Hi,
I can ping from anyone of the servers to other servers
without a packet lost and the average round trip time
is under 0.1 ms.
Thanks
Ashley Merrick <singapore@xxxxxxxxxxxxxx> 于2019年3月13日周三 下午12:06写道:
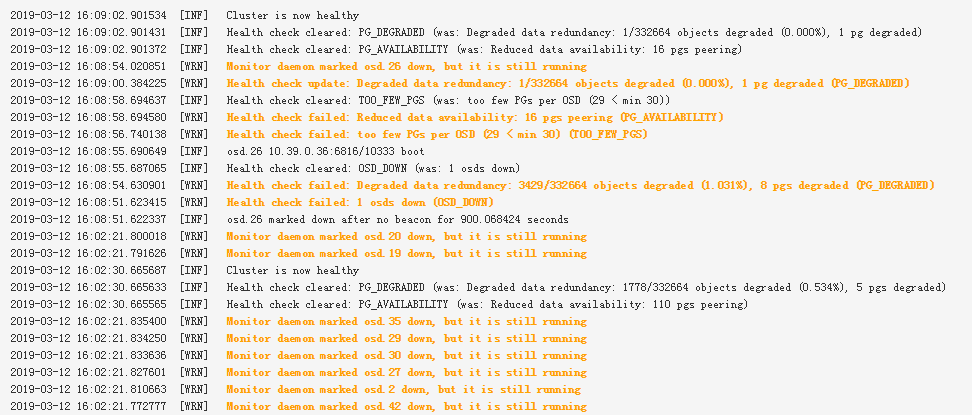
Can you ping all your OSD servers from all your mons, and ping your mons from all your OSD servers?I’ve seen this where a route wasn’t working one direction, so it made OSDs flap when it used that mon to check availability:On Wed, 13 Mar 2019 at 11:50 AM, Zhenshi Zhou <deaderzzs@xxxxxxxxx> wrote:After checking the network and syslog/dmsg, I think it's not the network or hardware issue. Now there're someosds being marked down every 15 minutes.here is ceph.log:2019-03-13 11:06:26.290701 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6756 : cluster [INF] Cluster is now healthy2019-03-13 11:21:21.705787 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6757 : cluster [INF] osd.1 marked down after no beacon for 900.067020 seconds2019-03-13 11:21:21.705858 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6758 : cluster [INF] osd.2 marked down after no beacon for 900.067020 seconds2019-03-13 11:21:21.705920 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6759 : cluster [INF] osd.4 marked down after no beacon for 900.067020 seconds2019-03-13 11:21:21.705957 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6760 : cluster [INF] osd.6 marked down after no beacon for 900.067020 seconds2019-03-13 11:21:21.705999 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6761 : cluster [INF] osd.7 marked down after no beacon for 900.067020 seconds2019-03-13 11:21:21.706040 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6762 : cluster [INF] osd.10 marked down after no beacon for 900.067020 seconds2019-03-13 11:21:21.706079 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6763 : cluster [INF] osd.11 marked down after no beacon for 900.067020 seconds2019-03-13 11:21:21.706118 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6764 : cluster [INF] osd.12 marked down after no beacon for 900.067020 seconds2019-03-13 11:21:21.706155 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6765 : cluster [INF] osd.13 marked down after no beacon for 900.067020 seconds2019-03-13 11:21:21.706195 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6766 : cluster [INF] osd.14 marked down after no beacon for 900.067020 seconds2019-03-13 11:21:21.706233 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6767 : cluster [INF] osd.15 marked down after no beacon for 900.067020 seconds2019-03-13 11:21:21.706273 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6768 : cluster [INF] osd.16 marked down after no beacon for 900.067020 seconds2019-03-13 11:21:21.706312 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6769 : cluster [INF] osd.17 marked down after no beacon for 900.067020 seconds2019-03-13 11:21:21.706351 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6770 : cluster [INF] osd.18 marked down after no beacon for 900.067020 seconds2019-03-13 11:21:21.706385 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6771 : cluster [INF] osd.19 marked down after no beacon for 900.067020 seconds2019-03-13 11:21:21.706423 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6772 : cluster [INF] osd.20 marked down after no beacon for 900.067020 seconds2019-03-13 11:21:21.706503 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6773 : cluster [INF] osd.22 marked down after no beacon for 900.067020 seconds2019-03-13 11:21:21.706549 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6774 : cluster [INF] osd.23 marked down after no beacon for 900.067020 seconds2019-03-13 11:21:21.706587 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6775 : cluster [INF] osd.25 marked down after no beacon for 900.067020 seconds2019-03-13 11:21:21.706625 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6776 : cluster [INF] osd.26 marked down after no beacon for 900.067020 seconds2019-03-13 11:21:21.706665 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6777 : cluster [INF] osd.27 marked down after no beacon for 900.067020 seconds2019-03-13 11:21:21.706703 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6778 : cluster [INF] osd.28 marked down after no beacon for 900.067020 seconds2019-03-13 11:21:21.706741 