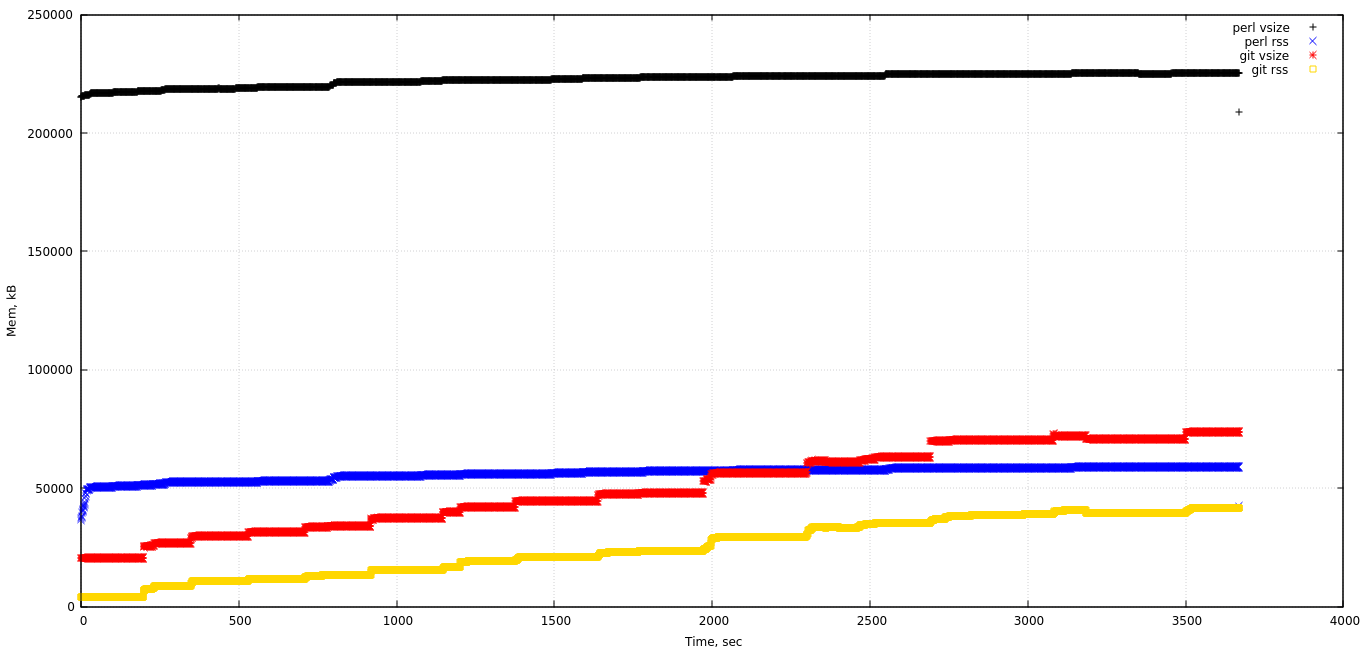
Hello all, We are currently getting acquainted with git-svn tool and have experienced few problems with it. The main issue is memory usage during "git svn clone": on large repositories the perl and git processes are using significant amount of memory. I have conducted several tests with different repositories. I have created mirrors of Trac project (http://trac.edgewall.org/ - rather small repo, ~14000 commits) and FreeBSD base repo (~280000 commits). Here is the summary of my tests (to eliminate network issues all clones were performed for file:// repos): * git svn clone of trac takes about 1 hour * git svn clone of FreeBSD has already taken more than 3 days and still running (currently has cloned about 40% of revisions) * git cat-file process memory footprint keeps growing during the clone process (see figure attached) The main issue here is git cat-file consuming memory. The attached figure is for small repository which takes about an hour to clone, however on my another machine where FreeBSD clone is currently running the git cat-file has already taken more than 1Gb of memory (RSS) and has overgrown the parent perl process (~300-400 Mb). I have valgrind'ed the git-cat-file (which is running is --batch mode during the whole clone) and found no serious leaks (about 100 bytes definitely leaked), so all memory is carefully freed, but the heap usage grows maybe due to fragmentation or smth else. When I looked through the code I found out that most of heap allocations are called from batch_object_write() function (strbuf_expand -> realloc). So I have found two possible workarounds for the issue: * Set GIT_ALLOC_LIMIT variable - it does reduce the memory footprint but slows down the process * In perl code do not run git cat-file in batch mode (in Git::SVN::apply_textdelta) but rather run it as separate commands each time my $size = $self->command_oneline('cat-file', '-s', $sha1); # ..... my ($in, $c) = $self->command_output_pipe('cat-file', 'blob', $sha1); The second approach doesn't slow down the whole process at all (~72 minutes to clone repo both with --batch mode and without). So the question is: what would be the correct approach to fight the problem with cat-file memory usage: maybe we should get rid of batch mode in perl code, or somehow tune allocation policy in C code? Please let me know your thoughts. -- Best Regards, Victor Leschuk
Attachment:
mem_usage.png
Description: mem_usage.png
{kind=link}