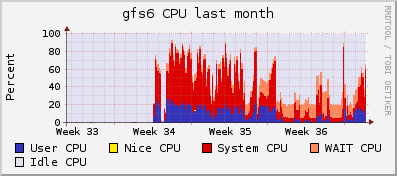
Venky, Just touching back with you to see where else I might want to look on this. The primary brick running the replication is still using a good deal of CPU though not quite what it was when the geo-rep was first started: [image: Inline image 2] You can see just above Week 34 when I started the geo-rep process. The major drop just before the words "Week 36" is when it stopped sending the initial data to the target. The replication target machine continues to slowly - very slowly - gain new data. Unfortunately I think it's only data that's been added recently. It doesn't appear to still be replicating the initial batch. That seems to have stopped right about 1TB total. I'm currently at 1.2 TB replicated and it's been over a week now since I eclipsed 1 TB. Would I do better to stop the process, wipe the geo-rep information from Gluster, do an rsync of the files to the destination and then start the geo-rep process again? On Fri, Sep 6, 2013 at 11:40 AM, Tony Maro <tonym at evrichart.com> wrote: > Correction: Different between the two local bricks is more likely a result > of the ZFS snapshot process I've run on the larger of them. > > > On Fri, Sep 6, 2013 at 11:39 AM, Tony Maro <tonym at evrichart.com> wrote: > >> More stats in case you need them: >> >> Grand total of the /data/docstore1 tree that's being sync'd is about 8.5 >> million files. >> About 1 KB of new data has appeared on the destination server since we >> started this discussion yesterday... >> >> >> tony at backup-ds2:~$ df >> Filesystem 1K-blocks Used Available Use% Mounted on >> /dev/sda1 768989240 1841364 728085452 1% / >> udev 16450080 4 16450076 1% /dev >> tmpfs 6583556 348 6583208 1% /run >> none 5120 0 5120 0% /run/lock >> none 16458888 0 16458888 0% /run/shm >> data 6601579264 0 6601579264 0% /data >> data/docstore1 7651735936 1050156672 6601579264 14% /data/docstore1 >> tony at backup-ds2:~$ date >> Thu Sep 5 09:36:24 EDT 2013 >> >> tony at backup-ds2:~$ df >> Filesystem 1K-blocks Used Available Use% Mounted on >> /dev/sda1 768989240 1842524 728084292 1% / >> udev 16450080 4 16450076 1% /dev >> tmpfs 6583556 348 6583208 1% /run >> none 5120 0 5120 0% /run/lock >> none 16458888 0 16458888 0% /run/shm >> data 6601577984 0 6601577984 0% /data >> data/docstore1 7651735808 1050157824 6601577984 14% /data/docstore1 >> tony at backup-ds2:~$ date >> Fri Sep 6 11:34:07 EDT 2013 >> tony at backup-ds2:~$ >> >> The source data I'm attempting to geo-replicate is 3.3 TB. Mirroring >> between the local bricks seems to be working fine. They are within 20KB of >> drive usage between each other for the /data/docstore1 partition. I >> attribute that to the new geo-rep info on gfs6 making it larger by a bit? >> Also the data is constantly changing, so maybe it's a bit of replication >> lag. >> >> >> >> On Fri, Sep 6, 2013 at 11:29 AM, Tony Maro <tonym at evrichart.com> wrote: >> >>> ./evds3 contains 1,262,970 files. No more than 255 files or folders per >>> subdirectory. >>> >>> Network latency is almost nonexistent - the servers are currently jacked >>> into the same switch on a separate network segment for the