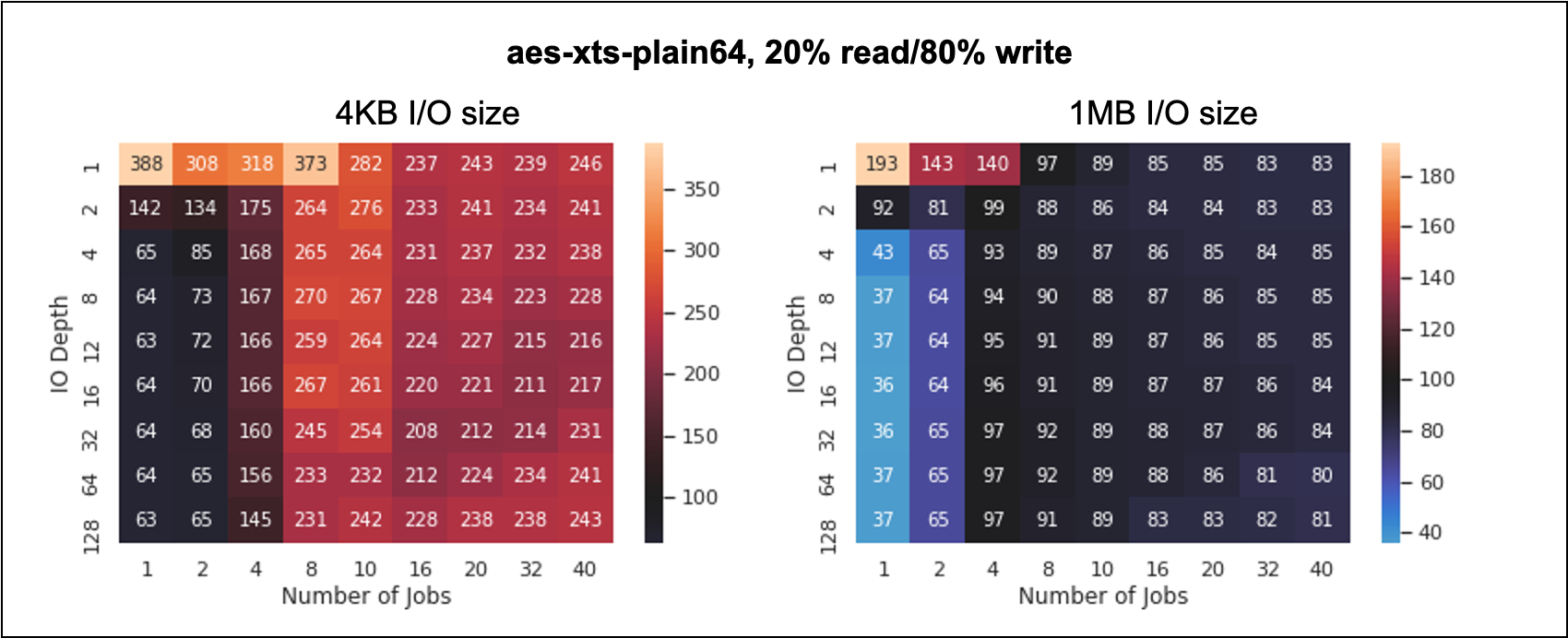
On 2020/07/06 11:28, Nobuto Murata wrote: > On 6/27/20 6:03 AM, Ignat Korchagin wrote: >> This is a follow up from [1]. Consider the following script: >> >> sudo modprobe brd rd_nr=1 rd_size=4194304 >> >> echo '0 8388608 crypt capi:ecb(cipher_null) - 0 /dev/ram0 0' | \ >> sudo dmsetup create eram0 >> >> echo '0 8388608 crypt capi:ecb(cipher_null) - 0 /dev/ram0 0 1 no_write_workqueue' | \ >> sudo dmsetup create eram0-inline-write >> >> echo '0 8388608 crypt capi:ecb(cipher_null) - 0 /dev/ram0 0 1 no_read_workqueue' | \ >> sudo dmsetup create eram0-inline-read >> >> devices="/dev/ram0 /dev/mapper/eram0 /dev/mapper/eram0-inline-read " >> devices+="/dev/mapper/eram0-inline-write" >> >> for dev in $devices; do >> echo "reading from $dev" >> sudo fio --filename=$dev --readwrite=read --bs=4k --direct=1 \ >> --loops=1000000 --runtime=3m --name=plain | grep READ >> done >> >> for dev in $devices; do >> echo "writing to $dev" >> sudo fio --filename=$dev --readwrite=write --bs=4k --direct=1 \ >> --loops=1000000 --runtime=3m --name=plain | grep WRITE >> done >> >> This script creates a ramdisk (to eliminate hardware bias in the benchmark) and >> three dm-crypt instances on top. All dm-crypt instances use the NULL cipher >> to eliminate potentially expensive crypto bias (the NULL cipher just uses memcpy >> for "encyption"). The first instance is the current dm-crypt implementation from >> 5.8-rc2, the two others have new optional flags enabled, which bypass kcryptd >> workqueues for reads and writes respectively and write sorting for writes. On >> my VM (Debian in VirtualBox with 4 cores on 2.8 GHz Quad-Core Intel Core i7) I >> get the following output (formatted for better readability): >> >> reading from /dev/ram0 >> READ: bw=508MiB/s (533MB/s), 508MiB/s-508MiB/s (533MB/s-533MB/s), io=89.3GiB (95.9GB), run=180000-180000msec >> >> reading from /dev/mapper/eram0 >> READ: bw=80.6MiB/s (84.5MB/s), 80.6MiB/s-80.6MiB/s (84.5MB/s-84.5MB/s), io=14.2GiB (15.2GB), run=180000-180000msec >> >> reading from /dev/mapper/eram0-inline-read >> READ: bw=295MiB/s (309MB/s), 295MiB/s-295MiB/s (309MB/s-309MB/s), io=51.8GiB (55.6GB), run=180000-180000msec >> >> reading from /dev/mapper/eram0-inline-write >> READ: bw=114MiB/s (120MB/s), 114MiB/s-114MiB/s (120MB/s-120MB/s), io=20.1GiB (21.5GB), run=180000-180000msec >> >> writing to /dev/ram0 >> WRITE: bw=516MiB/s (541MB/s), 516MiB/s-516MiB/s (541MB/s-541MB/s), io=90.7GiB (97.4GB), run=180001-180001msec >> >> writing to /dev/mapper/eram0 >> WRITE: bw=40.4MiB/s (42.4MB/s), 40.4MiB/s-40.4MiB/s (42.4MB/s-42.4MB/s), io=7271MiB (7624MB), run=180001-180001msec >> >> writing to /dev/mapper/eram0-inline-read >> WRITE: bw=38.9MiB/s (40.8MB/s), 38.9MiB/s-38.9MiB/s (40.8MB/s-40.8MB/s), io=7000MiB (7340MB), run=180001-180001msec >> >> writing to /dev/mapper/eram0-inline-write >> WRITE: bw=277MiB/s (290MB/s), 277MiB/s-277MiB/s (290MB/s-290MB/s), io=48.6GiB (52.2GB), run=180000-180000msec > > I've applied this v2 patch on top of Ubuntu 5.4 kernel and followed the > test case on my personal testbed (bare metal) with AMD Ryzen 7 2700. > Indeed it made things faster in general, but I saw mixed results when > running it with some scenarios close to the actual workloads. I went > back to the test case and ran it with various blocksize, iodepth, and > numjobs, then I saw similar and mixed trends. One of the cases where > no_(read|write)_workqueue doesn't perform well is as follows: > > ################################################## > # 4m ioengine=libaio iodepth=16 numjobs=1 > ################################################## > reading from /dev/ram0 > READ: bw=6208MiB/s (6510MB/s) > reading from /dev/mapper/eram0 > READ: bw=4773MiB/s (5005MB/s) > reading from /dev/mapper/eram0-inline-read > READ: bw=2782MiB/s (2918MB/s) > reading from /dev/mapper/eram0-inline-write > READ: bw=4757MiB/s (4988MB/s) > writing to /dev/ram0 > WRITE: bw=5497MiB/s (5764MB/s) > writing to /dev/mapper/eram0 > WRITE: bw=3143MiB/s (3296MB/s) > writing to /dev/mapper/eram0-inline-read > WRITE: bw=3144MiB/s (3297MB/s) > writing to /dev/mapper/eram0-inline-write > WRITE: bw=1818MiB/s (1906MB/s) > > I've collected the output in: > https://gist.github.com/nobuto-m/74849fb181d9016ddde17c806dac2421#file-patch-v2-testcase_result-txt Cannot open this link. Certificate problems for https connection... > Do you see similar trends when blocksize, iodepth, and numjobs are > changed? Wondered if I should test it again with the latest kernel as > 5.8-rcX properly instead of 5.4. We did some tests with the previous version of this patch and also observed variations based on IO size, queue depth and number of jobs. This is all because of changes in how CPU resources (crypto HW accelerators) are used. Under high queue-depth/large IO size workloads, using workqueues tend to achieve better overall CPU utilization, so improve overall performance (throughput, not latency). See the attached pictures for our results (using 12x HDDs with a dual socket Xeon system/20 cores/40 CPUs). The 2 graphs are heat-maps showing the percentage difference in throughput with patch applied vs unmodified dm-crypt (higher than 100 means better with the patch applied). Bypassing the workqueues is very efficient for small IO sizes and large number of jobs as these jobs all get scheduled on different CPUs, leading to parallel use of the HW crypto accelerators without the added overhead of workqueue context switches. For a low number of jobs and high queue depth, this parallelism disappears and performance suffers. For large IO sizes, the same pattern exists, but performance also suffers for large number of jobs. While we did not deeply analyzed these results, I think that the loss comes from inefficient use of HW crypto accelerators resources, that is, lost time forcing something to be done in context while another context (i.e. another crypto accelerator) is already finished and idle. The same significant loss of performance happen with low number of jobs and high QD for the same reason as for small IOs. These tests use actual HW. Results may vary depending on the crypto cipher used. This is with aes-xts on Intel. -- Damien Le Moal Western Digital Research
Attachment:
dm-crypt-sync.png
Description: dm-crypt-sync.png
-- dm-devel mailing list dm-devel@xxxxxxxxxx https://www.redhat.com/mailman/listinfo/dm-devel

{kind=link}