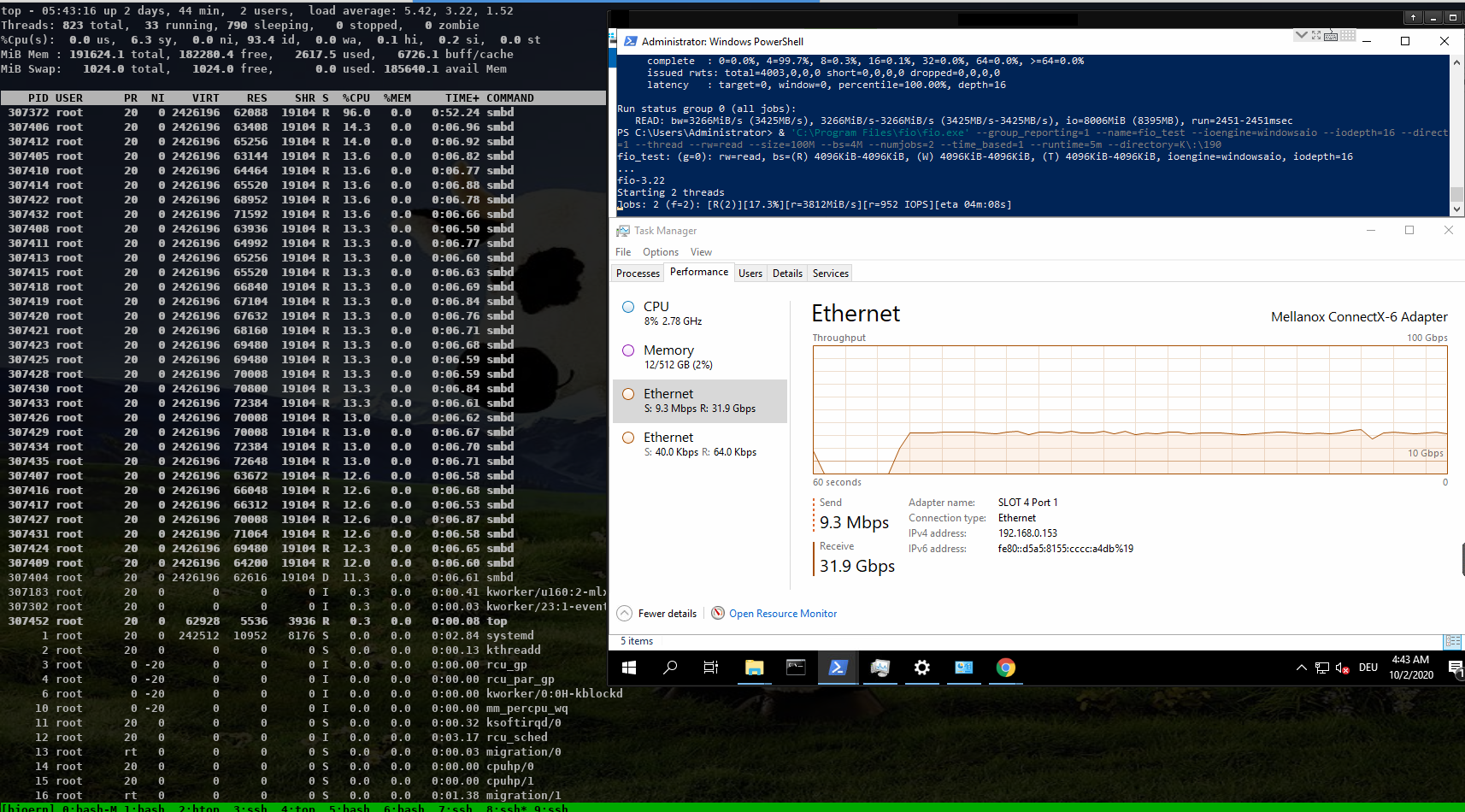
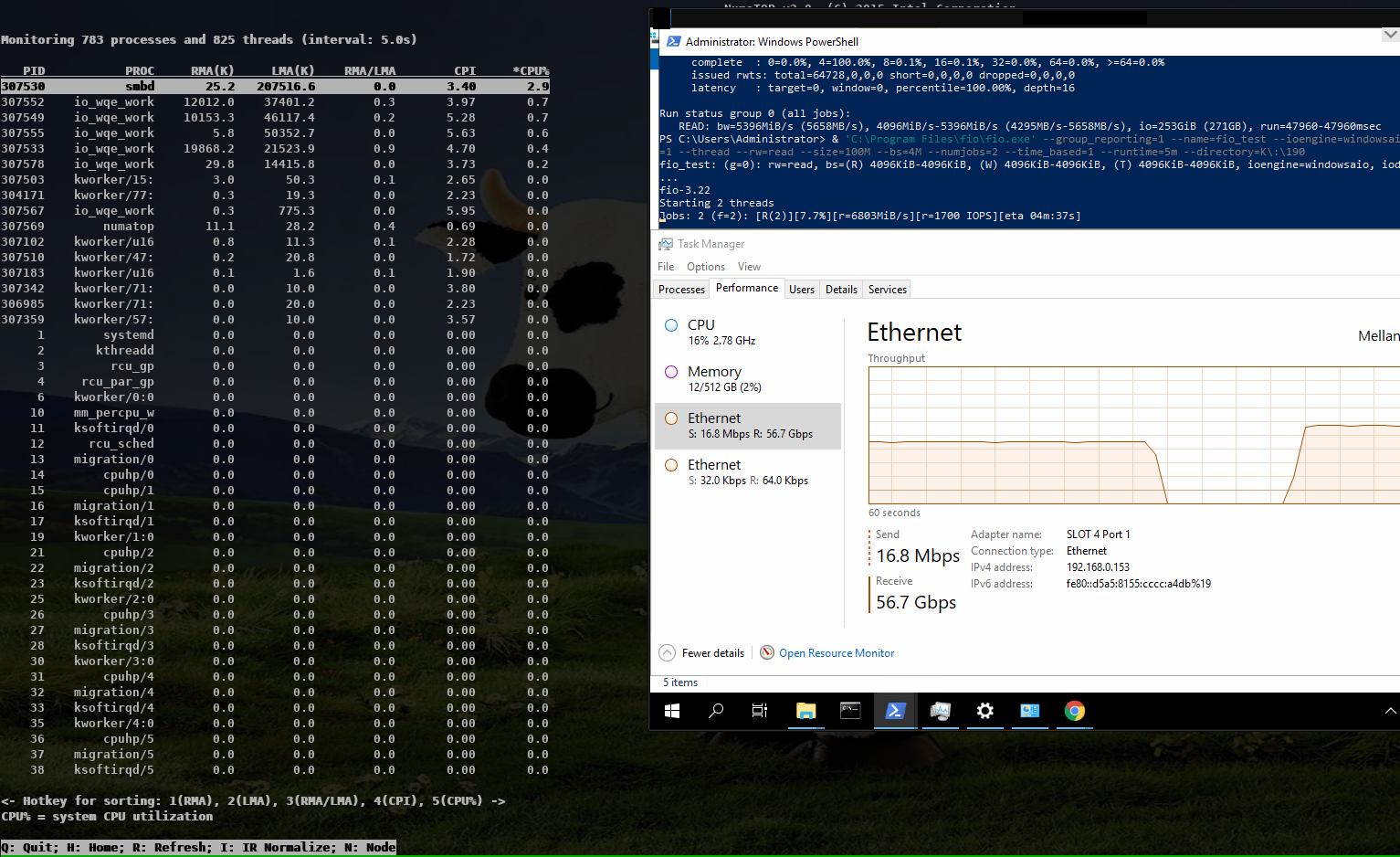
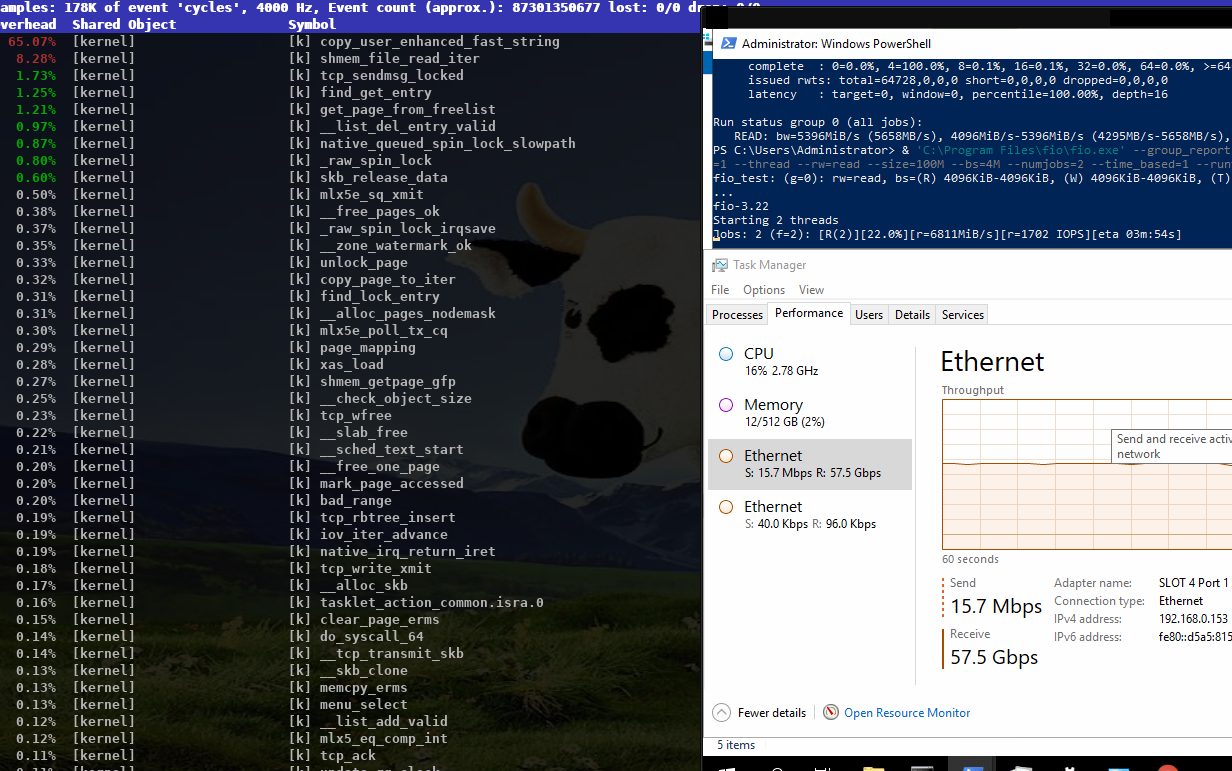
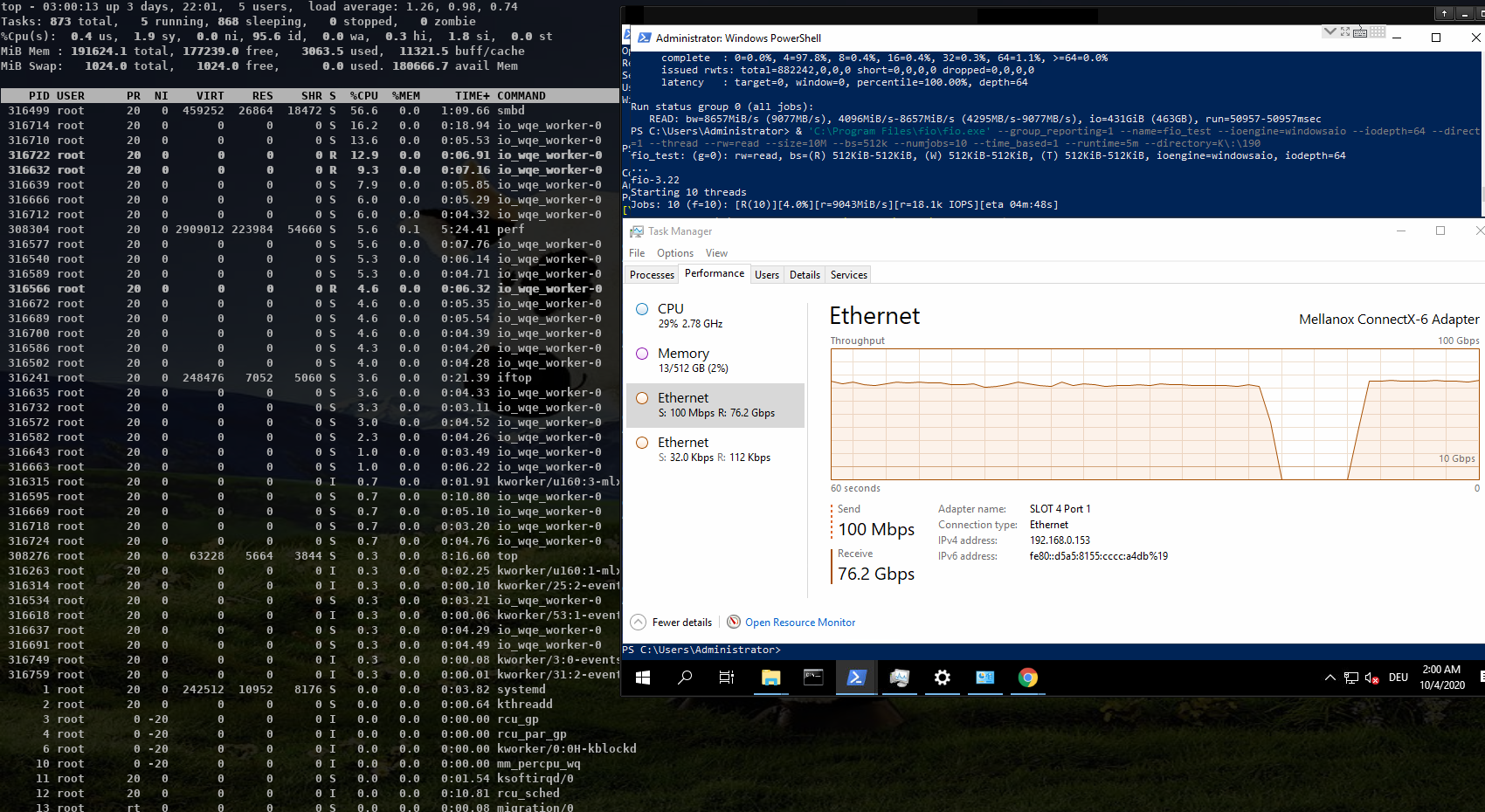
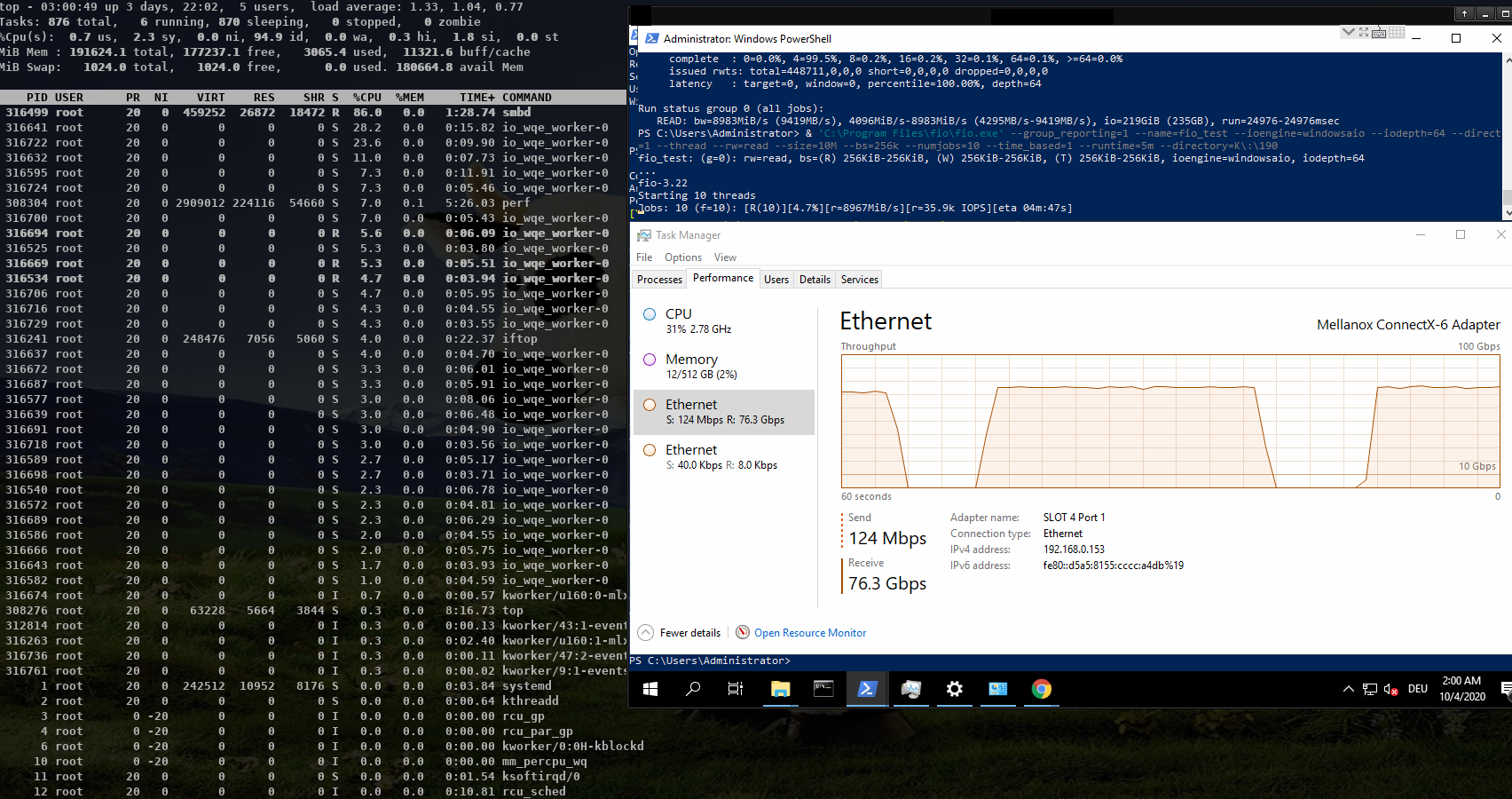
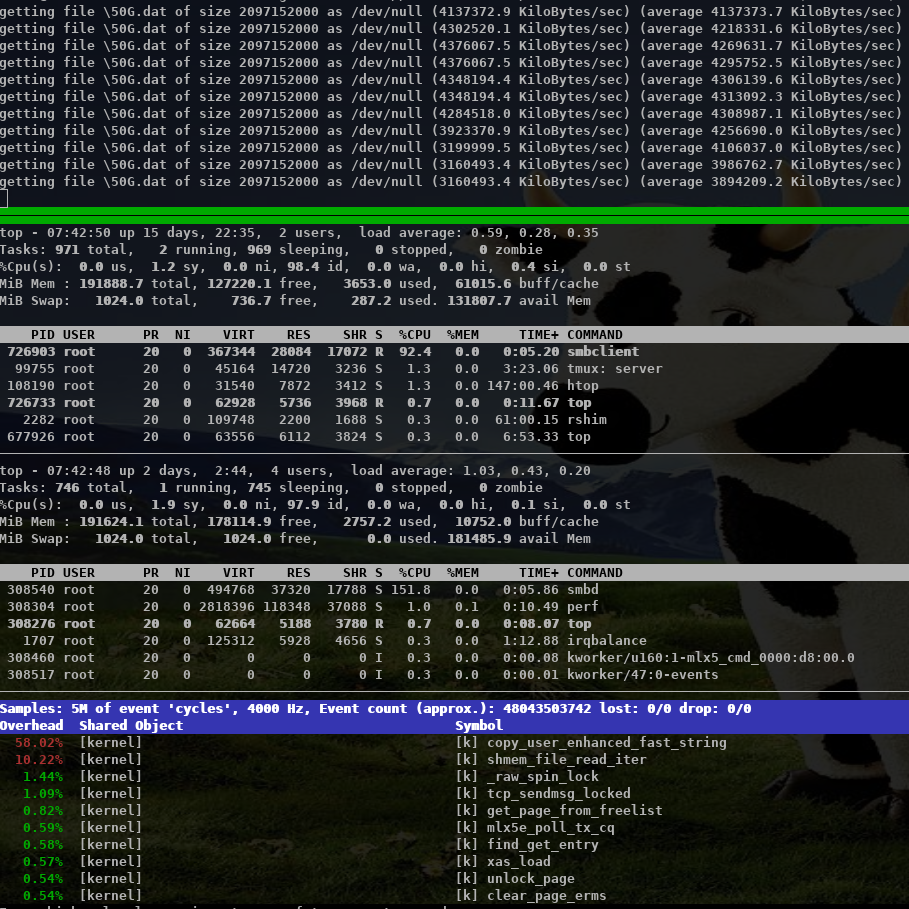
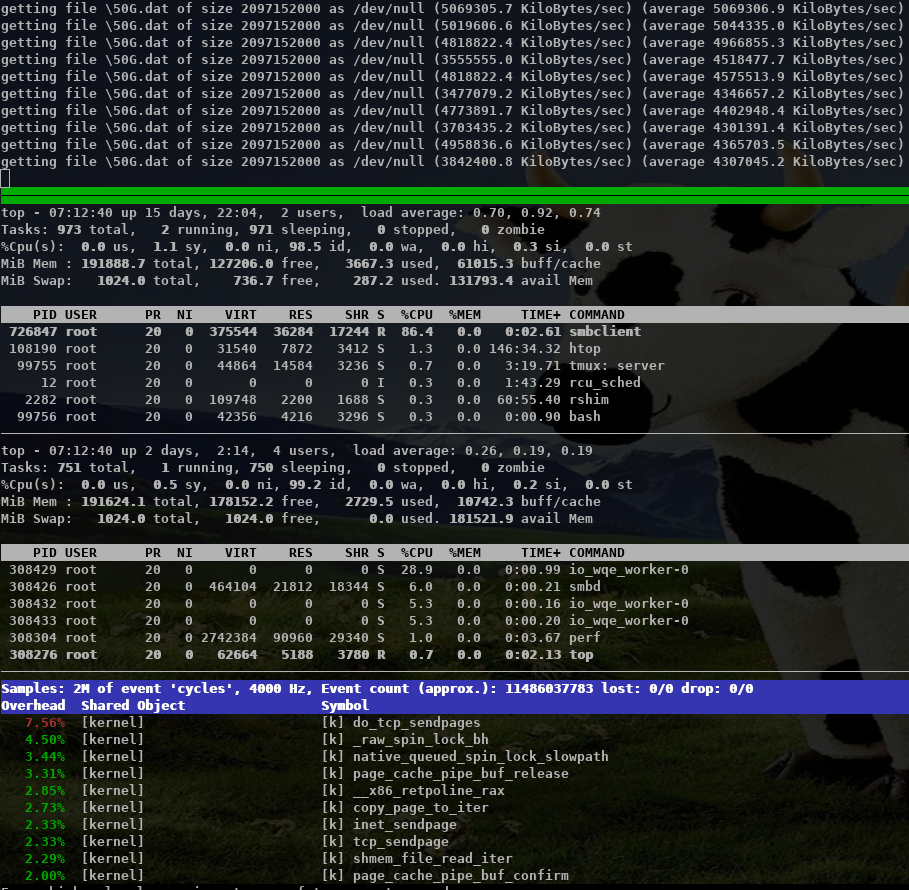
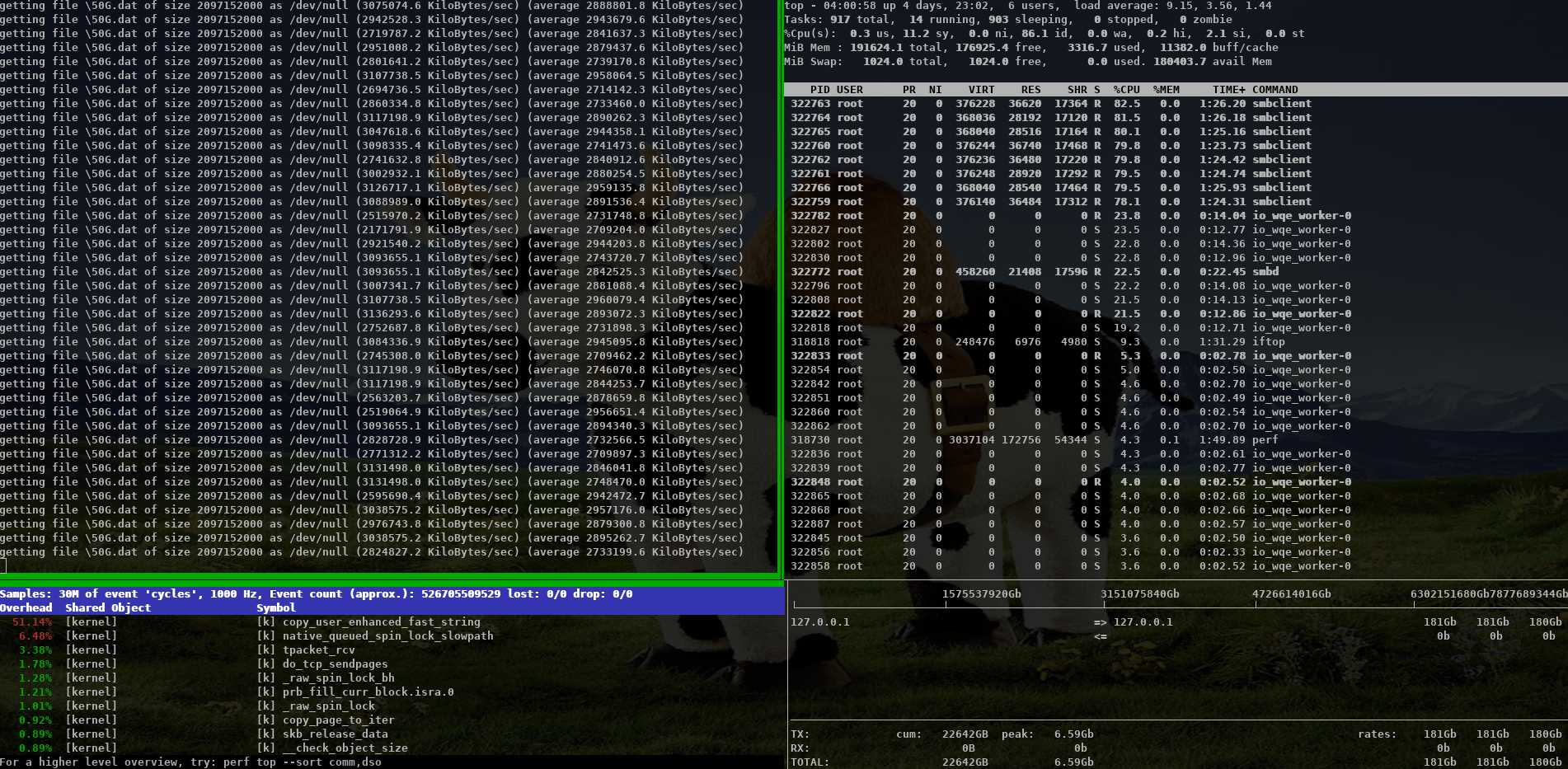
On Thu, Oct 15, 2020 at 11:58:00AM +0200, Stefan Metzmacher via samba-technical wrote: > Hi, > > related to my talk at the virtual storage developer conference > "multichannel / iouring Status Update within Samba" > (https://www.samba.org/~metze/presentations/2020/SDC/), > I have some additional updates. > > DDN was so kind to sponsor about a week of research on real world > hardware with 100GBit/s interfaces and two NUMA nodes per server. > > I was able to improve the performance drastically. > > I concentrated on SMB2 read performance, but similar improvements would be expected