Hi Marc!
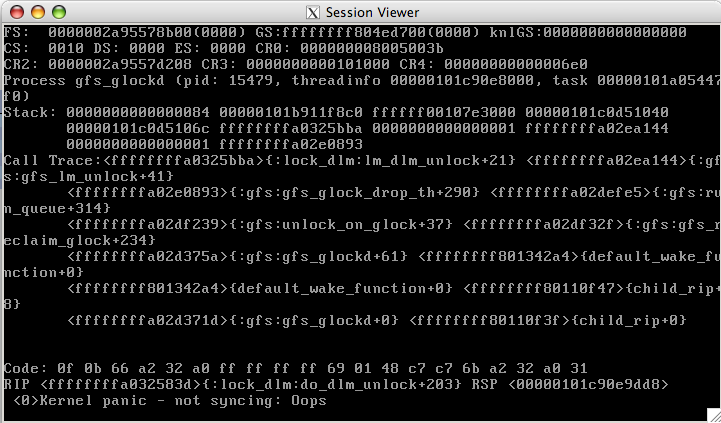
Thanks for your help. As I restarted everything now, I can't check this.
I will do when it's crahsing again (I will do some tests now). I
realised that one node did hang with kernel panic. Attached is the
screenshot.
regards
sebastian
Marc Grimme wrote:
Hello Sebastian,
what do gfs_tool counters on the fs tell you?
And ps axf? Do you have a lot of "D" processes?
Regards Marc.
On Sunday 19 August 2007 02:06:30 Sebastian Walter wrote:
Dear list,
this is the tragical story of my cluster running rhel/csgfs 4u5: the
cluster in generally is running fine, but when I increase the load to a
certain level (heavy I/O), it collapses. About 20% of the nodes do crash
(not reacting any more, but no sign of kernel panic), the others can't
access the gfs resource.
Gfs is set up as a rgmanager service with failover domain for each node
(same problem also exists when mounting via /etc/fstab).
Who is willing to provide a happy end?
Thanks, Sebastian
**
This is what /var/log/messages gives me (on nearly all nodes):
Aug 18 04:39:06 compute-0-2 clurgmgrd[4225]: <err> #49: Failed getting
status for RG gfs-2
and e.g.
Aug 18 04:45:38 compute-0-6 clurgmgrd[9074]: <err> #50: Unable to obtain
cluster lock: Connection timed out
[root@compute-0-3 ~]# cat /proc/cluster/status
Protocol version: 5.0.1
Config version: 53
Cluster name: dtm
Cluster ID: 741
Cluster Member: Yes
Membership state: Cluster-Member
Nodes: 10
Expected_votes: 11
Total_votes: 10
Quorum: 6
Active subsystems: 8
Node name: compute-0-3
Node ID: 4
Node addresses: 10.1.255.252
[root@compute-0-6 ~]# cat /proc/cluster/services
Service Name GID LID State Code
Fence Domain: "default" 3 2 recover 4 -
[1 2 6 10 9 8 3 7 4 11]
DLM Lock Space: "clvmd" 7 3 recover 0 -
[1 2 6 10 9 8 3 7 4 11]
DLM Lock Space: "Magma" 12 5 recover 0 -
[1 2 6 10 9 8 3 7 4 11]
DLM Lock Space: "homeneu" 17 6 recover 0 -
[10 9 8 7 2 3 6 4 1 11]
GFS Mount Group: "homeneu" 18 7 recover 0 -
[10 9 8 7 2 3 6 4 1 11]
User: "usrm::manager" 11 4 recover 0 -
[1 2 6 10 9 8 3 7 4 11]
[root@compute-0-10 ~]# cat /proc/cluster/dlm_stats
DLM stats (HZ=1000)
Lock operations: 4036
Unlock operations: 2001
Convert operations: 1862
Completion ASTs: 7898
Blocking ASTs: 52
Lockqueue num waittime ave
WAIT_RSB 3778 28862 7
WAIT_CONV 75 482 6
WAIT_GRANT 2171 7235 3
WAIT_UNLOCK 153 1606 10
Total 6177 38185 6
[root@compute-0-10 ~]# cat /proc/cluster/sm_debug
sevent state 7
02000012 sevent state 9
00000003 remove node 5 count 10
01000011 remove node 5 count 10
0100000c remove node 5 count 10
01000007 remove node 5 count 10
02000012 remove node 5 count 10
0300000b remove node 5 count 10
00000003 recover state 0
--
Linux-cluster mailing list
Linux-cluster@xxxxxxxxxx
https://www.redhat.com/mailman/listinfo/linux-cluster
--
Linux-cluster mailing list
Linux-cluster@xxxxxxxxxx
https://www.redhat.com/mailman/listinfo/linux-cluster
