Jello,
I am still depressed about my performance. I have made following
"improvements" in code:
1. I am not using sqrt function anymore (it seems squared euclidean
distance is itself a metric)
2. I am using single precision calculations
3. I am using a different memory organization (SOA), now I have two
big arrays with all X coordinates in one and all Y coordinates in the
other.
4. I have changed logic to save once current point in registers and
iterate, in a SIMD fashion, over the rest.
5. I am turning on full brutal optimization in gcc (-O3)
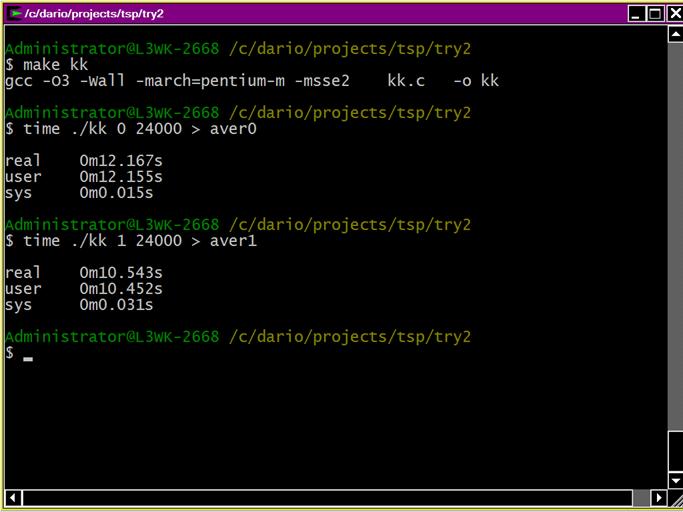
Still with these changes, I only got an small improvement in time ...
around 10%. I would have expected an improvement of around 75% given I
am now doing 4 operations at a time (and that is if we do not count
pipelining which may exec more than one SSE2 instruction at a "time"
... but unsure here, could be telling nonsense crap ;-).
Please, hardcore intel gods of assembler optimization, provide some
feedback for this poor beast of the forest.
Thanks
PS: Attached are the program, dummy makefile, sample usage and the
assembler generated. An input size of 24,000 is enough to see the
problem (dimension must be multiple of 8).
On Tue, Apr 8, 2008 at 9:55 AM, Dario Bahena Tapia <dario.mx@xxxxxxxxx> wrote:
> Hello,
>
> Yeah, others have suggested as well changing the way i process them in
> order to allow for that. Working there ;-|
>
> Will consider the other suggestions as well !!!
>
> Thanks.
>
>
>
>
> On Tue, Apr 8, 2008 at 2:07 AM, Zuxy Meng <zuxy.meng@xxxxxxxxx> wrote:
> > Hi,
> >
> > "Dario Bahena Tapia" <dario.mx@xxxxxxxxx>
> > 写入消息新闻:3d104d6f0804070617u47213cc8nbc697dab9dc262b5@xxxxxxxxxxxxxxxxx
> >
> >
> >
> > > Hello,
> > >
> > > I have just begun to play with SSE2 and gcc intrinsics. Indeed, maybe
> > > this question is not exactly about gcc ... but I think gcc lists are
> > > a very good place to find help from hardcore assembler hackers ;-1
> > >
> > > I have a program which makes heavy usage of euclidean distance
> > > function. The serial version is:
> > >
> > > inline static double dist(int i,int j)
> > > {
> > > double xd = C[i][X] - C[j][X];
> > > double yd = C[i][Y] - C[j][Y];
> > > return rint(sqrt(xd*xd + yd*yd));
> > > }
> > >
> > > As you can see each C[i] is an array of two double which represents a
> > > 2D vector (indexes 0 and 1 are coordinates X,Y respectively). I tried
> > > to vectorize the function using SSE2 and gcc intrinsics, here is the
> > > result:
> > >
> > > inline static double dist_sse(int i,int j)
> > > {
> > > double d;
> > > __m128d xmm0,xmm1;
> > > xmm0 =_mm_load_pd(C[i]);
> > > xmm1 = _mm_load_pd(C[j]);
> > > xmm0 = _mm_sub_pd(xmm0,xmm1);
> > > xmm1 = xmm0;
> > > xmm0 = _mm_mul_pd(xmm0,xmm1);
> > > xmm1 = _mm_shuffle_pd(xmm0, xmm0, _MM_SHUFFLE2(1, 1));
> > > xmm0 = _mm_add_pd(xmm0,xmm1);
> > > xmm0 = _mm_sqrt_pd(xmm0);
> > > _mm_store_sd(&d,xmm0);
> > > return rint(d);
> > > }
> > >
> > > Of course each C[i] was aligned as SSE2 expects:
> > >
> > > for(i=0; i<D; i++)
> > > C[i] = (double *) _mm_malloc(2 * sizeof(double), 16);
> > >
> > > And in order to activate the SSE2 features, I am using the following
> > > flags for gcc (my computer is a laptop):
> > >
> > > CFLAGS = -O -Wall -march=pentium-m -msse2
> > >
> > > The vectorized version of the function seems to be correct, given it
> > > provides same results as serial counterpart. However, the performace
> > > is poor; execution time of program increases in approximately 50% (for
> > > example, in calculating the distance of every pair of points from a
> > > set of 10,000, the serial version takes around 8 seconds while
> > > vectorized flavor takes 12).
> > >
> > > I was expecting a better time given that:
> > >
> > > 1. The difference of X and Y is done in parallel
> > > 2. The product of each difference coordinate with itself is also done
> > > in parallel
> > > 3. The sqrt function used is hardware implemented (although serial
> > > sqrt implementation could also take advantage of hardware)
> > >
> > > I suppose the problem here is my lack of experience programming in
> > > assembler in general, and in particular with SSE2. Therefore, I am
> > > looking for advice.
> > >
> >
> > 1. First of all, you didn't extract the parallelism in your algorithm. SSE2
> > won't help you if all you want is to pick up two points at random indices
> > and calculate the distance. However it will help you a lot when you
> > calculate the distances between a given point and 1 million others whose
> > indices are sequential.
> >
> > 2. Unroll the loop to hide the latency of square root as much as possible.
> >
> > 3. Since the final result is an integer, you may consider using "float"
> > instead of "double". That'll give you a performance boost even without SSE2.
> > And rsqrtps comes in handy too, if its precision is acceptable.
> >
> > --
> > Zuxy
> >
> >
>
Attachment:
kk.c
Description: Binary data
Attachment:
makefile
Description: Binary data
Attachment:
image002.jpg
Description: JPEG image
Attachment:
kk.s
Description: Binary data

{kind=link}