for write too. > > We used "server multi channel support = yes" and the network interface is RSS capable, > it means that a Windows client uses 4 connections by default. > > I first tested a share using /dev/shm and the results where really slow, > it was not possible to reach more than ~30 GBits/s on the net and ~ 3.8 GBytes/s > from fio.exe. > > smbd uses pread() from within a pthread based threadpool for file io > and sendmsg() to deliver the response to the socket. All multichannel > connections are served by the same smbd process (based on the client guid). > > The main smbd is cpu bound and the helper threads also use quite some cpu > about ~ 600% in total! > > https://www.samba.org/~metze/presentations/2020/SDC/future/read-32GBit-4M-2T-shm-sendmsg-top-02.png > > It turns out that NUMA access caused a lot of slow down. > The network adapter was connected to numa node 1, so we pinned > the ramdisk and smbd to that node. > > mount -t tmpfs -o size=60g,mpol=bind:1 tmpfs /dev/shm-numanode1 > numactl --cpunodebind=netdev:ens3f0 --membind=netdev:ens3f0 smbd > > With that it was possible to reach ~ 5 GBytes/s from fio.exe > > But the main problem remains the kernel is busy copying data > and sendmsg() takes up to 0.5 msecs, which means that we don't process new requests > during these 0.5 msecs. > > I created a prototype that uses IORING_OP_SENDMSG with IOSQE_ASYNC (I used a 5.8.12 kernel) > instead of the sync sendmsg() calls, which means that one kernel thread > (io_wqe_work ~50% cpu) per connection is doing the memory copy to the socket > and the main smbd only uses ~11% cpu, but we still use > 400% cpu in total. > > https://www.samba.org/~metze/presentations/2020/SDC/future/read-57GBit-4M-2T-shm-io-uring-sendmsg-async-top-02.png > > But it seems the numa binding for the io_wqe_work thread doesn't seem