Thanks for your reply Greg.
In my case, client had sent at least 3074(1606847-1603773) ops to this pg during the period from osd down to pg becoming active start reprocessing the requeued op.
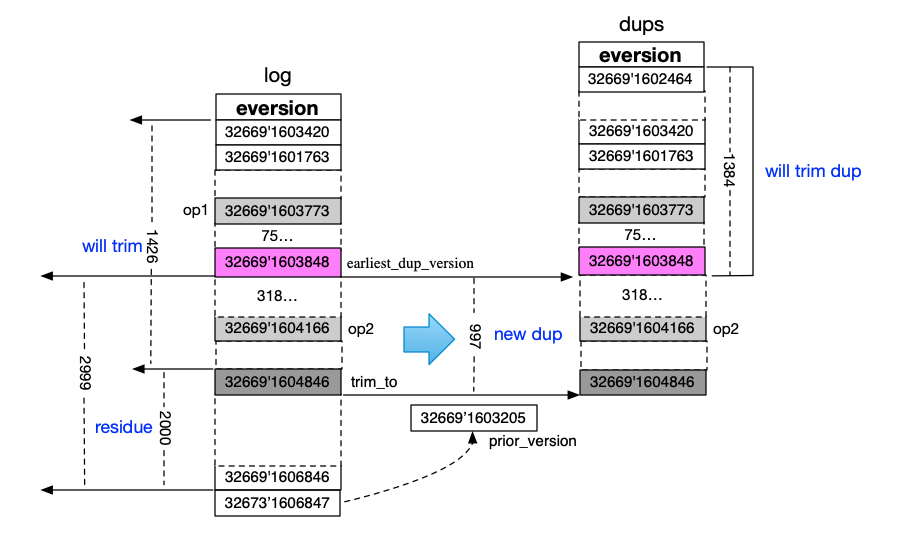
When pg log trim is coming, earliest_dup_version is 32669’1603848 and trim_to is 32669’1604846, so pg_log will trim both op1 and op2.
But unfortunately, op1 has been trimmed from dups, op2 move to dups from pg_log. So when osd reprocessing the op1 and op2, op1 can’t find in pg_log but op2
was considered already completed which lead op2 return reply firstly.
The various positions in the picture were drawn according to osd log. If the log is needed, i can upload it.
On 12/27/2021 18:08,Gregory Farnum<gfarnum@xxxxxxxxxx> wrote:
On Mon, Dec 27, 2021 at 9:12 AM gyfelectric <gyfelectric@xxxxxxxxx> wrote:Hi all,Recently, the problem of OSD disorder has often appeared in my environment(14.2.5) and my Fuse Client borkendue to "FAILED assert(ob->last_commit_tid < tid)”. My application can’t work normally now.The time series that triggered this problem is like this:note:a. my datapool is: EC 4+2b. osd(osd.x) of pg_1 is downEvent Sequences:t1: op_1(write) send to OSD and send 5 shards to 5 osds. only return 4 shards except primary osd because there is osd(osd.x) down.t2: many other operations have occurred in this pg and record in pg_logt3: op_n(write) send to OSD and send 5 shards to 5 osds. only return 4 shards except primary osd because there is osd(osd.x) down.t4: the peer osd report osd.x timeout to monitor and osd.x is marked downt5: pg_1 start canceling and requeueing op_1, op_2 … op_n to osd op_wqt6: pg_1 start peering and op_1 is trimmed from pg_log and dup map in this processUnless I’m misunderstanding, either you have more ops that haven’t been committed+acked than the length of the pg log dup tracking, or else there’s a bug here and it’s trimming farther than it should.Can you clarify which case? Because if you’re sending more ops than the pg log length, this is an expected failure and not one that’s feasible to resolve. You just need to spend the money to have enough memory for longer logs and dup detection.-Gregt7: pg_1 become active and start reprocessing the op_1, op_2 … op_nt8: op_1 is not found in pg_log and dup map, so redo it.t9: op_n is found in pg_log or dup map and be considered completed, so return osd reply to client directly with tid_op_nt10: op_1 complete and return to client with tid_op_1. client will break down due to "assert(ob->last_commit_tid < tid)”I found some relative issues in https://tracker.ceph.com/issues/23827 which have some discussions about this problem.But i didn’t find an effective method to avoid this problem.I think the current mechanism to prevent non-idempotent op from being repeated is flawed, may be we should redesign it.How do you think about it? And if my idea is wrong, what should i do to avoid this problem?Any response is very grateful, thank you!
_______________________________________________ Dev mailing list -- dev@xxxxxxx To unsubscribe send an email to dev-leave@xxxxxxx

{kind=link}