initial sync: >>> >>> tony at gfs6:~$ ping backup-ds2.gluster >>> PING backup-ds2.gluster (10.200.1.12) 56(84) bytes of data. >>> 64 bytes from backup-ds2.gluster (10.200.1.12): icmp_req=1 ttl=64 >>> time=0.245 ms >>> 64 bytes from backup-ds2.gluster (10.200.1.12): icmp_req=2 ttl=64 >>> time=0.197 ms >>> 64 bytes from backup-ds2.gluster (10.200.1.12): icmp_req=3 ttl=64 >>> time=0.174 ms >>> 64 bytes from backup-ds2.gluster (10.200.1.12): icmp_req=4 ttl=64 >>> time=0.221 ms >>> 64 bytes from backup-ds2.gluster (10.200.1.12): icmp_req=5 ttl=64 >>> time=0.163 ms >>> >>> >>> >>> >>> >>> On Fri, Sep 6, 2013 at 5:13 AM, Venky Shankar <yknev.shankar at gmail.com>wrote: >>> >>>> From the trace logs it looks like its still crawling (the lgetxattr() >>>> on the master and lgetxattr() on the slave). How many files are under './evds3' >>>> ? >>>> >>>> Further more, what's the latency b/w the two sites? >>>> >>>> >>>> On Thu, Sep 5, 2013 at 11:31 PM, Tony Maro <tonym at evrichart.com> wrote: >>>> >>>>> No rsync process is running. I tested for it several times over 10 >>>>> seconds. >>>>> >>>>> Here's the trace on feedback. I put it on TinyPaste instead of in >>>>> everyone's inbox out of courtesy: http://tny.cz/505b09c8 >>>>> >>>>> Thanks, >>>>> Tony >>>>> >>>>> >>>>> On Thu, Sep 5, 2013 at 12:24 PM, Venky Shankar < >>>>> yknev.shankar at gmail.com> wrote: >>>>> >>>>>> So, nothing fishy in slave logs too. >>>>>> >>>>>> Debugging this would need more information. Lets start with: >>>>>> >>>>>> 1. Is there any rsync process that is running? (ps auxww | grep rsync) >>>>>> >>>>>> 2. I would need strace logs for the worker process (the process which >>>>>> scans the filesystem and invokes rsync to transfer data). Something like >>>>>> this would do: >>>>>> >>>>>> - get the pid of the worker process >>>>>> # ps auxww | grep feedback (a gsyncd.py python process) >>>>>> >>>>>> - trace the pid above >>>>>> # strace -s 500 -o /tmp/worker.log -f -p <pid> >>>>>> >>>>>> Let the trace run for about 20 seconds. Lets see what's in >>>>>> /tmp/worker.log >>>>>> >>>>>> Thanks, >>>>>> -venky >>>>>> >>>>>> >>>>>> On Thu, Sep 5, 2013 at 7:56 PM, Tony Maro <tonym at evrichart.com>wrote: >>>>>> >>>>>>> Looks like the slave stopped logging things just before the sending >>>>>>> brick did: >>>>>>> >>>>>>> [2013-09-01 14:56:45.13972] I [gsyncd(slave):354:main_i] <top>: >>>>>>> syncing: file:///data/docstore1 >>>>>>> [2013-09-01 14:56:45.15433] I [resource(slave):453:service_loop] >>>>>>> FILE: slave listening >>>>>>> [2013-09-01 15:57:34.592938] I [repce(slave):78:service_loop] >>>>>>> RepceServer: terminating on reaching EOF. >>>>>>> [2013-09-01 15:57:34.593383] I [syncdutils(slave):142:finalize] >>>>>>> <top>: exiting. >>>>>>> [2013-09-01 15:57:45.374301] I [gsyncd(slave):354:main_i] <top>: >>>>>>> syncing: file:///data/docstore1 >>>>>>> [2013-09-01 15:57:45.375871] I [resource(slave):453:service_loop] >>>>>>> FILE: slave listening >>>>>>> [2013-09-01 16:02:09.115976] I [repce(slave):78:service_loop] >>>>>>> RepceServer: terminating on reaching EOF. >>>>>>> [2013-09-01 16:02:09.116446] I [syncdutils(slave):142:finalize] >>>>>>> <top>: exiting. >>>>>>> [2013-09-01 16:02:19.869340] I [gsyncd(slave):354:main_i] <top>: >>>>>>> syncing: file:///data/docstore1 >>>>>>> [2013-09-01 16:02:19.870598] I [resource(slave):453:service_loop] >>>>>>> FILE: slave listening >>>>>>> [2013-09-01 16:32:58.701617] I [repce(slave):78:service_loop] >>>>>>> RepceServer: terminating on reaching EOF. >>>>>>> [2013-09-01 16:32:58.702126] I [syncdutils(slave):142:finalize] >>>>>>> <top>: exiting. >>>>>>> [2013-09-01 16:33:09.456556] I [gsyncd(slave):354:main_i] <top>: >>>>>>> syncing: file:///data/docstore1 >>>>>>> [2013-09-01 16:33:09.458009] I [resource(slave):453:service_loop] >>>>>>> FILE: slave listening >>>>>>> [2013-09-01 21:47:13.442514] I [repce(slave):78:service_loop] >>>>>>> RepceServer: terminating on reaching EOF. >>>>>>> [2013-09-01 21:47:13.442899] I [syncdutils(slave):142:finalize] >>>>>>> <top>: exiting. >>>>>>> [2013-09-01 21:47:24.240978] I [gsyncd(slave):354:main_i] <top>: >>>>>>> syncing: file:///data/docstore1 >>>>>>> [2013-09-01 21:47:24.242424] I [resource(slave):453:service_loop] >>>>>>> FILE: slave listening >>>>>>> [2013-09-02 02:12:14.26339] I [repce(slave):78:service_loop] >>>>>>> RepceServer: terminating on reaching EOF. >>>>>>> [2013-09-02 02:12:14.26809] I [syncdutils(slave):142:finalize] >>>>>>> <top>: exiting. >>>>>>> [2013-09-02 02:12:24.818355] I [gsyncd(slave):354:main_i] <top>: >>>>>>> syncing: file:///data/docstore1 >>>>>>> [2013-09-02 02:12:24.820008] I [resource(slave):453:service_loop] >>>>>>> FILE: slave listening >>>>>>> [2013-09-02 02:16:14.525187] I [repce(slave):78:service_loop] >>>>>>> RepceServer: terminating on reaching EOF. >>>>>>> [2013-09-02 02:16:14.525675] I [syncdutils(slave):142:finalize] >>>>>>> <top>: exiting. >>>>>>> [2013-09-02 02:16:25.263712] I [gsyncd(slave):354:main_i] <top>: >>>>>>> syncing: file:///data/docstore1 >>>>>>> [2013-09-02 02:16:25.265168] I [resource(slave):453:service_loop] >>>>>>> FILE: slave listening >>>>>>> [2013-09-02 02:37:39.315608] I [repce(slave):78:service_loop] >>>>>>> RepceServer: terminating on reaching EOF. >>>>>>> [2013-09-02 02:37:39.316071] I [syncdutils(slave):142:finalize] >>>>>>> <top>: exiting. >>>>>>> [2013-09-02 02:37:50.78136] I [gsyncd(slave):354:main_i] <top>: >>>>>>> syncing: file:///data/docstore1 >>>>>>> [2013-09-02 02:37:50.79577] I [resource(slave):453:service_loop] >>>>>>> FILE: slave listening >>>>>>> >>>>>>> >>>>>>> >>>>>>> >>>>>>> >>>>>>> On Thu, Sep 5, 2013 at 10:09 AM, Venky Shankar < >>>>>>> yknev.shankar at gmail.com> wrote: >>>>>>> >>>>>>>> Could you also provide the slave logs? (log location on the >>>>>>>> slave: /var/log/glusterfs/geo-replication-slaves) >>>>>>>> >>>>>>>> Thanks, >>>>>>>> -venky >>>>>>>> >>>>>>>> >>>>>>>> On Thu, Sep 5, 2013 at 7:29 PM, Tony Maro <tonym at evrichart.com>wrote: >>>>>>>> >>>>>>>>> I'm trying to create a new Geo-Rep of about 3 TB of data >>>>>>>>> currently stored in a 2 brick mirror config. Obviously the geo-rep >>>>>>>>> destination is a third server. >>>>>>>>> >>>>>>>>> This is my 150th attempt. Okay, maybe not that far, but it's >>>>>>>>> pretty darn bad. >>>>>>>>> >>>>>>>>> Replication works fine until I hit around 1TB