Gui Jianfeng wrote, on 07/14/2009 03:45 AM:
Munehiro Ikeda wrote:Vivek Goyal wrote, on 07/13/2009 12:03 PM:On Fri, Jul 10, 2009 at 09:56:21AM +0800, Gui Jianfeng wrote:Hi Vivek, This patch exports a cgroup based per group request limits interface. and removes the global one. Now we can use this interface to perform different request allocation limitation for different groups.Thanks Gui. Few points come to mind. - You seem to be making this as per cgroup limit on all devices. I guess that different devices in the system can have different settings of q->nr_requests and hence will probably want different per group limit. So we might have to make it per cgroup per device limit.From the viewpoint of implementation, there is a difficulty in my mind to implement per cgroup per device limit arising from that io_group is allocated when associated device is firstly used. I guess Gui chose per cgroup limit on all devices approach because of this, right?Yes, I choose this solution from the simplicity point of view, the code will get complicated if choosing per cgroup per device limit. But it seems per cgroup per device limits is more reasonable.- There does not seem to be any checks for making sure that children cgroups don't have more request descriptors allocated than parent group. - I am re-thinking that what's the advantage of configuring request descriptors also through cgroups. It does bring in additional complexity with it and it should justfiy the advantages. Can you think of some? Until and unless we can come up with some significant advantages, I will prefer to continue to use per group limit through q->nr_group_requests interface instead of cgroup. Once things stablize, we can revisit it and see how this interface can be improved.I agree. I will try to clarify if per group per device limitation is needed or not (or, if it has the advantage beyond the complexity) through some tests.Great, hope to hear you soon.
Sorry for so late. I tried it, and write the result and my opinion below...
Scenario ====================The possible scenario where per-cgroup nr_requests limitation is beneficial in my mind is that:
- Process P1 in cgroup "g1" is running with submitting many requests to a device. The number of the requests in the device queue is almost nr_requests for the device. - After a while, process P2 in cgroup "g2" starts running. P2 also tries to submit requests as many as P1. - Assuming that user wants P2 to grab bandwidth as soon as possible and keep it certain level.In this scenario, I predicted the bandwidth behavior of P2 along with tuning global nr_group_requests like below.
- If having nr_group_requests almost same as nr_requests, P1 can allocate requests up to nr_requests and there is no room for P2 at the beginning of its running. As a result of it, P2 has to wait for a while till P1's requests are completed and rising of bandwidth is delayed. - If having nr_group_requests fewer to restrict requests from P1 and make room for P2, the bandwidth of P2 may be lower than the case that P1 can allocate more requests.If the prediction is correct and per-cgroup nr_requests limitation can make the situation better, per-cgroup nr_requests is supposed to be beneficial.
Verification Conditions
========================
- Kernel:
2.6.31-rc1
+ Patches from Vivek on Jul 2, 2009
(IO scheduler based IO controller V6)
https://lists.linux-foundation.org/pipermail/containers/2009-July/018948.html
+ Patches from Gui Jianfeng on Jul 7, 2009 (Bug fixes)
https://lists.linux-foundation.org/pipermail/containers/2009-July/019086.html
https://lists.linux-foundation.org/pipermail/containers/2009-July/019087.html
+ Patch from Gui Jianfeng on Jul 9, 2009 (per-cgroup requests limit)
https://lists.linux-foundation.org/pipermail/containers/2009-July/019123.html
+ Patch from me on Jul 16, 2009 (Bug fix)
https://lists.linux-foundation.org/pipermail/containers/2009-July/019286.html
+ 2 local bug fix patches
(Not posted yet, I'm posting them in following mails)
- All results are measured under nr_requests=500.
- Used fio to make I/O. Job file is like below. Used libaio and
direct-I/O and tuned iodepth to make rl->count[1] approx 500 always.
----- fio job file : from here -----
[global]
size=128m
directory=/mnt/b1
runtime=30
time_based
write_bw_log
bwavgtime=200
rw=randread
direct=1
ioengine=libaio
iodepth=500
[g1]
exec_prerun=./pre.sh /mnt/cgroups/g1
exec_postrun=./log.sh /mnt/cgroups/g1 sdb "_post"
[g2]
startdelay=10
exec_prerun=./pre.sh /mnt/cgroups/g2
exec_postrun=./log.sh /mnt/cgroups/g2 sdb "_post"
----- fio job file : till here -----
Note:
pre.sh and log.sh used in exec_{pre|post}run are to assign processes
to expected cgroups and record the conditions. Let me omit the detail
of them because they are not fundamental part of this verification.
