On Fri, Mar 29, 2013 at 04:32:00PM -0400, Jeff King wrote:
> > Agreed. Although I think it's getting out of my domain. I'm not even
> > sure how many factors are involved.
>
> There's the load factor that causes us to grow, and the growth factor of
> how aggressively we expand when we do need to grow. I fooled around with
> a few numbers and the patch below seemed to give good results. Probably
> varying both numbers over a range and graphing the result would make
> sense, but I don't have time to do it at the moment (each run takes a
> while, if I do best-of-five).
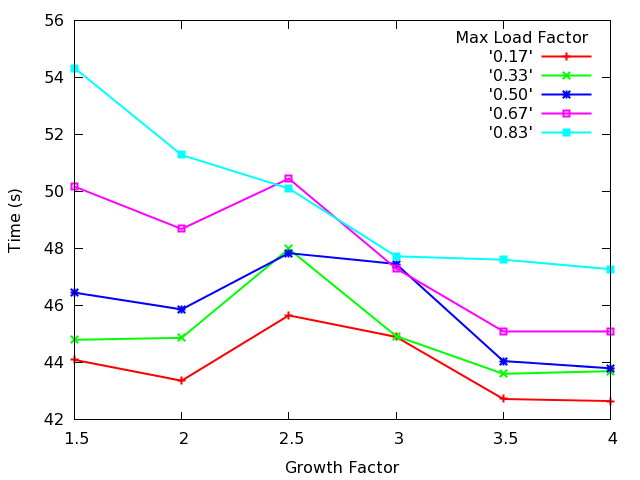
So I did that. I'm still not quite sure what it means, but here's the
data (all times are best-of-five wall-clock times to complete `git
rev-list --objects --all` on linux-2.6, in seconds).
Load | Growth |
Factor | Factor | Time
-------+--------+--------
0.17 | 1.50 | 44.104
0.17 | 2.00 | 43.373
0.17 | 2.50 | 45.662
0.17 | 3.00 | 44.909
0.17 | 3.50 | 42.733
0.17 | 4.00 | 42.659
0.33 | 1.50 | 44.806
0.33 | 2.00 | 44.876
0.33 | 2.50 | 47.991
0.33 | 3.00 | 44.940
0.33 | 3.50 | 43.615
0.33 | 4.00 | 43.707
0.50 | 1.50 | 46.459
0.50 | 2.00 | 45.872
0.50 | 2.50 | 47.844
0.50 | 3.00 | 47.466
0.50 | 3.50 | 44.063
0.50 | 4.00 | 43.807
0.67 | 1.50 | 50.178
0.67 | 2.00 | 48.692
0.67 | 2.50 | 50.458
0.67 | 3.00 | 47.307
0.67 | 3.50 | 45.114
0.67 | 4.00 | 45.114
0.83 | 1.50 | 54.337
0.83 | 2.00 | 51.286
0.83 | 2.50 | 50.110
0.83 | 3.00 | 47.736
0.83 | 3.50 | 47.617
0.83 | 4.00 | 47.282
I'm attaching a graph of the results, too, which I think makes it easier
to look at (and you probably want to look at it now, or the rest of this
won't make any sense). The interesting things I see are:
1. The benefits of increasing the growth factor flatten out around
3x-4x.
2. Obviously having a smaller load factor increases efficiency.
3. Increasing the growth factor compensates for a worse load factor
(e.g., a growth rate of 3 performs about the same with a load
factor of 1/2 to 5/6).
It makes sense that one could compensate for the other. Our pattern of
growth for the hash is to add a lot at first, and then more and more
frequently hit objects that we have already seen (because the number we
have seen is going up). So we do many more queries on the hash when it
is at size X than when it is at X/2.
Or another way of thinking about it is: it doesn't matter that much how
we get there, but when we reach our final size (where most of our
lookups are going to happen), how crowded is the hash table (i.e., how
many times are we going to see collisions and have to do extra
hashcmps?).
With a load factor of 0.17, we know it never goes over that. But with a
configured max load factor of 0.5, right after we double, we know the
load factor is now only 0.25; it will rise again from there, but not
necessarily even back up to 0.5 (if we never allocate again).