of data sync'd, then >>>>>>>>> it just stalls. For the past two days it hasn't gone past 1050156672 bytes >>>>>>>>> sync'd to the destination server. >>>>>>>>> >>>>>>>>> I did some digging in the logs and it looks like the brick that's >>>>>>>>> running the geo-rep process thinks it's syncing: >>>>>>>>> >>>>>>>>> [2013-09-05 09:45:37.354831] D [master:386:crawl] GMaster: syncing >>>>>>>>> ./evds3/Sky_Main_66/00/00/08/00000863.enc ... >>>>>>>>> [2013-09-05 09:45:37.358669] D [master:386:crawl] GMaster: syncing >>>>>>>>> ./evds3/Sky_Main_66/00/00/08/0000083b.enc ... >>>>>>>>> [2013-09-05 09:45:37.362251] D [master:386:crawl] GMaster: syncing >>>>>>>>> ./evds3/Sky_Main_66/00/00/08/0000087b.enc ... >>>>>>>>> [2013-09-05 09:45:37.366027] D [master:386:crawl] GMaster: syncing >>>>>>>>> ./evds3/Sky_Main_66/00/00/08/00000834.enc ... >>>>>>>>> [2013-09-05 09:45:37.369752] D [master:386:crawl] GMaster: syncing >>>>>>>>> ./evds3/Sky_Main_66/00/00/08/00000845.enc ... >>>>>>>>> [2013-09-05 09:45:37.373528] D [master:386:crawl] GMaster: syncing >>>>>>>>> ./evds3/Sky_Main_66/00/00/08/00000864.enc ... >>>>>>>>> [2013-09-05 09:45:37.377037] D [master:386:crawl] GMaster: syncing >>>>>>>>> ./evds3/Sky_Main_66/00/00/08/0000087f.enc ... >>>>>>>>> [2013-09-05 09:45:37.391432] D [master:386:crawl] GMaster: syncing >>>>>>>>> ./evds3/Sky_Main_66/00/00/08/00000897.enc ... >>>>>>>>> [2013-09-05 09:45:37.395059] D [master:386:crawl] GMaster: syncing >>>>>>>>> ./evds3/Sky_Main_66/00/00/08/00000829.enc ... >>>>>>>>> [2013-09-05 09:45:37.398725] D [master:386:crawl] GMaster: syncing >>>>>>>>> ./evds3/Sky_Main_66/00/00/08/00000816.enc ... >>>>>>>>> [2013-09-05 09:45:37.402559] D [master:386:crawl] GMaster: syncing >>>>>>>>> ./evds3/Sky_Main_66/00/00/08/000008cc.enc ... >>>>>>>>> [2013-09-05 09:45:37.406450] D [master:386:crawl] GMaster: syncing >>>>>>>>> ./evds3/Sky_Main_66/00/00/08/000008d2.enc ... >>>>>>>>> [2013-09-05 09:45:37.410310] D [master:386:crawl] GMaster: syncing >>>>>>>>> ./evds3/Sky_Main_66/00/00/08/000008df.enc ... >>>>>>>>> [2013-09-05 09:45:37.414344] D [master:386:crawl] GMaster: syncing >>>>>>>>> ./evds3/Sky_Main_66/00/00/08/000008bd.enc ... >>>>>>>>> [2013-09-05 09:45:37.438173] D [master:386:crawl] GMaster: syncing >>>>>>>>> ./evds3/Sky_Main_66/volume.info ... >>>>>>>>> [2013-09-05 09:45:37.441675] D [master:386:crawl] GMaster: syncing >>>>>>>>> ./evds3/Sky_Main_66/volume.enc ... >>>>>>>>> >>>>>>>>> But, *those files never appear on the destination server,*however the containing folders are there, just empty. >>>>>>>>> >>>>>>>>> Also, the other log file (...gluster.log) in the geo-replication >>>>>>>>> log folder that matches the destination stopped updating when the syncing >>>>>>>>> stopped apparently. It's last timestamp is from the 2nd, which is the last >>>>>>>>> time data transferred. >>>>>>>>> >>>>>>>>> The last bit from that log file is as such: >>>>>>>>> >>>>>>>>> >>>>>>>>> +------------------------------------------------------------------------------+ >>>>>>>>> [2013-09-02 06:37:50.109730] I [rpc-clnt.c:1654:rpc_clnt_reconfig] >>>>>>>>> 0-docstore1-client-1: changing port to 24009 (from 0) >>>>>>>>> [2013-09-02 