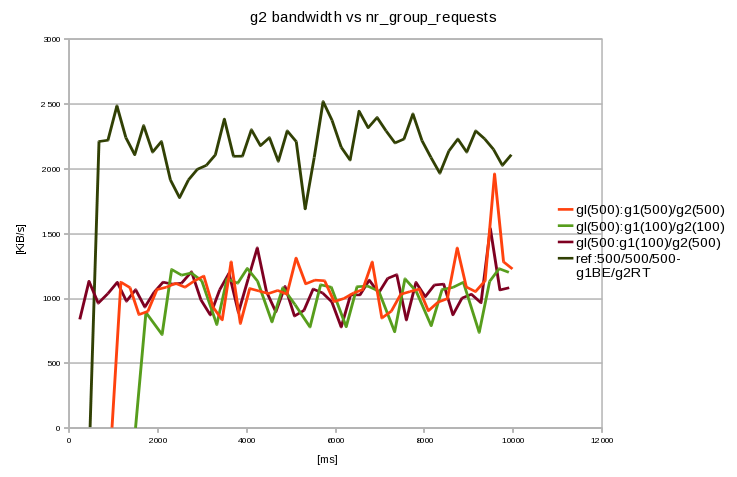
Results ====================Bandwidth of g2 (=P2) was measured under some conditions. Conditions and bandwidth logs are shown below. Bandwidth logs are shown only the beginning part (from starting of P2 to 3000[ms] after aprox.) because the full logs are so long. Average bandwidth from the beginning of log to ~10[sec] is also calculated.
Note1:fio seems to log bandwidth only when actual data transfer occurs (correct me if it's not true). This means that there is no line with BW=0. In there is no data transfer, the time-stamp are simply skipped to record.
Note2: Graph picture of the bandwidth logs is attached. Result(1): orange Result(2): green Result(3): brown Result(4): black ---------- Result (1) ---------- * Both of g1 and g2 have nr_group_requests=500 < Conditions > nr_requests = 500 g1/ io.nr_group_requests = 500 io.weight = 500 io.ioprio_class = 2 g2/ io.nr_group_requests = 500 io.weight = 500 io.ioprio_class = 2 < Bandwidth log of g2 > t [ms] bw[KiB/s] 969 4 1170 1126 1374 1084 1576 876 1776 901 1980 1069 2191 1087 2400 1117 2612 1087 2822 1136 ... < Average bandwidth > 1063 [KiB/s] (969~9979[ms]) ---------- Result (2) ---------- * Both of g1 and g2 have nr_group_requests=100 < Conditions > nr_requests = 500 g1/ io.nr_group_requests = 100 io.weight = 500 io.ioprio_class = 2 g2/ io.nr_group_requests = 100 io.weight = 500 io.ioprio_class = 2 < Bandwidth log of g2 > t [ms] bw[KiB/s] 1498 2 1733 892 2096 722 2311 1224 2534 1180 2753 1197 2988 1137 ... < Average bandwidth > 998 [KiB/s] (1498~9898[ms]) ---------- Result (3) ---------- * To set different nr_group_requests on g1 and g2 < Conditions > nr_requests = 500 g1/ io.nr_group_requests = 100 io.weight = 500 io.ioprio_class = 2 g2/ io.nr_group_requests = 500 io.weight = 500 io.ioprio_class = 2 < Bandwidth log of g2 > t [ms] bw[KiB/s] 244 839 451 1133 659 964 877 1038 1088 1125 1294 979 1501 1068 1708 934 1916 1048 2117 1126 2328 1111 2533 1118 2758 1206 2969 990 ... < Average bandwidth > 1048 [KiB/s] (244~9906[ms]) ---------- Result (4) ---------- * To make g2/io.ioprio_class as RT < Conditions > nr_requests = 500 g1/ io.nr_group_requests = 500 io.weight = 500 io.ioprio_class = 2 g2/ io.nr_group_requests = 500 io.weight = 500 io.ioprio_class = 1 < Bandwidth log of g2 > t [ms] bw[KiB/s] 476 8 677 2211 878 2221 1080 2486 1281 2241 1481 2109 1681 2334 1882 2129 2082 2211 2283 1915 2489 1778 2690 1915 2891 1997 ... < Average bandwidth > 2132[KiB/s] (476~9954[ms]) Consideration and Conclusion =============================From result(1), it is observed that it takes 1000~1200[ms] to rise P2 bandwidth. In result(2), where both of g1 and g2 have nr_group_requests=100, the delay gets longer as 1800~2000[ms]. In addition to it, the average bandwidth becomes ~5% lower than result(1). This is supposed that P2 couldn't allocate enough requests. Then, result(3) shows that bandwidth of P2 can rise quickly (~300[ms]) if nr_group_requests can be set per-cgroup. Result(4) shows that the delay can be shortened by setting g2 as RT class, however, the delay is still longer than result(3).
I think it is confirmed that "per-cgroup nr_requests limitation is useful in a certain situation". Beyond that, the discussion topic is the benefit pointed out above is eligible for the complication of the implementation. IMHO, I don't think the implementation of per-cgroup request limitation is too complicated to accept. On the other hand I guess it suddenly gets complicated if we try to implement further more, especially hierarchical support. It is also true that I have a feeling that implementation without per-device limitation and hierarchical support is like "unfinished work".
So, my opinion so far is that, per-cgroup nr_requests limitation should be merged only if hierarchical support is concluded "unnecessary" for it. If merging it tempts hierarchical support, it shouldn't be.
How about your opinion, all?My considerations or verification method might be wrong. Please correct them if any. And if you have any other idea of scenario to verify the effect of per-cgroup nr_requests limitation, please let me know. I'll try it.
--
IKEDA, Munehiro
NEC Corporation of America
m-ikeda@xxxxxxxxxxxxx
Attachment:
g2_bw.png
Description: PNG image
-- dm-devel mailing list dm-devel@xxxxxxxxxx https://www.redhat.com/mailman/listinfo/dm-devel

{kind=link}