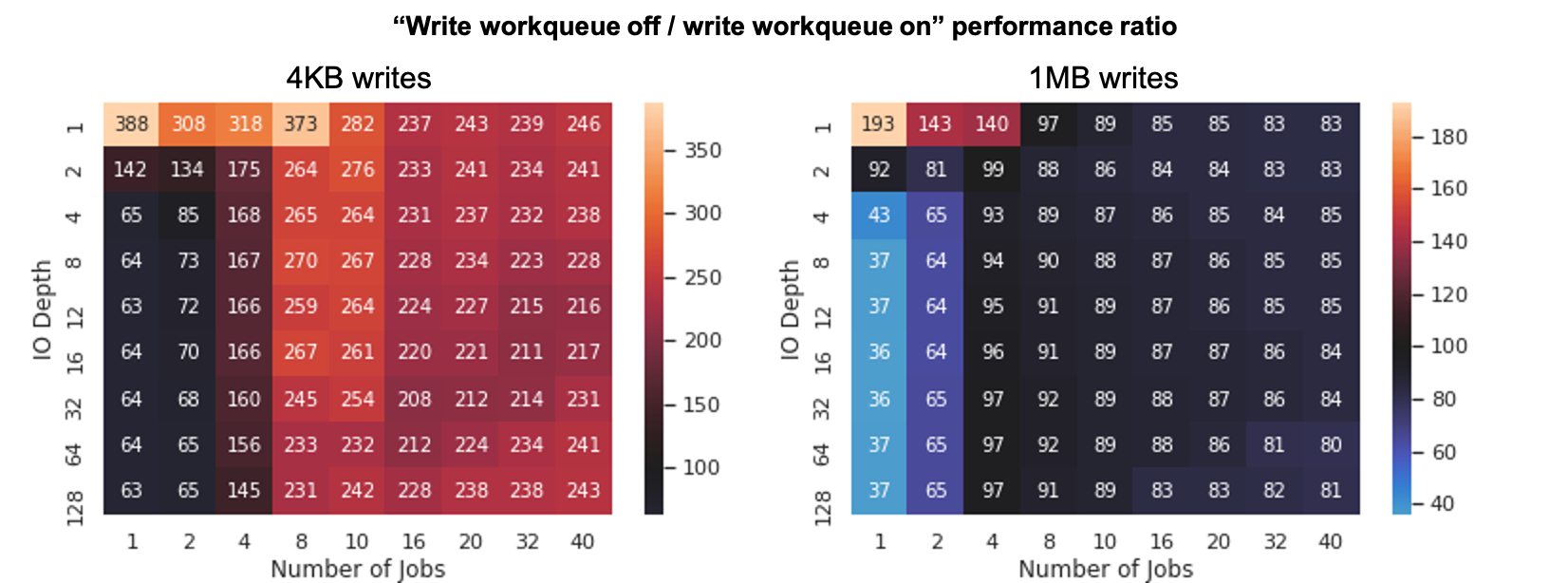
John, On 2020/08/19 13:25, John Dorminy wrote: > Your points are good. I don't know a good macrobenchmark at present, > but at least various latency numbers are easy to get out of fio. > > I ran a similar set of tests on an Optane 900P with results below. > 'clat' is, as fio reports, the completion latency, measured in usec. > 'configuration' is [block size], [iodepth], [jobs]; picked to be a > varied selection that obtained excellent throughput from the drive. > Table reports average, and 99th percentile, latency times as well as > throughput. It matches Ignat's report that large block sizes using the > new option can have worse latency and throughput on top-end drives, > although that result doesn't make any sense to me. > > Happy to run some more there or elsewhere if there are suggestions. > > devicetype configuration MB/s clat mean clat 99% > ------------------------------------------------------------------ > nvme base 1m,32,4 2259 59280 67634 > crypt default 1m,32,4 2267 59050 182000 > crypt no_w_wq 1m,32,4 1758 73954.54 84411 > nvme base 64k,1024,1 2273 29500.92 30540 > crypt default 64k,1024,1 2167 29518.89 50594 > crypt no_w_wq 64k,1024,1 2056 31090.23 31327 > nvme base 4k,128,4 2159 924.57 1106 > crypt default 4k,128,4 1256 1663.67 3294 > crypt no_w_wq 4k,128,4 1703 1165.69 1319 I have been doing a lot of testing recently on dm-crypt, mostly for zoned storage, that is with write workqueue disabled, but also with regular disks to have something to compare to and verify my results. I confirm that I see similar changes in throughput/latency in my tests: disabling workqueues improves throughput for small IO sizes thanks to the lower latency (removed context switch overhead), but the benefits of disabling the workqueues become dubious for large IO sizes, and deep queue depth. See the heat-map attached for more results (nullblk device used for these measurements with 1 job per CPU). I also pushed things further as my tests as I primarily focused on enterprise systems with a large number of storage devices being used with a single server. To flatten things out and avoid any performance limitations due to the storage devices, PCIe and/or HBA bus speed and memory bus speed, I ended up performing lots of tests using nullblk with different settings: 1) SSD like multiqueue setting without "none" scheduler, with irq_mode=0 (immediate completion in submission context) and irq_mode=1 for softirq completion (different completion context than submission). 2) HDD like single queue with mq-deadline as the scheduler, and the different irq_mode settings. I also played with CPU assignments for the fio jobs and tried various things. My observations are as follows, in no particular order: 1) Maximum throughput clearly directly depends on the numbers of CPUs involved in the crypto work. The crypto acceleration is limited per core and so the number of issuer contexts (for writes) and or completion contexts (for reads) almost directly determine maximum performance with worqueue disabled. I measured about 1.4GB/s at best on my system with a single writer 128KB/QD=4. 