06:37:50.109857] I [rpc-clnt.c:1654:rpc_clnt_reconfig] >>>>>>>>> 0-docstore1-client-0: changing port to 24009 (from 0) >>>>>>>>> [2013-09-02 06:37:54.097468] I >>>>>>>>> [client-handshake.c:1614:select_server_supported_programs] >>>>>>>>> 0-docstore1-client-1: Using Program GlusterFS 3.3.2, Num (1298437), Version >>>>>>>>> (330) >>>>>>>>> [2013-09-02 06:37:54.097973] I >>>>>>>>> [client-handshake.c:1411:client_setvolume_cbk] 0-docstore1-client-1: >>>>>>>>> Connected to 10.200.1.6:24009, attached to remote volume >>>>>>>>> '/data/docstore1'. >>>>>>>>> [2013-09-02 06:37:54.098005] I >>>>>>>>> [client-handshake.c:1423:client_setvolume_cbk] 0-docstore1-client-1: Server >>>>>>>>> and Client lk-version numbers are not same, reopening the fds >>>>>>>>> [2013-09-02 06:37:54.098094] I [afr-common.c:3685:afr_notify] >>>>>>>>> 0-docstore1-replicate-0: Subvolume 'docstore1-client-1' came back up; going >>>>>>>>> online. >>>>>>>>> [2013-09-02 06:37:54.098274] I >>>>>>>>> [client-handshake.c:453:client_set_lk_version_cbk] 0-docstore1-client-1: >>>>>>>>> Server lk version = 1 >>>>>>>>> [2013-09-02 06:37:54.098619] I >>>>>>>>> [client-handshake.c:1614:select_server_supported_programs] >>>>>>>>> 0-docstore1-client-0: Using Program GlusterFS 3.3.2, Num (1298437), Version >>>>>>>>> (330) >>>>>>>>> [2013-09-02 06:37:54.099191] I >>>>>>>>> [client-handshake.c:1411:client_setvolume_cbk] 0-docstore1-client-0: >>>>>>>>> Connected to 10.200.1.5:24009, attached to remote volume >>>>>>>>> '/data/docstore1'. >>>>>>>>> [2013-09-02 06:37:54.099222] I >>>>>>>>> [client-handshake.c:1423:client_setvolume_cbk] 0-docstore1-client-0: Server >>>>>>>>> and Client lk-version numbers are not same, reopening the fds >>>>>>>>> [2013-09-02 06:37:54.105891] I >>>>>>>>> [fuse-bridge.c:4191:fuse_graph_setup] 0-fuse: switched to graph 0 >>>>>>>>> [2013-09-02 06:37:54.106039] I >>>>>>>>> [client-handshake.c:453:client_set_lk_version_cbk] 0-docstore1-client-0: >>>>>>>>> Server lk version = 1 >>>>>>>>> [2013-09-02 06:37:54.106179] I [fuse-bridge.c:3376:fuse_init] >>>>>>>>> 0-glusterfs-fuse: FUSE inited with protocol versions: glusterfs 7.13 kernel >>>>>>>>> 7.17 >>>>>>>>> [2013-09-02 06:37:54.108766] I >>>>>>>>> [afr-common.c:2022:afr_set_root_inode_on_first_lookup] >>>>>>>>> 0-docstore1-replicate-0: added root inode >>>>>>>>> >>>>>>>>> >>>>>>>>> This is driving me nuts - I've been working on getting >>>>>>>>> Geo-Replication working for over 2 months now without any success. >>>>>>>>> >>>>>>>>> Status on the geo-rep shows OK: >>>>>>>>> >>>>>>>>> root at gfs6:~# gluster volume geo-replication docstore1 >>>>>>>>> ssh://root at backup-ds2.gluster:/data/docstore1 status >>>>>>>>> MASTER SLAVE >>>>>>>>> STATUS >>>>>>>>> >>>>>>>>> -------------------------------------------------------------------------------- >>>>>>>>> docstore1 ssh://root at backup-ds2.gluster:/data/docstore1 >>>>>>>>> OK >>>>>>>>> root at gfs6:~# >>>>>>>>> >>>>>>>>> Here's the config: >>>>>>>>> >>>>>>>>> root at gfs6:~# gluster volume geo-replication docstore1 >>>>>>>>> ssh://root at backup-ds2.gluster:/data/docstore1 config >>>>>>>>> log_level: DEBUG >>>>>>>>> gluster_log_file: >>>>>>>>> /var/log/glusterfs/geo-replication/docstore1/ssh%3A%2F%2Froot%4010.200.1.12%3Afile%3A%2F%2F%2Fdata%2Fdocstore1.gluster.log >>>>>>>>> ssh_command: ssh -oPasswordAuthentication=no >>>>>>>>> -oStrictHostKeyChecking=no -i /var/lib/glusterd/geo-replication/secret.pem >>>>>>>>> session_owner: 24f8c92d-723e-4513-9593-40ef4b7e766a >>>>>>>>> remote_gsyncd: /usr/lib/glusterfs/glusterfs/gsyncd >>>>>>>>> state_file: >>>>>>>>> /var/lib/glusterd/geo-replication/docstore1/ssh%3A%2F%2Froot%4010.200.1.12%3Afile%3A%2F%2F%2Fdata%2Fdocstore1.status >>>>>>>>> gluster_command_dir: /usr/sbin/ >>>>>>>>> pid_file: >>>>>>>>> /var/lib/glusterd/geo-replication/docstore1/ssh%3A%2F%2Froot%4010.200.1.12%3Afile%3A%2F%2F%2Fdata%2Fdocstore1.pid >>>>>>>>> log_file: >>>>>>>>> /var/log/glusterfs/geo-replication/docstore1/ssh%3A%2F%2Froot%4010.200.1.12%3Afile%3A%2F%2F%2Fdata%2Fdocstore1.log >>>>>>>>> gluster_params: xlator-option=*-dht.assert-no-child-down=true >>>>>>>>> root at gfs6:~# >>>>>>>>> >>>>>>>>> I'm running Ubuntu packages 3.3.2-ubuntu1-precise2 from the ppa. >>>>>>>>> Any ideas for why it's stalling? >>>>>>>>> >>>>>>>>> >>>>>>>>> _______________________________________________ >>>>>>>>> Gluster-users mailing list >>>>>>>>> Gluster-users at gluster.org >>>>>>>>> http://supercolony.gluster.org/mailman/listinfo/gluster-users >>>>>>>>> >>>>>>>> >>>>>>>> >>>>>>> >>>>>>> >>>>>>> -- >>>>>>> Thanks, >>>>>>> >>>>>>> *Tony Maro* >>>>>>> Chief Information Officer >>>>>>> EvriChart ? www.evrichart.com >>>>>>> Advanced Records Management >>>>>>> Office | 888.801.2020 ? 304.536.1290 >>>>>>> >>>>>>> >>>>>>> _______________________________________________ >>>>>>> Gluster-users mailing list >>>>>>> Gluster-users at gluster.org >>>>>>> http://supercolony.gluster.org/mailman/listinfo/gluster-users >>>>>>> >>>>>> >>>>>> >>>>> >>>>> >>>>> -- >>>>> Thanks, >>>>> >>>>> *Tony Maro* >>>>> Chief Information Officer >>>>> EvriChart ? www.evrichart.com >>>>> Advanced Records Management >>>>> Office | 888.801.2020 ? 304.536.1290 >>>>> >>>>> >>>> >>> >>> >>> -- >>> Thanks, >>> >>> *Tony Maro* >>> Chief Information Officer >>> EvriChart ? www.evrichart.com >>> Advanced Records Management >>> Office | 888.801.2020 ? 304.536.1290 >>> >>> >> >> >> -- >> Thanks, >> >> *Tony Maro* >> Chief Information Officer >> EvriChart ? www.evrichart.com >> Advanced Records Management >> Office | 888.801.2020 ? 304.536.1290 >> >> > > > -- > Thanks, > > *Tony Maro* > Chief Information Officer > EvriChart ? www.evrichart.com > Advanced Records Management > Office | 888.801.2020 ? 304.536.1290 > > -- Thanks, *Tony Maro* Chief Information Officer EvriChart ? www.evrichart.com Advanced Records Management Office | 888.801.2020 ? 304.536.1290 -------------- next part -------------- An HTML attachment was scrubbed... URL: <http://supercolony.gluster.org/pipermail/gluster-users/attachments/20130910/439d292e/attachment.html> -------------- next part -------------- A non-text attachment was scrubbed... Name: graphmonth.gif Type: image/gif Size: 12318 bytes Desc: not available URL: <http://supercolony.gluster.org/pipermail/gluster-users/attachments/20130910/439d292e/attachment.gif>
{kind=link}
