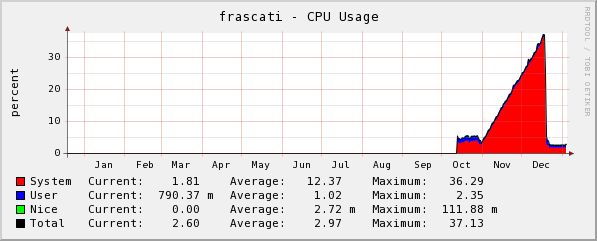
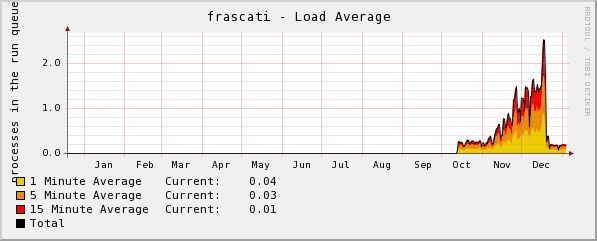
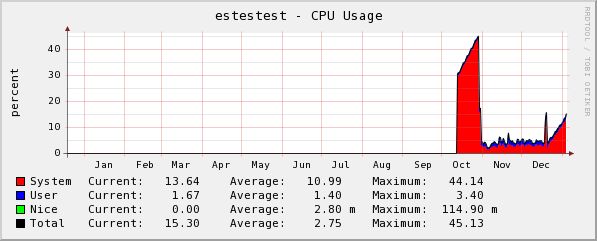
> > System load averages are the average of the number of > processes on the run queue over the past 1, 5, and 15 > minutes. It doesn't generally trend upwards over time; if > that were the case, I'd be in trouble: > I am in trouble, then :-) As I told in the first mail, as system (i.e. kernel) CPU usage grows so does the system load (1, 5, and 15 mins average). In order to better show what I see in my clusters, I am sending more graphs (on a yearly time base) that illustrate how system load trends upwards as kernel usage grows. Graphs were produced by CACTI probing the snmpd daemon running on the nodes. Again note how the trend swap from node to node on reboots. > > However, it is a little odd that you had 10 hours of runtime > for clurgmgrd and over 6 for dlm_recvd. Just taking a wild > guess, but it looks like the locks were all mastered on frascati. > How can I get more info on this? I checked /proc/cluster/dlm_locks on both nodes and it is empty. Here is the output of cat /proc/cluster/dlm_stats: [root@estestest ~]# cat /proc/cluster/dlm_stats DLM stats (HZ=1000) Lock operations: 1688738 Unlock operations: 838064 Convert operations: 0 Completion ASTs: 2526802 Blocking ASTs: 0 Lockqueue num waittime ave [root@frascati ~]# cat /proc/cluster/dlm_stats DLM stats (HZ=1000) Lock operations: 1122141 Unlock operations: 556623 Convert operations: 0 Completion ASTs: 1678764 Blocking ASTs: 0 Lockqueue num waittime ave WAIT_RSB 6 3 0 WAIT_GRANT 1122141 32507056 28 WAIT_UNLOCK 556623 316924 0 Total 1678770 32823983 19 > > How many services are you running? > At the moment I have 3 services on estestest (Sybase SQL server, a tomcat5 application and an apache web site) and 2 services on frascati (another tomcat5 application and Postgres SQL server). > Also, take a look at: > > https://bugzilla.redhat.com/bugzilla/show_bug.cgi?id=212634 > > The RPMs there might solve the problem with dlm_recvd. > Rgmanager in some situations causes a strange leak of NL > locks in the DLM. If dlm_recvd has to traverse lock lists > and that list is ever-growing (total speculation here), it > could explain the amount of consumed system time. > If I use those RPMs, will the patches be included in RHCS 4.5 (I think so, but just to be sure...)? Thanks, Marco _______________________________________________________ Messaggio analizzato e protetto da tecnologia antivirus Servizio erogato dal sistema informativo della Presidenza del Consiglio dei Ministri
Attachment:
frascati_yearly_CPU_Usage.jpg
Description: JPEG image
Attachment:
frascati_yearly_System_Load.jpg
Description: JPEG image
Attachment:
estestest_yearly_CPU_Usage.jpg
Description: JPEG image
Attachment:
estestest_yearly_System_Load.jpg
Description: JPEG image
-- Linux-cluster mailing list Linux-cluster@xxxxxxxxxx https://www.redhat.com/mailman/listinfo/linux-cluster

{kind=link}
{kind=link}
{kind=link}
{kind=link}