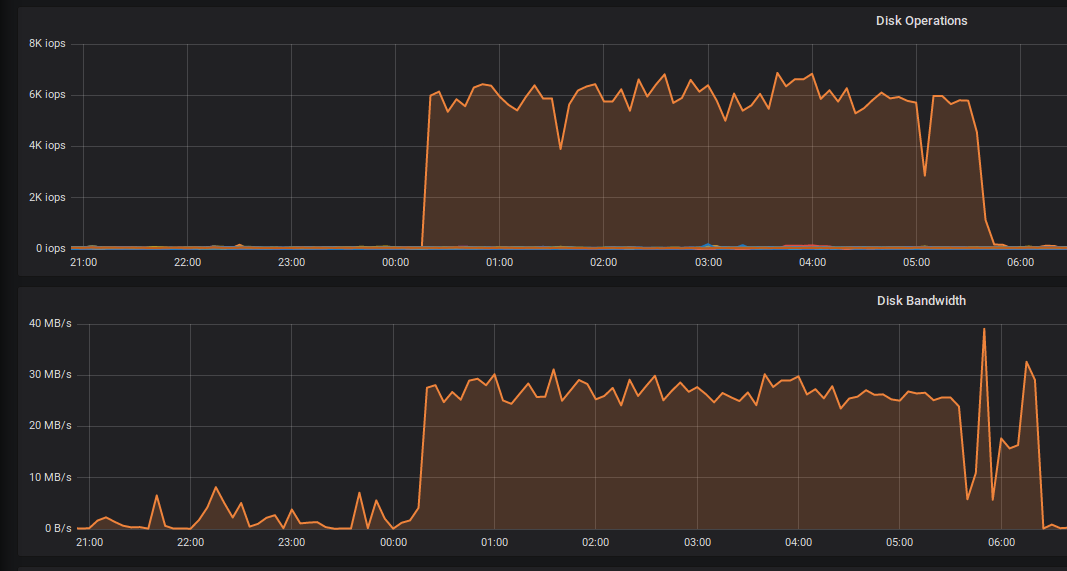
Hello, I have strange problem with scrubbing. When scrubbing starts on PG which belong to default.rgw.buckets.index pool, I can see that this OSD is very busy (see attachment), and starts showing many slow request, after the scrubbing of this PG stops, slow requests stops immediately. [root@stor-b02 /var/lib/ceph/osd/ceph-118/current]# zgrep scrub /var/log/ceph/ceph-osd.118.log.1.gz | grep -w 20.2 2019-07-03 00:14:57.496308 7fd4c7a09700 0 log_channel(cluster) log [DBG] : 20.2 deep-scrub starts 2019-07-03 05:36:13.274637 7fd4ca20e700 0 log_channel(cluster) log [DBG] : 20.2 deep-scrub ok [root@stor-b02 /var/lib/ceph/osd/ceph-118/current]# [root@stor-b02 /var/lib/ceph/osd/ceph-118/current]# du -sh 20.2_* 636K 20.2_head 0 20.2_TEMP [root@stor-b02 /var/lib/ceph/osd/ceph-118/current]# ls -1 -R 20.2_head | wc -l 4125 [root@stor-b02 /var/lib/ceph/osd/ceph-118/current]# and on mon: 2019-07-03 00:48:44.793893 mon.ceph-mon-01 mon.0 10.10.8.221:6789/0 6231090 : cluster [WRN] Health check failed: 105 slow requests are blocked > 32 sec. Implicated osds 118 (REQUEST_SLOW) 2019-07-03 00:48:54.086446 mon.ceph-mon-01 mon.0 10.10.8.221:6789/0 6231097 : cluster [WRN] Health check update: 102 slow requests are blocked > 32 sec. Implicated osds 118 (REQUEST_SLOW) 2019-07-03 00:48:59.088240 mon.ceph-mon-01 mon.0 10.10.8.221:6789/0 6231099 : cluster [WRN] Health check update: 91 slow requests are blocked > 32 sec. Implicated osds 118 (REQUEST_SLOW) [...] 2019-07-03 05:36:19.695586 mon.ceph-mon-01 mon.0 10.10.8.221:6789/0 6243211 : cluster [INF] Health check cleared: REQUEST_SLOW (was: 23 slow requests are blocked > 32 sec. Implicated osds 118) 2019-07-03 05:36:19.695700 mon.ceph-mon-01 mon.0 10.10.8.221:6789/0 6243212 : cluster [INF] Cluster is now healthy ceph version 12.2.9 it might be related to this (taken from: https://ceph.com/releases/v12-2-11-luminous-released/) ? : " There have been fixes to RGW dynamic and manual resharding, which no longer leaves behind stale bucket instances to be removed manually. For finding and cleaning up older instances from a reshard a radosgw-admin command reshard stale-instances list and reshard stale-instances rm should do the necessary cleanup. " -- Regads Lukasz
Attachment:
scrub.png
Description: PNG image
_______________________________________________ ceph-users mailing list ceph-users@xxxxxxxxxxxxxx http://lists.ceph.com/listinfo.cgi/ceph-users-ceph.com

{kind=link}