2) For a multi drive setup with IO issuers limited to a small set of CPUs, performance does not scale with the number of disks as the crypto engine speed of the CPUs being used is the limiting factor: both write encryption and read decryption happen on that set of CPUs, regardless of the others CPUs load. 3) For single queue devices, write performance scales badly with the number of CPUs used for IO issuing: the one CPU that runs the device queue to dispatch commands end up doing a lot of crypto work for requests queued through other CPUs too. 4) On a very busy system with a very large number of disks and CPUs used for IOs, the total throughput I get is very close for all settings with workqueues enabled and disabled, about 50GB/s total on my dual socket Xeon system. There was a small advantage for the none scheduler/multiqueue setting that gave up to 56GB/s with workqueues on and 47GB/s with workqueues off. The single queue/mq-deadline case gave 51 GB/s and 48 GB/s with workqueues on/off. 5) For the tests with the large number of drives and CPUs, things got interesting with the average latency: I saw about the same average with workqueues on and off. But the p99 latency was about 3 times lower with workqueues off than workqueues on. When all CPUs are busy, reducing overhead by avoiding additional context switches clearly helps. 6) With an arguably more realistic workload of 66% read and 34 % writes (read size is 64KB/1MB with a 60%/40% ratio and write size is fixed at 1MB), I ended up with higher total throughput with workqueues disabled (44GB/s) vs enabled (38GB/s). Average write latency was also 30% lower with workqueues disabled without any significant change to the average read latency. From all these tests, I am currently considering that for a large system with lots of devices, disabling workqueues is a win, as long as IO issuers are not limited to a small set of CPUs. The benefits of disabling workqueues for a desktop like system or a server system with one (or very few) super fast drives are much less clear in my opinion. Average and p99 latency are generally better with workqueues off, but total throughput may significantly suffer if only a small number of IO contexts are involved, that is, a small number of CPUs participate in the crypto processing. Then crypto hardware speed dictates the results and using workqueues to get parallelism between more CPU cores can give better throughput. That said, I am thinking that from all this, we can extract some hints to automate decision for using workqueues or not: 1) Small IOs (e.g. 4K) would probably benefit from having workqueue disabled, especially for 4Kn storage devices as such request would be processed as a single block with a single crypto API call. 2) It may be good to process any BIO marked with REQ_HIPRI (polling BIO) without any workqueue, to reduce latency, as intended by the caller. 3) We may want to have read-ahead reads use workqueues, especially for single queue devices (HDDs) to avoid increasing latency for other reads completing together with these read-ahead requests. In the end, I am still scratching my head trying to figure out what the best default setup may be. Best regards. -- Damien Le Moal Western Digital Research
Attachment:
heatmap.png
Description: heatmap.png
-- dm-devel mailing list dm-devel@xxxxxxxxxx https://www.redhat.com/mailman/listinfo/dm-devel

{kind=link}