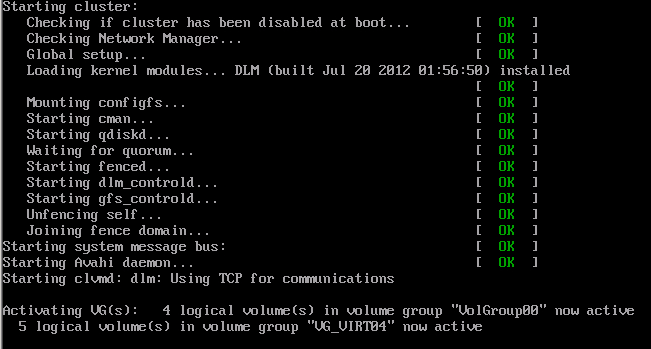
Hello, testing a three node cluster + quorum disk and clvmd. I was at CentOS 6.2 and I seem to remember to be able to start a single node. Correct? Then I upgraded to CentOS 6.3 and had a working environment. My config has <cman expected_votes="3" quorum_dev_poll="240000" two_node="0"/> At the moment two nodes are in another site that is powered down and I need to start a single node config. When the node starts it gets waiting for quorum and when quorum disk becomes master it goes ahead: # cman_tool nodes Node Sts Inc Joined Name 0 M 0 2012-08-01 15:41:58 /dev/block/253:4 1 X 0 intrarhev1 2 X 0 intrarhev2 3 M 1420 2012-08-01 15:39:58 intrarhev3 But the process hangs at clvmd start up. In particular at the step vgchange -aly Pid of "service clvmd start" command is 9335 # pstree -alp 9335 S24clvmd,9335 /etc/rc3.d/S24clvmd start └─vgchange,9363 -ayl # ll /proc/9363/fd/ total 0 lrwx------ 1 root root 64 Aug 1 15:44 0 -> /dev/console lrwx------ 1 root root 64 Aug 1 15:44 1 -> /dev/console lrwx------ 1 root root 64 Aug 1 15:44 2 -> /dev/console lrwx------ 1 root root 64 Aug 1 15:44 3 -> /dev/mapper/control lrwx------ 1 root root 64 Aug 1 15:44 4 -> socket:[1348167] lr-x------ 1 root root 64 Aug 1 15:44 5 -> /dev/dm-3 # lsof -p 9363 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME vgchange 9363 root cwd DIR 104,3 4096 2 / vgchange 9363 root rtd DIR 104,3 4096 2 / vgchange 9363 root txt REG 104,3 971464 132238 /sbin/lvm vgchange 9363 root mem REG 104,3 156872 210 /lib64/ld-2.12.so vgchange 9363 root mem REG 104,3 1918016 569 /lib64/libc-2.12.so vgchange 9363 root mem REG 104,3 22536 593 /lib64/libdl-2.12.so vgchange 9363 root mem REG 104,3 24000 832 /lib64/libdevmapper-event.so.1.02 vgchange 9363 root mem REG 104,3 124624 750 /lib64/libselinux.so.1 vgchange 9363 root mem REG 104,3 272008 2060 /lib64/libreadline.so.6.0 vgchange 9363 root mem REG 104,3 138280 2469 /lib64/libtinfo.so.5.7 vgchange 9363 root mem REG 104,3 61648 1694 /lib64/libudev.so.0.5.1 vgchange 9363 root mem REG 104,3 251112 1489 /lib64/libsepol.so.1 vgchange 9363 root mem REG 104,3 229024 1726 /lib64/libdevmapper.so.1.02 vgchange 9363 root mem REG 253,7 99158576 17029 /usr/lib/locale/locale-archive vgchange 9363 root mem REG 253,7 26060 134467 /usr/lib64/gconv/gconv-modules.cache vgchange 9363 root 0u CHR 5,1 0t0 5218 /dev/console vgchange 9363 root 1u CHR 5,1 0t0 5218 /dev/console vgchange 9363 root 2u CHR 5,1 0t0 5218 /dev/console vgchange 9363 root 3u CHR 10,58 0t0 5486 /dev/mapper/control vgchange 9363 root 4u unix 0xffff880879b309c0 0t0 1348167 socket vgchange 9363 root 5r BLK 253,3 0t143360 10773 /dev/dm-3 # strace -p 9363 Process 9363 attached - interrupt to quit read(4, multipath seems ok in general and for md=3 in particular # multipath -l /dev/mapper/mpathd mpathd (3600507630efe0b0c0000000000001181) dm-3 IBM,1750500 size=100G features='1 queue_if_no_path' hwhandler='0' wp=rw |-+- policy='round-robin 0' prio=0 status=active | |- 0:0:0:3 sdd 8:48 active undef running | `- 1:0:0:3 sdl 8:176 active undef running `-+- policy='round-robin 0' prio=0 status=enabled |- 0:0:1:3 sdq 65:0 active undef running `- 1:0:1:3 sdy 65:128 active undef running Currently I have lvm2-2.02.95-10.el6.x86_64 lvm2-cluster-2.02.95-10.el6.x86_64 startup is stuck as in image attached Logs messages: Aug 1 15:46:14 udevd[663]: worker [9379] unexpectedly returned with status 0x0100 Aug 1 15:46:14 udevd[663]: worker [9379] failed while handling '/devices/virtual/block/dm-15' dmesg DLM (built Jul 20 2012 01:56:50) installed dlm: Using TCP for communications qdiskd Aug 01 15:41:58 qdiskd Score sufficient for master operation (1/1; required=1); upgrading Aug 01 15:43:03 qdiskd Assuming master role corosync.log Aug 01 15:41:58 corosync [CMAN ] quorum device registered Aug 01 15:43:08 corosync [CMAN ] quorum regained, resuming activity Aug 01 15:43:08 corosync [QUORUM] This node is within the primary component and will provide service. Aug 01 15:43:08 corosync [QUORUM] Members[1]: 3 fenced.log Aug 01 15:43:09 fenced fenced 3.0.12.1 started Aug 01 15:43:09 fenced failed to get dbus connection dlm_controld.log Aug 01 15:43:10 dlm_controld dlm_controld 3.0.12.1 started gfs_controld.log Aug 01 15:43:11 gfs_controld gfs_controld 3.0.12.1 started Do I miss anything simple? Is it correct to say that clvmd can start only when one node is active, given that it has quorum under the cluster configuration rules set up? Or am I hitting any known bug/problem? Thanks in advance, Gianluca
Attachment:
clvms stuck.png
Description: PNG image
-- Linux-cluster mailing list Linux-cluster@xxxxxxxxxx https://www.redhat.com/mailman/listinfo/linux-cluster

{kind=link}