I've been thinking a lot about merge bases lately and think I have
discovered something interesting.
tl;dr:
When two branches have multiple merge bases,
git merge-base $master $branch
picks one merge base more or less arbitrarily. Here I describe a
criterion for picking a "best" merge base. When the best merge base
is used, the diff output by
git diff $master...$branch
becomes shorter and simpler--sometimes dramatically so. I have
quantified the improvement by analyzing historical merges from the Git
project (see attached image). Best merge bases might also help reduce
conflicts when conducting merges.
Background
==========
A merge base of two or more branches is a common ancestor of those
branches that has no descendant that is also a common ancestor (see
`git-merge-base(1)`). Merge bases are important when merging
branches, and are also used internally to some other commands like
"git diff $master...$branch".
Sometimes branches have multiple merge bases, such as in the case of a
criss-cross merge:
o--A--o--o--X--o--Y--o--Z <- master
\ \ /
\ \ /
\ ·
\ / \
\ / \
B--C--D--E--F <- branch
Here, commits X and C are both merge bases for branches master and
branch. You can list all merge bases by running
git merge-base --all $master $branch
But if you run
git merge-base $master $branch
only one merge base is returned. *Which* one it returns is not
documented and appears to be pretty arbitrary (probably a side effect
of the traversal order?)
The "best" merge base
=====================
But not all merge bases are created equal. It is possible to define a
"best" merge base that has some nice properties.
Let's focus on the command
git diff $master...$branch
which is equivalent to
git diff $(git merge-base $master $branch)..$branch
We want such a diff to have two properties:
1. It must include *all* changes that have been made on the branch but
are not yet contained in master.
2. It should contain *as few* changes as possible that are already in
master.
The first property is satisfied automatically if the left end of the
"diff" range is any merge base. Because a merge base is an ancestor
of master, it cannot possibly include any changes that were made on
the branch but have not yet been merged to master [1].
The second property requires as a *necessary* condition that the left
end of the diff is a merge base. But the property also helps us pick
the best among multiple merge bases. We just need to make the idea of
"contains as few changes as possible" more precise.
I propose that the best merge base is the merge base "candidate" that
minimizes the number of non-merge commits that are in
git rev-list --no-merges $candidate..$branch
but are already in master:
git rev-list --no-merges $master
Since a non-merge commit should embody a single logical change,
counting non-merge commits is in some sense counting changes [2].
We can put this criterion in simpler form. Because every candidate is
a merge-base,
git rev-list --no-merges $candidate..$branch
necessarily includes *all* of the non-merge commits that are on branch
but not on master. This is a fixed number of commits, the same for
every candidate. It *additionally* includes the commits that are on
master but not yet in branch. This second number varies from one
candidate to another. So if we minimize the number of commits in this
output, is is the same as minimizing the number of unwanted commits.
Therefore, to get the best merge base, all we have to do is pick the
merge base that minimizes
git rev-list --count --no-merges $candidate..$branch
There can be ties, but in practice they are rare enough that it is
probably not worth worrying about them.
Symmetry; generalization to more than two branches
==================================================
Interestingly, minimizing the last criterion is the same as maximizing
git rev-list --count --no-merges $candidate
because there is a fixed number of commits in
git rev-list --no-merges $branch
, and each of those commits is in exactly one of the two counts above.
This formulation shows that the best merge base for computing
git diff $master...$branch
is also the best merge base for computing
git diff $branch...$master
; i.e., the best merge base is symmetric in its arguments. It also
shows that the concept of "best merge base" can trivially be
generalized to more than two branches.
git-best-merge-base script
===========================
The best merge base can be computed, for example, using the following
script:
#! /bin/sh
# Usage: git-best-merge-base MASTER BRANCH
set -e
master="$1"
branch="$2"
count() {
git rev-list --no-merges --count "$1..$branch"
}
# Note that if $master and $branch have no common ancestors, `git
# merge-base` fails with retcode=1, causing the script to exit
# with the same error code.
merge_bases=$(git merge-base --all "$master" "$branch")
case "${#merge_bases}" in
40)
# One merge base -> use it.
echo $merge_bases
;;
*)
# Multiple merge bases -> pick the one for which $base..$branch
# has the fewest commits that are already in $master. To ensure
# that the result is repeatable, if there is a tie we choose the
# merge base that comes first when sorted by SHA-1:
for merge_base in $merge_bases
do
echo $(count $merge_base) $merge_base
done | sort -k1,1n -k2 | sed -ne '1s/^.* //p'
;;
esac
Do best merge bases really help?