to work as expected, > so the results vary between 5.0 GBytes/s and 7.6 GBytes/s, depending on which numa node > io_wqe_work kernel threads are running. Also note that the threadpool with pread was > still faster than using IORING_OP_READV towards the filesystem, the reason might also > be numa dependent. > > https://www.samba.org/~metze/presentations/2020/SDC/future/read-57GBit-4M-2T-shm-io-uring-sendmsg-async-numatop-02.png > https://www.samba.org/~metze/presentations/2020/SDC/future/read-57GBit-4M-2T-shm-io-uring-sendmsg-async-perf-top-02.png > > The main problem is still copy_user_enhanced_fast_string, so I tried to use > IORING_IO_SPLICE (from the filesystem via a pipe to the socket) in order to avoid > copying memory around. > > With that I was able to reduce the cpu usage of the main smbd to ~6% cpu with > io_wqe_work threads using between ~3-6% cpu (filesystem to pipe) and > 6-30% cpu (pipe to socket). > > But the Windows client wasn't able to reach better numbers than 7.6 GBytes/s (65 GBits/s). > Only using "Set-SmbClientConfiguration -ConnectionCountPerRssNetworkInterface 16" helped to > get up to 8.9 GBytes/s (76 GBits/s). > > With 8 MByte IOs smbd is quite idle at ~ 5% cpu with the io_wqe_work threads ~100% cpu in total. > https://www.samba.org/~metze/presentations/2020/SDC/future/read-75GBit-8M-20T-RSS16-shm-io-uring-splice-top-02.png > > With 512 KByte IOs smbd uses ~56% cpu with the io_wqe_work threads ~130% cpu in total. > https://www.samba.org/~metze/presentations/2020/SDC/future/read-76GBit-512k-10T-RSS16-shm-io-uring-splice-02.png > > With 256 KByte IOS smbd uses ~87% cpu with the io_wqe_work threads ~180% cpu in total. > https://www.samba.org/~metze/presentations/2020/SDC/future/read-76GBit-256k-10T-RSS16-shm-io-uring-splice-02.png > > In order to get higher numbers I also tested