Hi Igor and others,
(apologies for html, but i want to share a plot ;) )
We're upgrading clusters to v16.2.9 from v15.2.16, and our simple "rados bench -p test 10 write -b 4096 -t 1" latency probe showed something is very wrong with deferred writes in pacific.
I think this is related to the fixes in https://tracker.ceph.com/issues/52089 which landed in 16.2.6 -- _do_alloc_write is comparing the prealloc size 0x10000 with bluestore_prefer_deferred_size_hdd (0x10000) and the "strictly less than" condition prevents deferred writes from ever happening.
So I think this would impact anyone upgrading clusters with hdd/ssd mixed osds ... surely we must not be the only clusters impacted by this?!
Should we increase the default bluestore_prefer_deferred_size_hdd up to 128kB or is there in fact a bug here?
Best Regards,
Dan
(apologies for html, but i want to share a plot ;) )
We're upgrading clusters to v16.2.9 from v15.2.16, and our simple "rados bench -p test 10 write -b 4096 -t 1" latency probe showed something is very wrong with deferred writes in pacific.
Here is an example cluster, upgraded today:
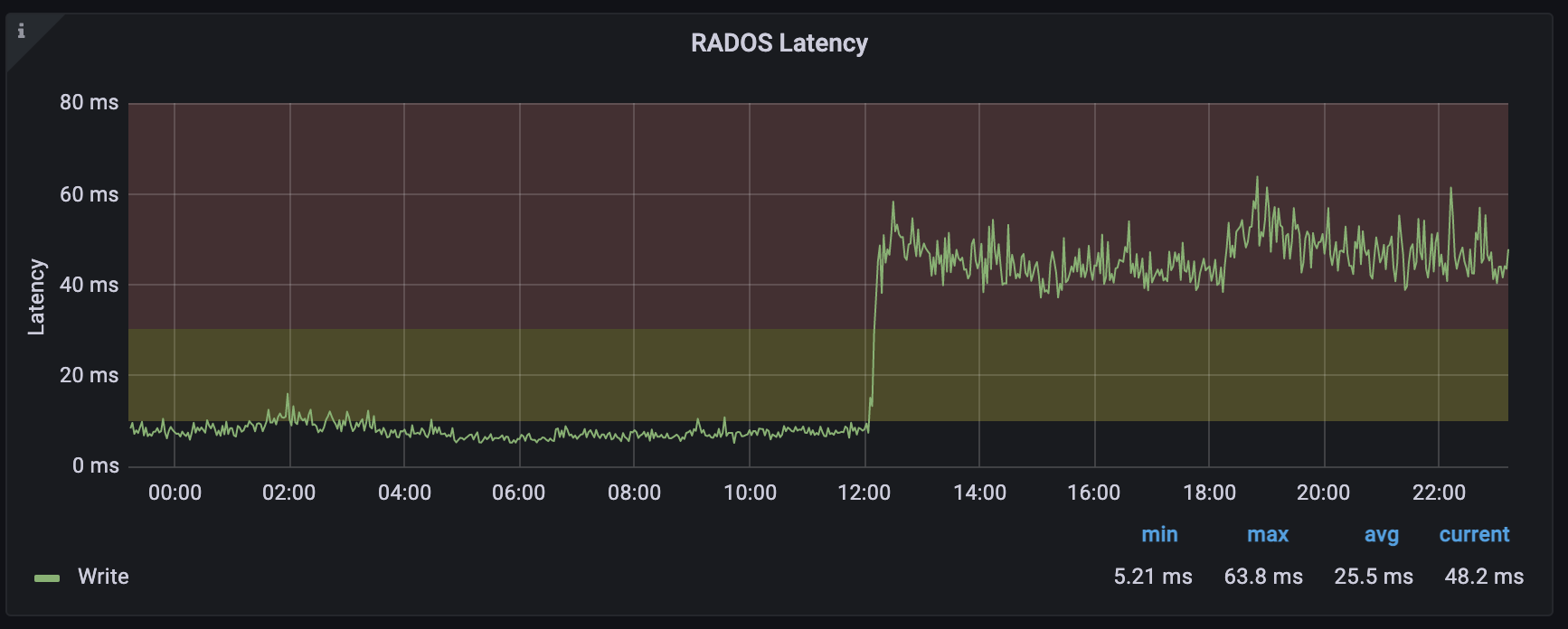
The OSDs are 12TB HDDs, formatted in nautilus with the default bluestore_min_alloc_size_hdd = 64kB, and each have a large flash block.db.
I found that the performance issue is because 4kB writes are no longer deferred from those pre-pacific hdds to flash in pacific with the default config !!!
Here are example bench writes from both releases: https://pastebin.com/raw/m0yL1H9Z
I worked out that the issue is fixed if I set bluestore_prefer_deferred_size_hdd = 128k (up from the 64k pacific default. Note the default was 32k in octopus).
I think this is related to the fixes in https://tracker.ceph.com/issues/52089 which landed in 16.2.6 -- _do_alloc_write is comparing the prealloc size 0x10000 with bluestore_prefer_deferred_size_hdd (0x10000) and the "strictly less than" condition prevents deferred writes from ever happening.
So I think this would impact anyone upgrading clusters with hdd/ssd mixed osds ... surely we must not be the only clusters impacted by this?!
Should we increase the default bluestore_prefer_deferred_size_hdd up to 128kB or is there in fact a bug here?
Best Regards,
Dan
_______________________________________________ Dev mailing list -- dev@xxxxxxx To unsubscribe send an email to dev-leave@xxxxxxx
