HI,
We have created a separate volume on SAN and it is mounted on Openstack controller node, there we have created multiple bricks on mounted location as folders.
Regards,
Chamara
On Tue, Jan 20, 2015 at 12:20 PM, Deepak Shetty <dpkshetty@xxxxxxxxx> wrote:
Just trying to understand the setup better....Do you use the mpathXX devices as bricks ? Whats the brick type (LV or dir) ?
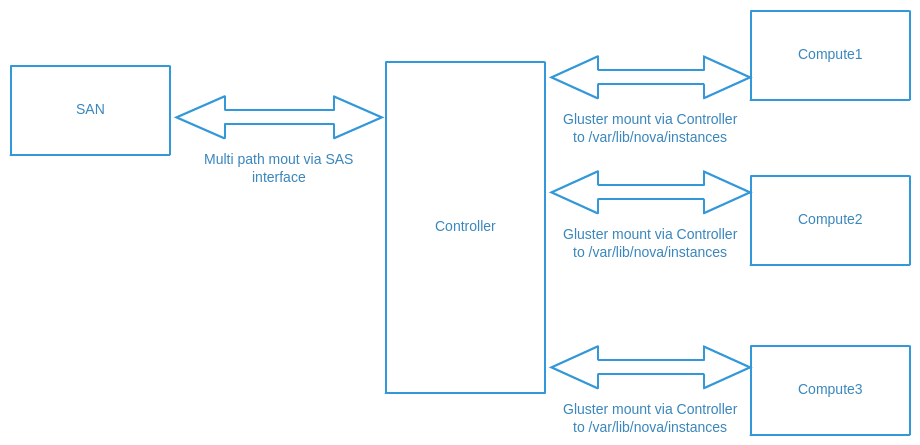
So you create the bricks on controller node and have the gluster volume present there ?On Tue, Jan 20, 2015 at 12:11 PM, chamara samarakoon <chthsa123@xxxxxxxxx> wrote:HI Deepak,Yes, it is Openstack controller and SAN is configured for redundancy through multi-path.Regards,Chamara--On Tue, Jan 20, 2015 at 11:55 AM, Deepak Shetty <dpkshetty@xxxxxxxxx> wrote:What does "Controller" mean, the openstack controller node or somethign else (like HBA ) ?You picture says its SAN but the text says multi-path mount.. SAN would mean block devices, so I am assuming you have redundant block devices on the compute host, mkfs'ing it and then creating bricks for gluster ?The stack trace looks like you hit a kernel bug and glusterfsd happens to be running on the CPU at the time... my 2 cents
thanx,
deepakOn Tue, Jan 20, 2015 at 11:29 AM, chamara samarakoon <chthsa123@xxxxxxxxx> wrote:_______________________________________________Hi All,We have setup Openstack cloud as below. And the "/va/lib/nova/instances" is a Gluster volume.CentOS - 6.5Kernel - 2.6.32-431.29.2.el6.x86_64GlusterFS - glusterfs 3.5.2 built on Jul 31 2014 18:47:54OpenStack - RDO using Packstack
Recently Controller node freezes with following error (Which required hard reboot), as a result Gluster volumes on compute node can not reach the controller and due to that all the instances on compute nodes become to read-only status which causes to restart all instances.BUG: scheduling while atomic : glusterfsd/42725/0xffffffffBUG: unable to handle kernel paging request at 0000000038a60d0a8IP: [<fffffffff81058e5d>] task_rq_lock+0x4d/0xa0PGD 1065525067 PUD 0Oops: 0000 [#1] SMPlast sysfs file : /sys/device/pci0000:80/0000:80:02.0/0000:86:00.0/host2/port-2:0/end_device-2:0/target2:0:0/2:0:0:1/stateCPU 0Modules linked in : xtconntrack iptable_filter ip_tables ipt_REDIRECT fuse ipv openvswitch vxlan iptable_manglePlease advice on above incident , also feedback on the Openstack + GlusterFS setup is appreciated.Thank You,Chamara
Gluster-users mailing list
Gluster-users@xxxxxxxxxxx
http://www.gluster.org/mailman/listinfo/gluster-userschthsa
chthsa
_______________________________________________ Gluster-users mailing list Gluster-users@xxxxxxxxxxx http://www.gluster.org/mailman/listinfo/gluster-users
