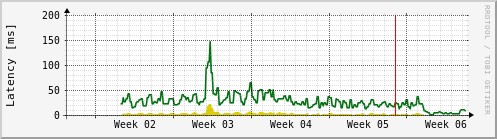
Hello, Laimis et al, sorry for the delayed reply, It took me some time to fix the latency problems of my cluster and to verify that the fix actually worked: Laimis Juzeliūnas wrote: > One amazing piece of advice for HDD disks is to disable write cache, > mentioned here by Dan: > https://youtu.be/2I_U2p-trwI?t=889; > Ceph Days NYC 2023: Ceph at CERN: A Ten-Year Retrospective > youtu.be This was quite interesting and unexpected. Thanks very much! Let me offer some details about my Ceph latency problems: As I wrote before, I used PostgreSQL number of inserts per second as a latency metrics. I observed about 200-300 transactions per second in a RBD-based VM, and about 1200 txn/s on an old bare-metal SSD server. After disabling the wcache on my HDDs I was able to get about 700-800 txn/s, which is quite impressive improvement. However: with wcache off, the latency spikes during high load became _much_ worse, PG dropping well below 10 txn/s (with wcache on, the worst spikes were around 30 txn/s). So I was really not sure whether to keep the wcache off. I tried many ways how to bang my head against the wall :-), even restarting the OSD processes, but was not able to get a measurable improvement during load spikes. If anything, I would say it became worse. What helped a bit was to find which VMs generate most I/O operations on my RBD pool and limit them either in Qemu or in RBD (the former works on virtio-scsi based drives, not in virtio-block based ones). After some time of no improvement at all, one of my Ceph nodes crashed. The next day, I noticed that %utilization of its rotational HDDs suddenly become much lower: https://www.fi.muni.cz/~kas/tmp/sda-utilization-month.png I tried to reboot another node, and its hdd %util also went down, even during PG scrubs. So I gradually rebooted the whole cluster (taking an opportunity to upgrade the kernel, system packages, and even Ceph itself to 19.2.0), and the latency went significantly down: https://www.fi.muni.cz/~kas/tmp/ceph-commit-latency-month.png The yellow area in this graph is average Ceph OSD commit latency as reported by "ceph osd perf", and the green line is the worst commit latency of all OSDs. So there was something wrong with the long-running AlmaLinux kernel, which has been "fixed" by a reboot. Oh well. We have seen something like this several months ago on a large bare-metal server running RHEL 9 - for some reaason, the storage operations went slower and slower, and only the reboot fixed this. Cheers, -Yenya > > On 3 Jan 2025, at 11:37, Jan Kasprzak <kas@xxxxxxxxxx> wrote: > > > > Hello, ceph users, > > > > TL;DR: how can I look into ceph cluster write latency issues? > > > > Details: we have a HDD-based cluster (with NVMe for metadata), > about 20 hosts, > > 2 OSD per host, mostly used as RBD storage for QEMU/KVM virtual > machines. > > From time to time our users complain about write latencies inside > their VMs. > > > > I would like to be able to see when the cluster is overloaded or when > > the write latency is bad. > > > > What did I try so far: > > > > 1) fio inside the KVM virtual machine: > > fio --ioengine=libaio --direct=1 --rw=write --numjobs=1 --bs=1M > --iodepth=16 --size=5G --name=/var/tmp/fio-test > > [...] > > write: IOPS=63, BW=63.3MiB/s (66.4MB/s)(5120MiB/80863msec); 0 > zone resets > > > > - I am usually getting about 60 to 150 IOPS for 1MB writes > > > > 2) PostgreSQL from the KVM virtual machine, running many tiny INSERTs > > as separate transactions for about 10 seconds. This is where I > clearly see > > latency spikes: > > > > Wed Dec 18 09:20:21 PM CET 2024 406.062 txn/s > > Wed Dec 18 09:25:21 PM CET 2024 318.974 txn/s > > Wed Dec 18 09:30:21 PM CET 2024 285.591 txn/s > > Wed Dec 18 09:35:21 PM CET 2024 191.804 txn/s > > Wed Dec 18 09:40:22 PM CET 2024 246.679 txn/s > > Wed Dec 18 09:45:22 PM CET 2024 201.005 txn/s > > Wed Dec 18 09:50:22 PM CET 2024 153.206 txn/s > > Wed Dec 18 09:55:22 PM CET 2024 124.546 txn/s > > Wed Dec 18 10:00:23 PM CET 2024 33.094 txn/s > > Wed Dec 18 10:05:23 PM CET 2024 82.659 txn/s > > Wed Dec 18 10:10:23 PM CET 2024 292.544 txn/s > > Wed Dec 18 10:15:24 PM CET 2024 453.366 txn/s > > > > The drawback of both fio and postgresql benchmark is that I am > > unnecessarily loading the cluster with additional work, just to > measure > > latency. And I am not covering the whole cluster, just the OSDs > on which > > that VM happens to have its own data. > > > > 3) ceph osd perf > > I don't see any single obviously overloaded OSD here, but the > latencies vary > > nevertheless. Here are statistics computed across all OSDs from > > the "ceph osd perf" output: > > > > Fri Jan 3 10:12:41 AM CET 2025 > > average 9 9 > > median 5 5 > > 3rd-q 13 13 > > max 70 70 > > Fri Jan 3 10:13:42 AM CET 2025 > > average 5 5 > > median 3 3 > > 3rd-q 10 10 > > max 31 31 > > Fri Jan 3 10:14:42 AM CET 2025 > > average 3 3 > > median 2 2 > > 3rd-q 4 4 > > max 19 19 > > Fri Jan 3 10:15:42 AM CET 2025 > > average 5 5 > > median 1 1 > > 3rd-q 3 3 > > max 63 63 > > > > However, I am not sure what exactly these numbers actually mean > > - what timespan do they cover? I would like to have something like > > "in the last 5 minutes, 99 % of all writes committed under XXX ms". > > Can Ceph tell me that? > > > > What else apart from buying faster hardware can I try in order > > to improve the write latency for QEMU/KVM-based VMs with RBD images? > > > > Thanks for any hints. > > > > -Yenya -- | Jan "Yenya" Kasprzak <kas at {fi.muni.cz - work | yenya.net - private}> | | https://www.fi.muni.cz/~kas/ GPG: 4096R/A45477D5 | We all agree on the necessity of compromise. We just can't agree on when it's necessary to compromise. --Larry Wall _______________________________________________ ceph-users mailing list -- ceph-users@xxxxxxx To unsubscribe send an email to ceph-users-leave@xxxxxxx
{kind=link}
{kind=link}
 |