with smbclient. > > - With the default configuration (sendmsg and threadpool pread) I was able to get > 4.2 GBytes/s over a single connection, while smbd with all threads uses ~150% cpu. > https://www.samba.org/~metze/presentations/2020/SDC/future/read-4.2G-smbclient-shm-sendmsg-pthread.png > > - With IORING_IO_SPLICE I was able to get 5 GBytes/s over a single connection, > while smbd uses ~ 6% cpu, with 2 io_wqe_work threads (filesystem to pipe) at 5.3% cpu each + > 1 io_wqe_work thread (pipe to socket) at ~29% cpu. This is only ~55% cpu in total on the server > and the client is the bottleneck here. > https://www.samba.org/~metze/presentations/2020/SDC/future/read-5G-smbclient-shm-io-uring-sendmsg-splice-async.png > > - With a modified smbclient using a forced client guid I used 4 connections into > a single smbd on the server. With that I was able to reach ~ 11 GBytes/s (92 GBits/s) > (This is similar to what 4 iperf instances are able to reach). > The main smbd uses 8.6 % cpu with 4 io_wqe_work threads (pipe to socket) at ~20% cpu each. > https://www.samba.org/~metze/presentations/2020/SDC/future/read-11G-smbclient-same-client-guid-shm-io-uring-splice-async.png > > - With 8 smbclient instances over loopback we are able to reach ~ 22 GBytes/s (180 GBits/s) > and smbd uses 22 % cpu. > https://www.samba.org/~metze/presentations/2020/SDC/future/read-22G-smbclient-8-same-client-guid-localhost-shm-io-uring-splice.png > > So IORING_IO_SPLICE will bring us into a very good shape for streaming reads. > Also note that numa pinning is not really needed here as the memory is not really touched at all. > > It's very likely that IORING_IO_RECVMSG in combination with IORING_IO_SPLICE would also improve the write path. > > Using AF_KCM socket (Kernel Connection Multiplexor) as wrapper to the > (TCP) stream socket might be able to avoid wakeups for incoming packets and > should allow better buffer management for incoming packets within smbd. > > The prototype/work in process patches are available here: > https://git.samba.org/?p=metze/samba/wip.git;a=shortlog;h=refs/heads/v4-13-multichannel > and > https://git.samba.org/?p=metze/samba/wip.git;a=shortlog;h=refs/heads/master-multichannel > > Also notice the missing generic multichannel things via this meta bug: > https://bugzilla.samba.org/show_bug.cgi?id=14534 > > I'm not sure when all this will be production ready, but it's great to know > the potential we have on a modern Linux kernel! > > Later SMB-Direct should be able to reduce the cpu load of the io_wqe_work threads (pipe to socket)... Fantastic results Metze, thanks a *LOT* for sharing this data and also the patches you used to reproduce. Cheers, Jeremy.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