And I think that explains the weird spikes. Why, when we have a load
factor of 0.33, do we perform worse with a growth factor of 2.5 than
with 2? The hash should be more sparse. And I think the answer is: for
the number of objects we have, it so happens that the growth factor of 2
causes us to end up with a more sparsely populated table, and we see
a lot of queries on the table in that state. Whereas with 2.5, we do
fewer growth iterations, but end in a state that is slightly less
optimal.
Given this conjecture, I added an atexit() to determine the final state
of the hash. Here are the final states for a max load factor of 0.33,
and a few growth rates:
grow | objects | objects | final
rate | used | alloc | load
-----+---------+----------+------
2 | 3005531 | 16777216 | 0.179
2.5 | 3005531 | 11920105 | 0.252
3 | 3005531 | 17006112 | 0.177
I think that supports the conjecture; the final load factor is much
worse with 2.5 than with 2 or 3. Not for any good reason; it just
happens to match the growth pattern we see given the number of objects
we have. Of course the tradeoff is that we waste more memory (37M with
8-byte pointers).
So what should we do? I don't think increasing the growth rate makes
sense. Whether we end up helping or hurting is somewhat random, as it is
really all about where we end up in terms of the final load factor,
where most of our queries happen.
We would do much better to tweak the max load factor, which ensures that
the final load factor (and the intermediate ones) is below a certain
value. Of course that comes at the cost of wasted memory. Moving from
the current load factor of 0.5 to 0.33 saves us about 1 second
processing time. But it means our memory usage jumps (in this case, it
doubles from 64M to 128M). So there are small savings to be had, but
bigger memory losses; I guess the question is how much we would care
about those memory losses (on a modern machine, using an extra 64M for
the kernel repo is not that big a deal).
And of course the other thing to do is to use a slotting mechanism that
reduces conflicts. Junio experimented with cuckoo hashing, and after
reading his attempt, I tried quadratic stepping. As I recall, neither
experiment yielded anything impressive (though I may simply have looked
at 1s speedup and considered it "not impressive"; I don't remember).
So I dunno. We are close to as good as it will get, I think. We might
steal a few percent by making a memory tradeoff, or doing something
clever with the hash stepping (cuckoo, quadratic, etc). But those are
big-ish jumps in complexity or memory use for not much gain.
My test harness patch is below in case anybody wants to play with.
-Peff
---
diff --git a/object.c b/object.c
index 20703f5..dd04009 100644
--- a/object.c
+++ b/object.c
@@ -88,12 +88,26 @@ static void grow_object_hash(void)
return obj;
}
+static void print_hash_size(void)
+{
+ fprintf(stderr, "final hash size is %d/%d = %f\n",
+ nr_objs, obj_hash_size, ((double)nr_objs)/obj_hash_size);
+}
+
static void grow_object_hash(void)
{
+ static int rate;
int i;
- int new_hash_size = obj_hash_size < 32 ? 32 : 2 * obj_hash_size;
+ int new_hash_size;
struct object **new_hash;
+ if (!rate) {
+ /* in units of 1/2 to give more resolution and avoid floats */
+ rate = atoi(getenv("GIT_GROW_RATE"));
+ atexit(print_hash_size);
+ }
+
+ new_hash_size = obj_hash_size < 32 ? 32 : obj_hash_size * rate / 2;
new_hash = xcalloc(new_hash_size, sizeof(struct object *));
for (i = 0; i < obj_hash_size; i++) {
struct object *obj = obj_hash[i];
@@ -109,6 +123,7 @@ void *create_object(const unsigned char *sha1, int type, void *o)
void *create_object(const unsigned char *sha1, int type, void *o)
{
struct object *obj = o;
+ static int factor;
obj->parsed = 0;
obj->used = 0;
@@ -116,7 +131,11 @@ void *create_object(const unsigned char *sha1, int type, void *o)
obj->flags = 0;
hashcpy(obj->sha1, sha1);
- if (obj_hash_size - 1 <= nr_objs * 2)
+ /* in units of 1/6 to give more resolution and avoid floats */
+ if (!factor)
+ factor = atoi(getenv("GIT_LOAD_FACTOR"));
+
+ if (nr_objs + 1 > obj_hash_size * factor / 6)
grow_object_hash();
insert_obj_hash(obj, obj_hash, obj_hash_size);
Attachment:
load-growth.png
Description: PNG image
{kind=link}