================================
I analyzed all of the 2-parent merges made in the history of the Git
project. (I limited the analysis to 2-parent merges just for
simplicity.) I computed the size of the asymmetric diffs
git diff $commit^1...$commit^2
using the current code and using git-best-merge-base, with the
following script:
#! /bin/sh
old_diff_len() {
git diff $1...$2 | wc -l
}
new_diff_len() {
git diff $(git-best-merge-base $1 $2)..$2 | wc -l
}
git rev-list --min-parents=2 --max-parents=2 --parents "$@" |
while read commit p1 p2
do
echo "$commit $(git merge-base --all $p1 $p2 | wc -l)
$(old_diff_len $p1 $p2) $(new_diff_len $p1 $p2)"
done
Results:
* Total number of merges: 8263
* Total number of merges with exactly two parents: 8229
Of which:
* Number with zero merge bases: 6 (0.07%)
* Number with one merge base: 7823 (95.1%)
* Number with multiple merge bases: 400 (4.8%)
Of which:
* Number whose diffs shrink: 71 (17.8%)
* Number whose diffs remain the same length: 323 (80.1%)
* Number whose diffs grow: 6 (1.5%)
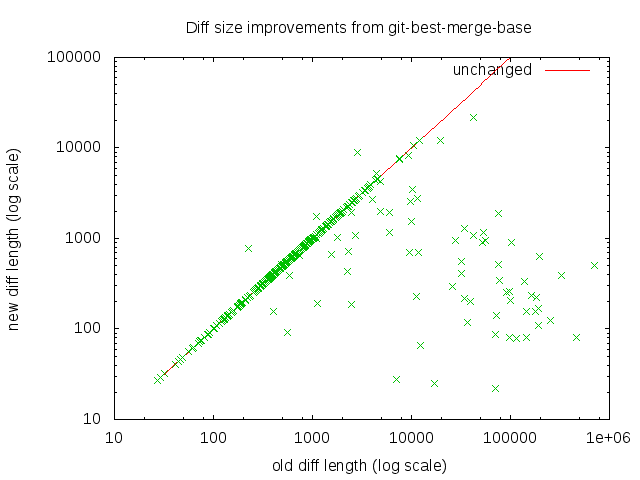
I have attached a graph plotting the diff sizes against each other on
a log-log scale. The points *under* the red line are diffs that have
shrunk; the points *over* the red line are the diffs that have grown.
As you can see, far more diffs shrank than grew, and by larger
factors. Some of the diffs have shrunk dramatically. In the most
drastic case, the diff shrank from 466602 lines to 81 lines.
A relatively small fraction of all merges are affected, but of merges
that have multiple merge bases (which are the most difficult merges to
handle), more than one in six would be simplified.
I should mention that I have done a similar analysis of a large
commercial software project's history, with broadly similar results.
I wouldn't be surprised if selecting merge bases more intelligently in
"git merge" also helps make more merges go through without conflicts.
Suggested next steps
====================
I don't have time right now to work more on best merge bases, and I am
not very familiar with the parts of the code that would be involved.
So I'm hoping that somebody else finds this a worthwhile improvement
and tries implementing best merge bases in git core. I have the
following suggestions:
* Add an option
git merge-base --best <commit> <commit>...
that computes the best merge base as described above. Its output
can be tested against the git-best-merge-base script that I
provided.
* Use the best merge base when computing
git diff <commit>...<commit>
This should give shorter differences in many cases.
* Benchmark "merge-base" with the "--best" option and, if it is not
too expensive, perhaps make it the default behavior of "merge-base".
* See whether best merge bases can be used to improve other parts of
the code, especially the code for the recursive merge strategy.
Michael
[1] I assume that commits make independent changes. If some commits
in fact revert changes made by other commits, or some commits have
been cherry-picked across branches, then the correlation between
number of commits and size of diff will be a bit weaker but should
still be a useful approximation.
[2] There are other ways that "fewest changes" could be defined. We
could include merge commits in the count of extra commits. (This
variant could be implemented by omitting `--no-merges` in the
`rev-list` commands above.) Or, when diffing only text files, we
could try to minimize the overall textual length of the diff. The
definition used in the main text is chosen for being reasonable,
general, symmetric, and not too expensive to compute.
--
Michael Haggerty
mhagger@xxxxxxxxxxxx
Attachment:
diff-sizes.png
Description: PNG image
{kind=link}