|
Hi, I am Moshe Lazarov. A researcher in Axxana (https://www.axxana.com). We have developed a Black Box to for Zero Data Loss in asynchronous replications
systems. We consider integrating the LVM2 and its thinly-provisioned and snapshots mechanisms to our product.
Lately I have been running several experiments with LVs and snapshots, using LVM2 (LVM2.2.02.98) and Linux Kernel 4.9.11. The platforms which I run the tests on are VM (on Dell server carrying intel Xeon E5-2620 CPUs with 2 SAS HDDs) and Axxana’s Black Box (“BBX”); a unique motherboard carrying intel
i7-3517UE CPU and 2 SAS SSDs. Both platforms run the same scripts and tester application for creating the destinations (LVs and snapshots) and writing to them. The VG (that include all the LVs and snapshots) is
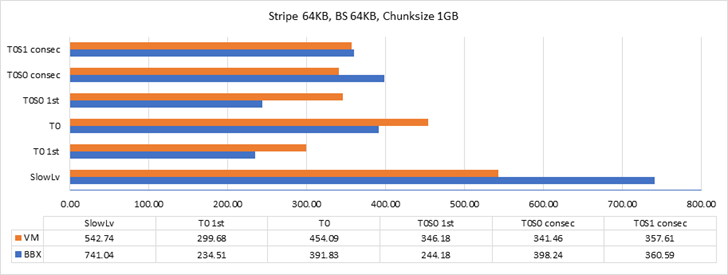
stripped (64KB) over the 2 drives. In the graph below one can see the throughput of writing 1GB (each time a different and random 1GB is written) to each of the destinations in the VM or in the BBX: SlowLV – A linear LV. T0 1st – 1st write to a thinly-provisioned LV. Since the allocation of a chunk is initiated in this access, the downgraded throughput is clear. T0 – Consecutive writes to T0 (thinly-provisioned LV). T0S0 1st – 1st write to a thinly-provisioned snapshot of T0 (the thinly-provisioned LV above). Since the allocation of a chunk is initiated in this access, the
downgraded throughput is clear. T0S0 – Consecutive writes to T0S0 (the snapshot of thinly-provisioned LV).
IMHO, the degradation of the throughput between writes to the SlowLV and writes to T0 or T0S0 is extremely high; while the BBX writes to the LV in ~740MBps, the writes to other destinations
is limited to ~400Mbps (almost 50% degradation). On the VM there ~17% degradation at least. Since both platforms run the same code and reach around the same write throughput, it seems that the SW/Kernel is the bottleneck for achieving higher throughput. What is your opinion about that? In addition, I added the output of IOSTAT while executing writes to T0 (thin-provisioned LV). The following legend applies: vg-slowlv (252:0) vg-ramlv1 (252:1) vg-ramlv2 (252:2) vg-poolThinDataLV_tmeta (252:3) vg-poolThinDataLV_tdata (252:4) vg-poolThinDataLV-tpool (252:5) vg-poolThinDataLV (252:6) vg-t0 (252:7) vg-t0s0 (252:8) 1GB of data was written during 3 IOSTAT sampling windows (samples every 1 second). See in yellow in the 2nd second window; data was written to dm-4 (poolThinDataLV_tdata)
and dm-5 (poolThinDataLV-tpool) at 557MBps, while it was written to dm-7 (t0) in 820MBps. During the 1st second window, the behavior was different; data was written to dm-4, dm-5 and dm-7 at the same throughput (average of 204MBps over this 1 second window). In other cases, data is written to the 3 destinations at the same speed during all three 1 second windows. What could be the reason for the behavior in the 2nd window? Is data really written twice to dm-4 and dm-5 (one time for each), or is it the same write? Can throughput be improved by increasing the request size (write in larger packets, how?)?
I hope the information is clear. I would appreciate your response to the questions I’ve raised above. Thanks a lot, -Moshe ---------------------------------------- Moshe Lazarov Axxana C: +1-669-213-9752 F: +972-74-7887878
|
-- dm-devel mailing list dm-devel@xxxxxxxxxx https://www.redhat.com/mailman/listinfo/dm-devel
