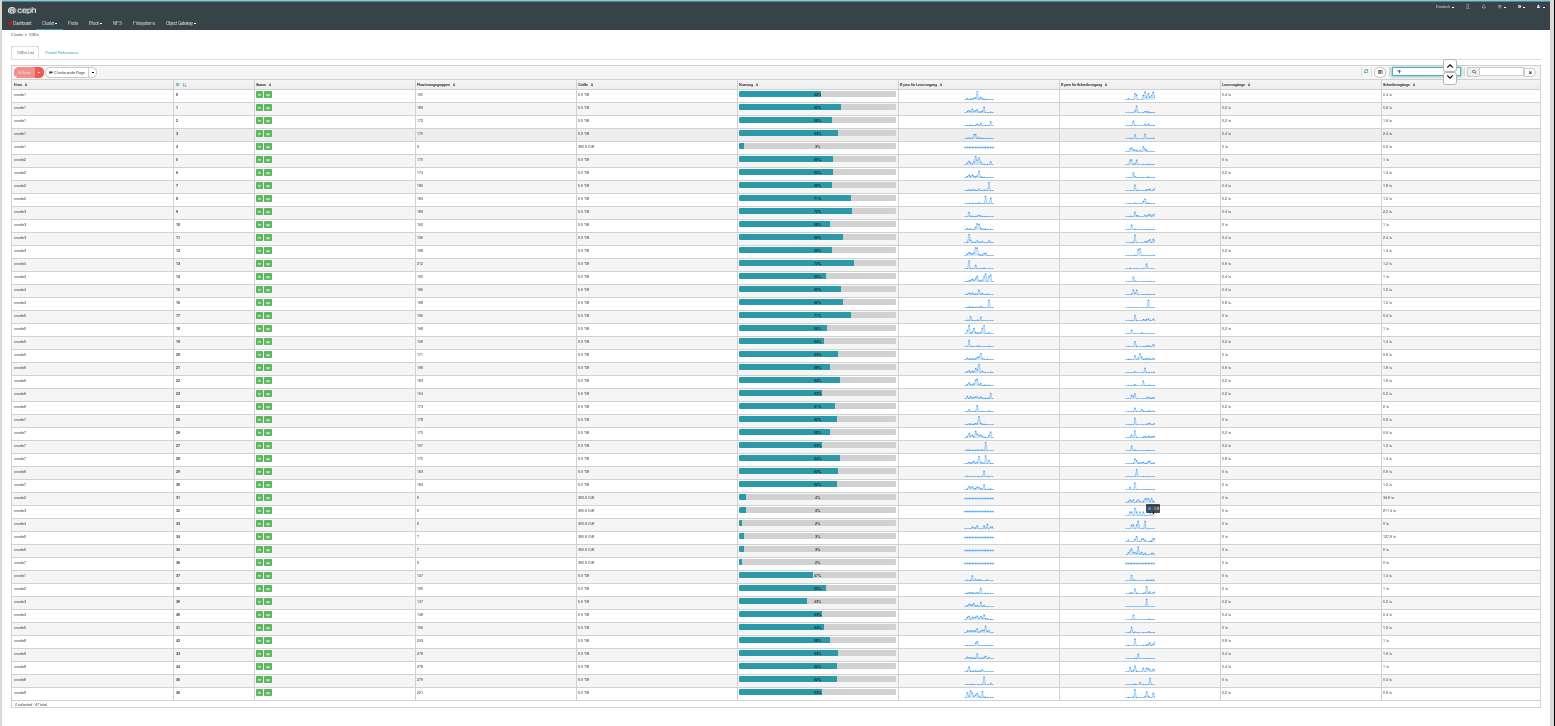
Hi Anthony! Mon, 9 Dec 2019 17:11:12 -0800 Anthony D'Atri <aad@xxxxxxxxxxxxxx> ==> ceph-users <ceph-users@xxxxxxxxxxxxxx> : > > How is that possible? I dont know how much more proof I need to present that there's a bug. > > FWIW, your pastes are hard to read with all the ? in them. Pasting non-7-bit-ASCII? I don't see much "?" in his posts. Maybe a display issue? > > |I increased PGs and see no difference. > > From what pgp_num to what new value? Numbers that are not a power of 2 can contribute to the sort of problem you describe. Do you have host CRUSH fault domain? > Does the fault domain play a role with this situation? I can't see the reason. This would only be important if the OSDs weren't evenly distributed across the hosts. Philippe can you posts your 'ceph osd tree'? > > Raising PGs to 100 is an old statement anyway, anything 60+ should be fine. > > Fine in what regard? To be sure, Wido’s advice means a *ratio* of at least 100. ratio = (pgp_num * replication) / #osds > > The target used to be 200, a commit around 12.2.1 retconned that to 100. Best I can tell the rationale is memory usage at the expense of performance. > > Is your original except complete? Ie., do you only have 24 OSDs? Across how many nodes? > > The old guidance for tiny clusters: > > • Less than 5 OSDs set pg_num to 128 > > • Between 5 and 10 OSDs set pg_num to 512 > > • Between 10 and 50 OSDs set pg_num to 1024 This is what I thought too. But in this posts https://lists.ceph.io/hyperkitty/list/ceph-users@xxxxxxx/message/TR6CJQKSMOHNGOMQO4JBDMGEL2RMWE36/ [Why are the mailing lists ceph.io and ceph.com not merged? It's hard to find the link to messages this way.] Konstantin suggested to reduce to pg_num=512. The cluster had 35 OSDs. It is still merging very slowly the PGs. In the meantime I added 5 more OSDs and thinking about rising the pg_num back to 1024. I wonder how less PGs can balance better than 512. I'm in a similar situation like Philippe with my cluster. ceph osd df class hdd: […] MIN/MAX VAR: 0.73/1.21 STDDEV: 6.27 Attached is a picture of the dashboard with tiny bars of the data distribution. The nearly empty OSDs are SSDs used for its own pool. I think there might be a bug in the balancing algorithm. Thanks, Lars
Attachment:
ceph odd balancing of data.jpg
Description: JPEG image
_______________________________________________ ceph-users mailing list ceph-users@xxxxxxxxxxxxxx http://lists.ceph.com/listinfo.cgi/ceph-users-ceph.com

{kind=link}