|
Hi everyone. For some time now, I've been plagued with a slow Gluster array.
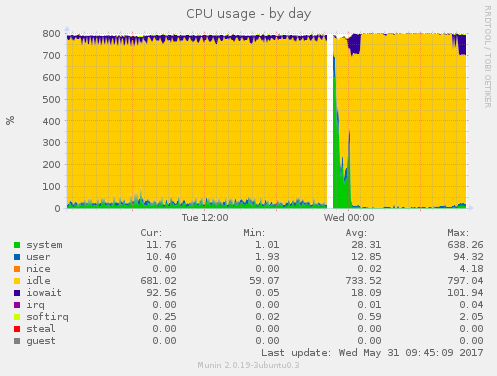
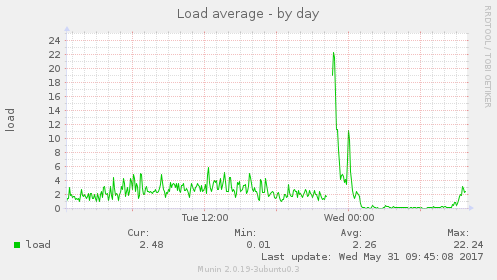
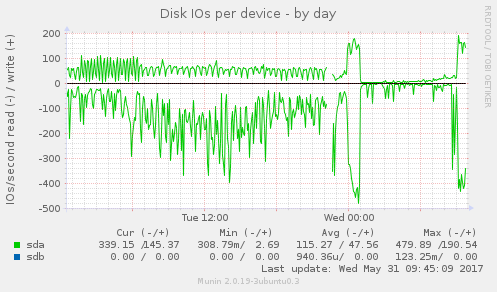
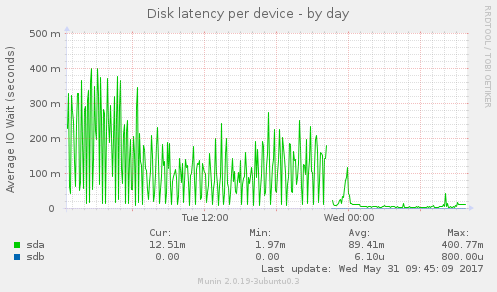
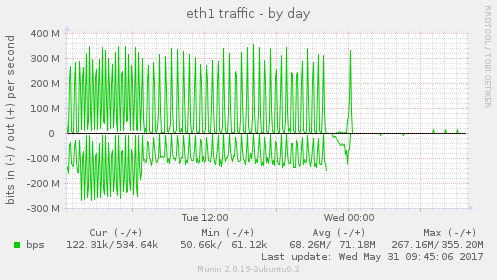
Metrics like disk utilization, disk latency, CPU usage, load
average, and eth1 traffic (the network device handling Gluster
synchronization), were all quite high. One of the servers in the
array had disk utilization pegged at 100% most of the time. This
caused quite a lot of slowness in our e-mail, especially webmail,
which keeps its data on the Gluster array. Then a funny thing happened. I needed to reboot two of the
servers in the array (NFS2 and NFS3, referenced later) to add more
disks in the RAID array to create a new Gluster brick. Rebooting
NFS2 had no trouble, and the situation did not change. Doing the
same to NFS3 on the other hand, performed three days later, was
different. First, before the reboot, I saw many kernel messages
like this in the console: After googling the error, it turns out it's indicating that the XFS filesystem needs to be defragged. I take note of the error and then reboot this second server. When it came back up, disk utilization, disk latency, CPU usage, load average and eth1 traffic all fell off a cliff and stayed that way. Webmail was running faster than ever the next morning. I do some more tests and research on the issue. XFS reported that file fragmentation was fairly high: I defragged NFS2 last night, it took about an hour, and now it
reports that fragmentation is only about 1.5%. But other people, especially in the Gluster mailing list, say
that XFS defragging isn't necessary unless the disk is nearly full
anyway. And what's up with Gluster behaving properly after this reboot? Why did rebooting NFS2 (which was actually the busier one, with the highest disk utilization) do nothing, but doing the same to NFS3 apparently fixed everything? Or was it defragging the disk? While it's nice that things are back to optimal operation, I need
to know why this is happening. |
Attachment:
cpu-day.png
Description: PNG image
Attachment:
load-day.png
Description: PNG image
Attachment:
diskstats_iops-day.png
Description: PNG image
Attachment:
diskstats_latency-day.png
Description: PNG image
Attachment:
if_eth1-day.png
Description: PNG image
_______________________________________________ Gluster-users mailing list Gluster-users@xxxxxxxxxxx http://lists.gluster.org/mailman/listinfo/gluster-users

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}