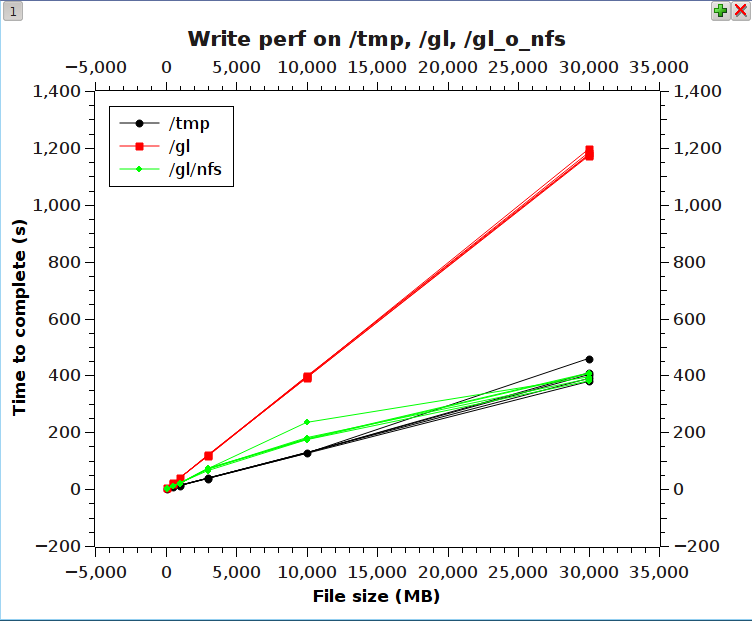
Hi Venky - thank for the link to this translator. I'll take a look at it, but right now, we don't have too much trouble with reads - it's the 'zillions of tiny writes' problem that's hosing us and the NFS solution gives us a bit more headroom. We'll be moving this out to part of our cluster today (unless someone can convince me otherwise) and we'll see if it shows real-world improvements. hjm On Friday, September 14, 2012 11:33:34 AM Venky Shankar wrote: > Hi Harry, > > There is a compression translator in Gerrit which you might be > interested in: http://review.gluster.org/#change,3251 > > It compresses data (using zlib library) before it is sent out to the > network from the server and on the other side (client; FUSE mount) it > decompresses it. Also, note that it only does it for data transferred as > part of the read fop and the volfiles needs to be hand edited (CLI > support is still pending) > > I've not performed any performance run till now but I plan to do so soon. > > -Venky > > On Friday 14 September 2012 10:25 AM, harry mangalam wrote: > > Hi All, > > > > We have been experimenting with 'protocol stacking' - that is, running > > gluster over NFS. > > > > What I mean: > > - mounting a gluster fs via the native client, > > - then NFS-exporting the gluster fs to the client itself > > - then mounting that gluster fs via NFS3 to take advantage of the > > client-side caching. > > > > We've tried it on a limited basis (single client) and not only does it > > work, but it works surprisingly well, gaining about 2-3X the write > > performance relative to the native gluster mount on uncompressed data, > > using small writes. Using compressed data (piping thru gzip, for example) > > is more variable - if the data is highly compressible, it tends to > > increase performance; if less compressible, it tends to decrease > > performance. As I noted previously <http://goo.gl/7G7k3>, piping small > > writes thru gzip /can/ tremendously increase performance on a gluster fs > > in some bioinformatics applications. > > > > A graph of the performance on various file sizes (created by a trivial > > program that does zillions of tiny writes - a sore point in the gluster > > performance spectrum) is shown here: > > > > http://moo.nac.uci.edu/~hjm/fs_perf_gl-tmp-glnfs.png > > > > The graphs show the time to complete and sync on a set of writes from 10MB > > to 30GB on 3 fs's: > > > > - /tmp on the client's system disk (a single 10K USCSI) > > - /gl, a 4 server, 4 brick gluster (distributed-only) fs > > - /gl/nfs, the same gluster fs, loopback-mounted via NFS3 on the client > > > > The results show that using a gluster fs loopback-mounted to itself > > increased performance by 2-3X, increasing as the file size increased to > > 30GB. > > > > The client (64GB RAM) was otherwise idle when I did these tests. > > > > In addition (data not shown), I also tested how compression (piping the > > output thru gzip) affected the total time-to-complete. In one case, due > > to the identical string being written, gzip managed about 1000X > > compression, so the eventual file size sent to the disk was almost > > inconsequential. Nevertheless, the extra time for the compression was > > more than made up for by the reduced data and adding gzip decreased the > > time-to-complete significantly. In other testing with less compressible > > data (shown above), the compression time overwhelmed the write time and > > all the fs had essentially identical times per file size. > > > > In all cases, the writes were followed by a 'sync' to flush the cache. > > > > It seems that the loopback NFS mounting of the gluster fs is a fairly > > obvious win (overall, about 2-3x times the write speed) in terms of > > taking avantage of gluster's fs scaling and namespace with NFS3's > > client-side caching, but I'd like to hear from other gluster users as to > > possible downsides of this approach. > > > > hjm > > _______________________________________________ > Gluster-users mailing list > Gluster-users at gluster.org > http://gluster.org/cgi-bin/mailman/listinfo/gluster-users -- Harry Mangalam - Research Computing, OIT, Rm 225 MSTB, UC Irvine [m/c 2225] / 92697 Google Voice Multiplexer: (949) 478-4487 415 South Circle View Dr, Irvine, CA, 92697 [shipping] MSTB Lat/Long: (33.642025,-117.844414) (paste into Google Maps) -- What does it say about a society that would rather send its children to kill and die for oil than to get on a bike?
{kind=link}
