after the host's suspension. As Thomas says, large jumps of CLOCK_MONOTONIC may lead to watchdog timeouts and other bad things that we want to avoid. With the patches(right side), both clocks will be adjusted (t=4,5) as if they are stopped during the suspension. This adjustment is done by the host side and invisible to the guest since it is done before the first vcpu run after the resume. After that, CLOCK_BOOTTIME will be adjusted from the guest side, triggered by the IRQ sent from the host. [1]: https://hikalium.com/files/kvm_virt_suspend_time_seq.png [2]: https://hikalium.com/files/kvm_virt_suspend_time_clocks.png > > Assuming you solve these, you should model the guest memory access > similarly to what we do for stolen time. As for injecting an > interrupt, why can't this be a userspace thing? Since CLOCK_BOOTTIME is calculated by adding a gap (tk->monotonic_to_boot) to CLOCK_MONOTONIC, and there are no way to change the value from the outside of the guest kernel, we should implement some mechanism in the kernel to adjust it. (Actually, I tried to add a sysfs interface to modify the gap [3], but I learned that that is not a good idea...) [3]: https://lore.kernel.org/lkml/87eehoax14.fsf@xxxxxxxxxxxxxxxxxxxxxxx/ Thank you, Hikaru Nishida > > Thanks, > > M. > > [1] https://lore.kernel.org/all/871r557jls.ffs@tglx > > > -- > Without deviation from the norm, progress is not possible. _______________________________________________ kvmarm mailing list kvmarm@xxxxxxxxxxxxxxxxxxxxx https://lists.cs.columbia.edu/mailman/listinfo/kvmarm
{kind=link}
{kind=link}
