A short correction:
The IOPS from the bench in out pacific cluster are also down to 40
again for the 4/8TB disks , but the apply latency seems to stay in the
same place.
But I still don't understand why it is down again. Even when I synced out the OSD so it receives 0 traffic it is still slow. After idling over night it is back up to 120 IOPS
Am Do., 30. März 2023 um 09:45 Uhr schrieb Boris Behrens <bb@xxxxxxxxx>:
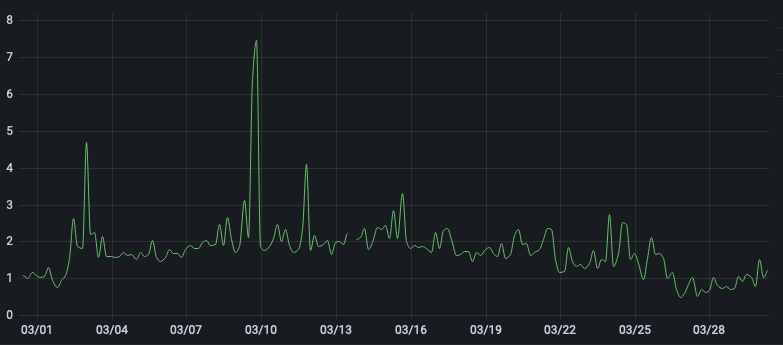
After some digging in the nautilus cluster I see that the disks with the exceptional high IOPS performance are actually SAS attached NVME disks (these: https://semiconductor.samsung.com/ssd/enterprise-ssd/pm1643-pm1643a/mzilt7t6hala-00007/ ) and these disk make around 45% of cluster capacity. Maybe this explains the very low commit latency in the nautilus cluster.I did a bench on all SATA 8TB disks (nautilus) and most all of them only have ~30-50 IOPS.After redeploying one OSD with blkdiscard the IOPS went from 48 -> 120.The IOPS from the bench in out pacific cluster are also down to 40 again for the 4/8TB disks , but the apply latency seems to stay in the same place.But I still don't understand why it is down again. Even when I synced out the OSD so it receives 0 traffic it is still slow.I am unsure how I should interpret this. It also looks like that the AVG apply latency (4h resolution) goes up again (2023-03-01 upgrade to pacific, the dip around 25th was the redeploy and now it seems to go up again)Am Mo., 27. März 2023 um 17:24 Uhr schrieb Igor Fedotov <igor.fedotov@xxxxxxxx>:
On 3/27/2023 12:19 PM, Boris Behrens wrote:
Nonetheless the IOPS the bench command generates are still VERY low compared to the nautilus cluster (~150 vs ~250). But this is something I would pin to this bug: https://tracker.ceph.com/issues/58530I've just run "ceph tell bench" against main, octopus and nautilus branches (fresh osd deployed with vstart.sh) - I don't see any difference between releases - sata drive shows around 110 IOPs in my case..
So I suspect some difference between clusters in your case. E.g. are you sure disk caching is off for both?
Feel free to update if you like but IMO we still lack the understanding what was the trigger for perf improvements in you case - OSD redeployment, disk trimming or both?@Igor do you want to me to update the ticket with my findings and the logs from pastebin?
--
Die Selbsthilfegruppe "UTF-8-Probleme" trifft sich diesmal abweichend im groüen Saal.
_______________________________________________ ceph-users mailing list -- ceph-users@xxxxxxx To unsubscribe send an email to ceph-users-leave@xxxxxxx
