On Thu, Oct 3, 2013 at 8:57 AM, KueiHuan Chen <kueihuan.chen at gmail.com>wrote:
> Hi, Avati
>
> In your chained configuration, how to replace whole h1 without
> replace-brick ? Is there has a better way than replace brick in this
> situation ?
>
> h0:/b1 h1:/b2 h1:/b1 h2:/b2 h2:/b1 h0:/b2 (A new h3 want to replace old
> h1.)
>
You have a couple of options,
A)
replace-brick h1:/b1 h3:/b1
replace-brick h1:/b2 h3:/b2
and let self-heal bring the disks up to speed, or
B)
add-brick replica 2 h3:/b1 h2:/b2a
add-brick replica 2 h3:/b2 h0:/b1a
remove-brick h0:/b1 h1:/b2 start .. commit
remove-brick h2:/b2 h1:/b1 start .. commit
Let me know if you still have questions.
Avati
> Thanks.
> Best Regards,
>
> KueiHuan-Chen
> Synology Incorporated.
> Email: khchen at synology.com
> Tel: +886-2-25521814 ext.827
>
>
> 2013/9/30 Anand Avati <avati at gluster.org>:
> >
> >
> >
> > On Fri, Sep 27, 2013 at 1:56 AM, James <purpleidea at gmail.com> wrote:
> >>
> >> On Fri, 2013-09-27 at 00:35 -0700, Anand Avati wrote:
> >> > Hello all,
> >> Hey,
> >>
> >> Interesting timing for this post...
> >> I've actually started working on automatic brick addition/removal. (I'm
> >> planning to add this to puppet-gluster of course.) I was hoping you
> >> could help out with the algorithm. I think it's a bit different if
> >> there's no replace-brick command as you are proposing.
> >>
> >> Here's the problem:
> >> Given a logically optimal initial volume:
> >>
> >> volA: rep=2; h1:/b1 h2:/b1 h3:/b1 h4:/b1 h1:/b2 h2:/b2 h3:/b2 h4:/b2
> >>
> >> suppose I know that I want to add/remove bricks such that my new volume
> >> (if I had created it new) looks like:
> >>
> >> volB: rep=2; h1:/b1 h3:/b1 h4:/b1 h5:/b1 h6:/b1 h1:/b2 h3:/b2 h4:/b2
> >> h5:/b2 h6:/b2
> >>
> >> What is the optimal algorithm for determining the correct sequence of
> >> transforms that are needed to accomplish this task. Obviously there are
> >> some simpler corner cases, but I'd like to solve the general case.
> >>
> >> The transforms are obviously things like running the add-brick {...} and
> >> remove-brick {...} commands.
> >>
> >> Obviously we have to take into account that it's better to add bricks
> >> and rebalance before we remove bricks and risk the file system if a
> >> replica is missing. The algorithm should work for any replica N. We want
> >> to make sure the new layout makes sense to replicate the data on
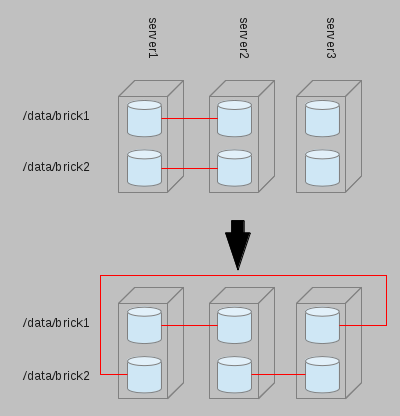
> >> different servers. In many cases, this will require creating a circular
> >> "chain" of bricks as illustrated in the bottom of this image:
> >> http://joejulian.name/media/uploads/images/replica_expansion.png
> >> for example. I'd like to optimize for safety first, and then time, I
> >> imagine.
> >>
> >> Many thanks in advance.
> >>
> >
> > I see what you are asking. First of all, when running a 2-replica volume
> you
> > almost pretty much always want to have an even number of servers, and add
> > servers in even numbers. Ideally the two "sides" of the replicas should
> be
> > placed in separate failures zones - separate racks with separate power
> > supplies or separate AZs in the cloud. Having an odd number of servers
> with
> > an 2 replicas is a very "odd" configuration. In all these years I am yet
> to
> > come across a customer who has a production cluster with 2 replicas and
> an
> > odd number of servers. And setting up replicas in such a chained manner
> > makes it hard to reason about availability, especially when you are
> trying
> > recover from a disaster. Having clear and separate "pairs" is definitely
> > what is recommended.
