We are programming a Maintenance Window to reboot node 1, bellow you can
find more configuration info.
Until this moment, we have had two problems that we describe like "big
problems". One of them was solved with a rgmanager update, and the other
(more extrange) was solved changing a 10/100/1000 switch for a 10/100
switch (that is the used in our producction platforms) .
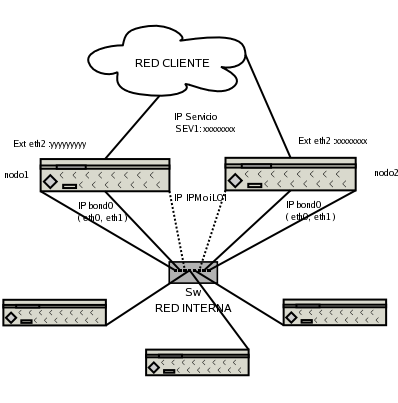
Bellow I athach too a generic diagram of this instalation. This
instalation particulary only have one switch (commonly we have two
switch for redundant)
Thanks & Regards
Luis G.
================================================================================
[root@lvs-gt1 ~]# clustat
Member Status: Quorate
Member Name Status
------ ---- ------
lvs-gt2 Offline
lvs-gt1 Online, Local, rgmanager
Service Name Owner (Last) State
------- ---- ----- ------ -----
XXX1 lvs-gt1 started
XXX2 lvs-gt1 started
[root@lvs-gt1 ~]# cman_tool status
Protocol version: 5.0.1
Config version: 10
Cluster name: lb_cluster
Cluster ID: 40372
Cluster Member: Yes
Membership state: Cluster-Member
Nodes: 1
Expected_votes: 1
Total_votes: 1
Quorum: 1
Active subsystems: 4
Node name: lvs-gt1
Node addresses: 192.168.150.21
[root@lvs-gt1 ~]# cman_tool nodes
Node Votes Exp Sts Name
1 1 1 M lvs-gt1
2 1 1 X lvs-gt2
[root@lvs-gt1 ~]# cman_tool services
Service Name GID LID State Code
Fence Domain: "default" 1 2 run -
[1]
DLM Lock Space: "Magma" 3 4 run -
[1]
User: "usrm::manager" 2 3 run -
[1]
[root@lvs-gt1 ~]# uname -a
Linux lvs-gt1 2.6.9-22.EL #1 Mon Sep 19 18:20:28 EDT 2005 i686 athlon
i386 GNU/Linux
[root@lvs-gt1 ~]# rpm -qa | grep cman
cman-kernel-2.6.9-39.5
cman-1.0.2-0
cman-kernel-hugemem-2.6.9-39.5
cman-kernheaders-2.6.9-39.5
cman-kernel-smp-2.6.9-39.5
[root@lvs-gt1 ~]# rpm -qa | grep -i ccs
ccs-1.0.2-0
[root@lvs-gt1 ~]# rpm -qa | grep -i fence
fence-1.32.6-0
[root@lvs-gt1 ~]# rpm -qa | grep -i rgma
rgmanager-1.9.53-0
OTHER NODE
==========
[root@lvs-gt1 log]# ssh lvs-gt2
Last login: Tue Mar 6 17:57:07 2007 from 172.22.22.52
[root@lvs-gt2 ~]# tail /var/log/messages
Mar 7 09:47:06 lvs-gt2 kernel: CMAN: sending membership request
Mar 7 09:47:41 lvs-gt2 last message repeated 7 times
Mar 7 09:47:56 lvs-gt2 last message repeated 3 times
Mar 7 09:47:57 lvs-gt2 sshd(pam_unix)[13006]: session opened for user
root by root(uid=0)
Mar 7 09:48:01 lvs-gt2 kernel: CMAN: sending membership request
Mar 7 09:48:01 lvs-gt2 crond(pam_unix)[12936]: session closed for user root
Mar 7 09:48:01 lvs-gt2 crond(pam_unix)[13039]: session opened for user
root by (uid=0)
Mar 7 09:48:01 lvs-gt2 su(pam_unix)[13044]: session opened for user
admin by (uid=0)
Mar 7 09:48:01 lvs-gt2 su(pam_unix)[13044]: session closed for user admin
Mar 7 09:48:06 lvs-gt2 kernel: CMAN: sending membership request
[root@lvs-gt2 ~]#
[root@lvs-gt2 ~]# clustat
Segmentation fault
[root@lvs-gt2 ~]# cman_tool status
Protocol version: 5.0.1
Config version: 10
Cluster name: lb_cluster
Cluster ID: 40372
Cluster Member: No
Membership state: Joining
Patrick Caulfield wrote:
Luis Godoy Gonzalez wrote:
Hi
The "IPtable" service is not running on both nodes.
We are thinking in update the platform (RHE4 U4 RHCS 4U4) but thid is
not easy right now because we have several servers on production.
Another reason to not do it the version update is that we are waiting
for an update 5 por RHE4 or the production release for RHE5.
In this moment we only update "rgmanager" in some sites (we have several
issues with the rgmanager of update 2 RHCS4).
It is really rather odd. Node 1 can obviously see the joinreq messages - at
least tcpdump can, but cman is either not seeing them or ignoring them.
What really bothers me is that this seems to be affecting U2 and U4 - if both of
you were using U3 I would think no more of it :)
Annoyingly it's hard to debug at this level (you can't strace a kernel thread!).
I"m pretty sure that a reboot of node1 would fix the problem but that's hardly
helpful.
--
Linux-cluster mailing list
Linux-cluster@xxxxxxxxxx
https://www.redhat.com/mailman/listinfo/linux-cluster
