Hi,I am running a field trial of Gluster 3.5 on two servers. These two server use one 10k HDD each with XFS as a brick. On top of these bricks I have one replica 2 volume:
[root@nodef01i ~]# gluster volume info ph-fs-0 Volume Name: ph-fs-0 Type: Replicate Volume ID: 5085e018-7c47-4d4f-8dcb-cd89ec240393 Status: Started Number of Bricks: 1 x 2 = 2 Transport-type: tcp Bricks: Brick1: 10.11.100.1:/gfs/s3-sata-10k/brick Brick2: 10.11.100.2:/gfs/s3-sata-10k/brick Options Reconfigured: performance.io-thread-count: 12 network.ping-timeout: 2 performance.cache-max-file-size: 0 performance.flush-behind: onAdditionally I am running nagios to monitor everything where I use http://exchange.nagios.org/directory/Plugins/System-Metrics/File-System/GlusterFS-checks/details. I improved it slightly such that I monitor number of split-brain files and all this information go to the performance data, therefore I can draw pictures out of it (these pictures are in attachement).
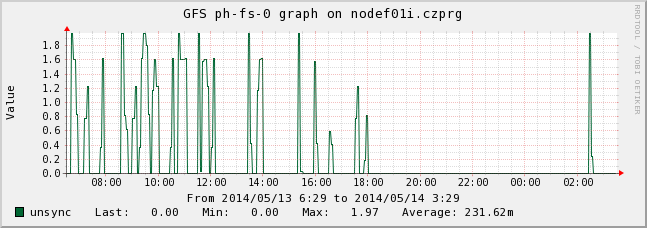
My problem is that I am receiving quite a lot of false warning from nagios during a day because there are some unsync files (gluster volume heal XXX info). I dont know if it is a bug or it is cause by my configuration. Either way it is quite disturbing and I am afraid that after receiving a lot false warning I could just omit an important one..
network.ping-timeout is set to 2, because I can not allow VM servers to hang for 2x42sec when other node is rebooted (we have some kind of reboot policy)..
Thanks for help, Milos
Attachment:
nodef01i.czprg-GFS ph-fs-0.png
Description: PNG image
Attachment:
nodef01i.czprg-GFS ph-fs-0-unsync.png
Description: PNG image
_______________________________________________ Gluster-users mailing list Gluster-users@xxxxxxxxxxx http://supercolony.gluster.org/mailman/listinfo/gluster-users

{kind=link}
{kind=link}