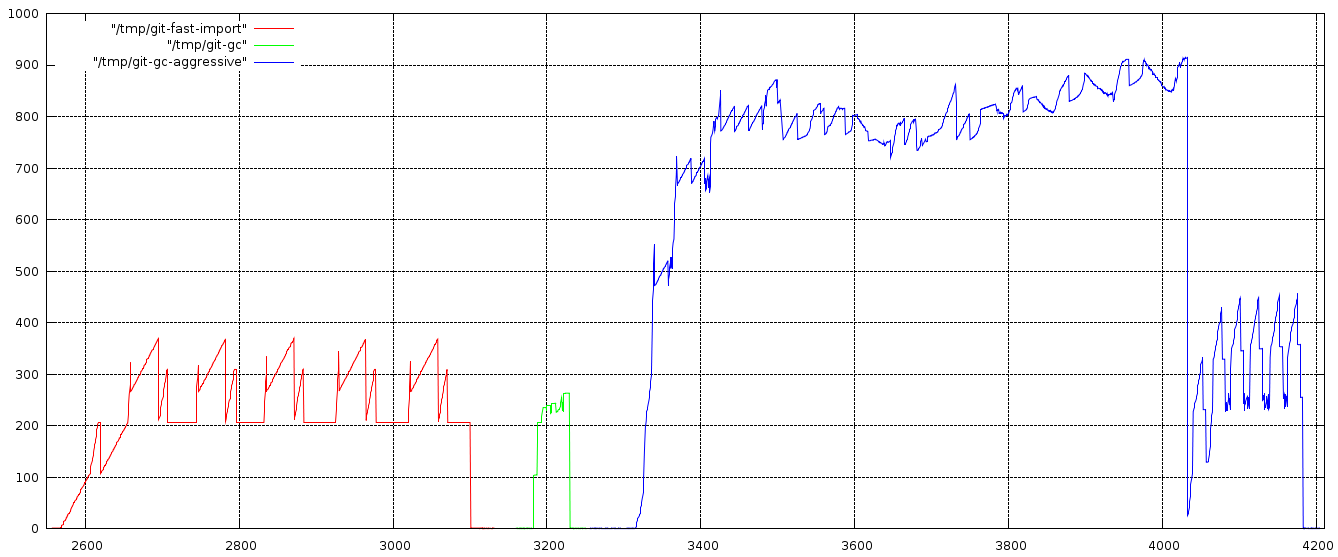
I joined a project that uses very large binary files (up to 1 GiB) in a p4 repository and as I would like to use Git, I am trying to make it more memory-efficient when handling huge files. The first problem I am hitting is with fast-import. Currently it keeps the last imported file in memory (end of store_object()) in order to find interesting deltas with the next file. Since most huge binary files are already compressed, it means that fast-importing two large X MiB files is going to use at least 3X MiB of memory: once for the first file, once for the second file, and once for the deflate data that is going to be as large as the file itself. In practice, it takes even more memory than that. Experiment shows that importing six 100 MiB files made of urandom data takes 370 MiB of memory (http://zoy.org/~sam/git/git-memory-usage.png) (simple script available at http://zoy.org/~sam/git/gencommit.txt). I am unable to plot how it behaves with 1 GiB files since I don't have enough memory, but I don't see why the trend wouldn't stand. I can understand it not being a priority, but I'm trying to think of acceptable ways to fix this that do not mess with Git's performance in more usual cases. Here is what I can think of: - stop trying to compute deltas in fast-import and leave that task to other tools (optionally, define a file size threshold beyond which the last file is not kept in memory, and maybe make that a configuration option). - use a temporary file to store the deflate data when it reaches a given size threshold (and maybe make that a configuration option). - also, I haven't tracked all strbuf_* uses in fast-import, but I got the feeling that strbuf_release() could be used in a few places instead of strbuf_setlen(0) in order to free some memory. Any thoughts? -- Sam. -- To unsubscribe from this list: send the line "unsubscribe git" in the body of a message to majordomo@xxxxxxxxxxxxxxx More majordomo info at http://vger.kernel.org/majordomo-info.html
{kind=link}