> >
> > That being said, nothing prevents one from setting up a chain like above
> as
> > long as you are comfortable with the complexity of the configuration. And
> > phasing out replace-brick in favor of add-brick/remove-brick does not
> make
> > the above configuration impossible either. Let's say you have a chained
> > configuration of N servers, with pairs formed between every:
> >
> > h(i):/b1 h((i+1) % N):/b2 | i := 0 -> N-1
> >
> > Now you add N+1th server.
> >
> > Using replace-brick, you have been doing thus far:
> >
> > 1. add-brick hN:/b1 h0:/b2a # because h0:/b2 was "part of a previous
> brick"
> > 2. replace-brick h0:/b2 hN:/b2 start ... commit
> >
> > In case you are doing an add-brick/remove-brick approach, you would now
> > instead do:
> >
> > 1. add-brick h(N-1):/b1a hN:/b2
> > 2. add-brick hN:/b1 h0:/b2a
> > 3. remove-brick h(N-1):/b1 h0:/b2 start ... commit
> >
> > You will not be left with only 1 copy of a file at any point in the
> process,
> > and achieve the same "end result" as you were with replace-brick. As
> > mentioned before, I once again request you to consider if you really
> want to
> > deal with the configuration complexity of having chained replication,
> > instead of just adding servers in pairs.
> >
> > Please ask if there are any more questions or concerns.
> >
> > Avati
> >
> >
> >>
> >> James
> >>
> >> Some comments below, although I'm a bit tired so I hope I said it all
> >> right.
> >>
> >> > DHT's remove-brick + rebalance has been enhanced in the last couple of
> >> > releases to be quite sophisticated. It can handle graceful
> >> > decommissioning
> >> > of bricks, including open file descriptors and hard links.
> >> Sweet
> >>
> >> >
> >> > This in a way is a feature overlap with replace-brick's data migration
> >> > functionality. Replace-brick's data migration is currently also used
> for
> >> > planned decommissioning of a brick.
> >> >
> >> > Reasons to remove replace-brick (or why remove-brick is better):
> >> >
> >> > - There are two methods of moving data. It is confusing for the users
> >> > and
> >> > hard for developers to maintain.
> >> >
> >> > - If server being replaced is a member of a replica set, neither
> >> > remove-brick nor replace-brick data migration is necessary, because
> >> > self-healing itself will recreate the data (replace-brick actually
> uses
> >> > self-heal internally)
> >> >
> >> > - In a non-replicated config if a server is getting replaced by a new
> >> > one,
> >> > add-brick <new> + remove-brick <old> "start" achieves the same goal as
> >> > replace-brick <old> <new> "start".
> >> >
> >> > - In a non-replicated config, <replace-brick> is NOT glitch free
> >> > (applications witness ENOTCONN if they are accessing data) whereas
> >> > add-brick <new> + remove-brick <old> is completely transparent.
> >> >
> >> > - Replace brick strictly requires a server with enough free space to
> >> > hold
> >> > the data of the old brick, whereas remove-brick will evenly spread out
> >> > the
> >> > data of the bring being removed amongst the remaining servers.
> >>
> >> Can you talk more about the replica = N case (where N is 2 or 3?)
> >> With remove brick, add brick you will need add/remove N (replica count)
> >> bricks at a time, right? With replace brick, you could just swap out
> >> one, right? Isn't that a missing feature if you remove replace brick?
> >>
> >> >
> >> > - Replace-brick code is complex and messy (the real reason :p).
> >> >
> >> > - No clear reason why replace-brick's data migration is better in any
> >> > way
> >> > to remove-brick's data migration.
> >> >
> >> > I plan to send out patches to remove all traces of replace-brick data
> >> > migration code by 3.5 branch time.
> >> >
> >> > NOTE that replace-brick command itself will still exist, and you can
> >> > replace on server with another in case a server dies. It is only the
> >> > data
> >> > migration functionality being phased out.
> >> >
> >> > Please do ask any questions / raise concerns at this stage :)
> >> I heard with 3.4 you can somehow change the replica count when adding
> >> new bricks... What's the full story here please?
> >>
> >> Thanks!
> >> James
> >>
> >> >
> >> > Avati
> >> > _______________________________________________
> >> > Gluster-users mailing list
> >> > Gluster-users at gluster.org
> >> > http://supercolony.gluster.org/mailman/listinfo/gluster-users
> >>
> >
> >
> > _______________________________________________
> > Gluster-users mailing list
> > Gluster-users at gluster.org
> > http://supercolony.gluster.org/mailman/listinfo/gluster-users
>
-------------- next part --------------
An HTML attachment was scrubbed...
URL: <http://supercolony.gluster.org/pipermail/gluster-users/attachments/20131003/03146494/attachment.html>
{kind=link}