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6779 : cluster [INF] osd.30 marked down after no beacon for 900.067020 seconds2019-03-13 11:21:21.706779 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6780 : cluster [INF] osd.31 marked down after no beacon for 900.067020 seconds2019-03-13 11:21:21.706817 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6781 : cluster [INF] osd.33 marked down after no beacon for 900.067020 seconds2019-03-13 11:21:21.706856 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6782 : cluster [INF] osd.34 marked down after no beacon for 900.067020 seconds2019-03-13 11:21:21.706894 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6783 : cluster [INF] osd.36 marked down after no beacon for 900.067020 seconds2019-03-13 11:21:21.706930 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6784 : cluster [INF] osd.38 marked down after no beacon for 900.067020 seconds2019-03-13 11:21:21.706974 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6785 : cluster [INF] osd.40 marked down after no beacon for 900.067020 seconds2019-03-13 11:21:21.707013 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6786 : cluster [INF] osd.41 marked down after no beacon for 900.067020 seconds2019-03-13 11:21:21.707051 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6787 : cluster [INF] osd.42 marked down after no beacon for 900.067020 seconds2019-03-13 11:21:21.707090 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6788 : cluster [INF] osd.44 marked down after no beacon for 900.067020 seconds2019-03-13 11:21:21.707128 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6789 : cluster [INF] osd.45 marked down after no beacon for 900.067020 seconds2019-03-13 11:21:21.707166 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6790 : cluster [INF] osd.46 marked down after no beacon for 900.067020 seconds2019-03-13 11:21:21.707204 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6791 : cluster [INF] osd.48 marked down after no beacon for 900.067020 seconds2019-03-13 11:21:21.707242 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6792 : cluster [INF] osd.49 marked down after no beacon for 900.067020 seconds2019-03-13 11:21:21.707279 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6793 : cluster [INF] osd.50 marked down after no beacon for 900.067020 seconds2019-03-13 11:21:21.707317 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6794 : cluster [INF] osd.51 marked down after no beacon for 900.067020 seconds2019-03-13 11:21:21.707357 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6795 : cluster [INF] osd.53 marked down after no beacon for 900.067020 seconds2019-03-13 11:21:21.707396 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6796 : cluster [INF] osd.54 marked down after no beacon for 900.067020 seconds2019-03-13 11:21:21.707435 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6797 : cluster [INF] osd.56 marked down after no beacon for 900.067020 seconds2019-03-13 11:21:21.707488 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6798 : cluster [INF] osd.59 marked down after no beacon for 900.067020 seconds2019-03-13 11:21:21.707533 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6799 : cluster [INF] osd.61 marked down after no beacon for 900.067020 seconds2019-03-13 11:21:21.711989 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6800 : cluster [WRN] Health check failed: 43 osds down (OSD_DOWN)2019-03-13 11:21:21.843542 osd.15 osd.15 10.39.0.35:6808/541558 157 : cluster [WRN] Monitor daemon marked osd.15 down, but it is still running2019-03-13 11:21:21.711989 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6800 : cluster [WRN] Health check failed: 43 osds down (OSD_DOWN)2019-03-13 11:21:21.843542 osd.15 osd.15 10.39.0.35:6808/541558 157 : cluster [WRN] Monitor daemon marked osd.15 down, but it is still running2019-03-13 11:21:22.723955 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6802 : cluster [INF] osd.15 10.39.0.35:6808/541558 boot2019-03-13 11:21:22.724094 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6803 : cluster [INF] osd.51 10.39.0.39:6802/561995 boot2019-03-13 11:21:22.724177 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6804 : cluster [INF] osd.45 10.39.0.39:6800/561324 boot2019-03-13 11:21:22.724220 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6805 : cluster [INF] osd.1 10.39.0.34:6801/546469 boot2019-03-13 11:21:22.724260 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6806 : cluster [INF] osd.17 10.39.0.35:6806/541774 boot2019-03-13 11:21:22.724300 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6807 : cluster [INF] osd.50 10.39.0.39:6828/561887 boot2019-03-13 11:21:22.724348 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6808 : cluster [INF] osd.25 10.39.0.36:6804/548005 boot2019-03-13 11:21:22.724392 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6809 : cluster [INF] osd.13 10.39.0.35:6800/541337 boot2019-03-13 11:21:22.724438 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6810 : cluster [INF] osd.59 10.39.0.40:6807/570951 boot2019-03-13 11:21:22.724511 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6811 : cluster [INF] osd.53 10.39.0.39:6816/562213 boot2019-03-13 11:21:22.724555 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6812 : cluster [INF] osd.19 10.39.0.36:6802/547356 boot2019-03-13 11:21:22.724597 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6813 : cluster [INF] osd.26 10.39.0.36:6816/548112 boot2019-03-13 11:21:22.724647 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6814 : cluster [INF] osd.27 10.39.0.37:6803/547560 boot2019-03-13 11:21:22.724688 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6815 : cluster [INF] osd.2 10.39.0.34:6808/546587 boot2019-03-13 11:21:22.724742 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6816 : cluster [INF] osd.7 10.39.0.34:6802/547173 boot2019-03-13 11:21:22.724787 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6817 : cluster [INF] osd.40 10.39.0.38:6805/552745 boot2019-03-13 11:21:22.724839 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6818 : cluster [INF] osd.36 10.39.0.38:6814/552289 boot2019-03-13 11:21:22.724890 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6819 : cluster [INF] osd.54 10.39.0.40:6802/570399 boot2019-03-13 11:21:22.724941 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6820 : cluster [INF] osd.46 10.39.0.39:6807/561444 boot2019-03-13 11:21:22.724989 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6821 : cluster [INF] osd.28 10.39.0.37:6808/547680 boot2019-03-13 11:21:22.725075 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6822 : cluster [INF] osd.41 10.39.0.38:6802/552890 boot2019-03-13 11:21:22.725121 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6823 : cluster [INF] osd.20 10.39.0.36:6812/547465 boot2019-03-13 11:21:22.725160 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6824 : cluster [INF] osd.42 10.39.0.38:6832/553002 boot2019-03-13 11:21:22.725203 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6825 : cluster [INF] osd.61 10.39.0.40:6801/571166 boot2019-03-13 11:21:22.725257 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6826 : cluster [INF] osd.18 10.39.0.36:6805/547240 boot2019-03-13 11:21:22.725299 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6827 : cluster [INF] osd.22 10.39.0.36:6800/547682 boot2019-03-13 11:21:22.725362 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6828 : cluster [INF] osd.49 10.39.0.39:6805/561776 boot2019-03-13 11:21:22.725412 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6829 : cluster [INF] osd.12 10.39.0.35:6802/541229 boot2019-03-13 11:21:22.725484 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6830 : cluster [INF] osd.34 10.39.0.37:6802/548338 boot2019-03-13 11:21:22.725560 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6831 : cluster [INF] osd.23 10.39.0.36:6810/547790 boot2019-03-13 11:21:22.725609 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6832 : cluster [INF] osd.16 10.39.0.35:6801/541666 boot2019-03-13 11:21:22.725662 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6833 : cluster [INF] osd.56 10.39.0.40:6829/570623 boot2019-03-13 11:21:22.725753 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6834 : cluster [INF] osd.48 10.39.0.39:6806/561666 boot2019-03-13 11:21:22.725818 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6835 : cluster [INF] osd.33 10.39.0.37:6810/548230 boot2019-03-13 11:21:22.725868 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6836 : cluster [INF] osd.30 10.39.0.37:6829/547901 boot2019-03-13 11:21:22.725976 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6837 : cluster [INF] osd.6 10.39.0.34:6805/547049 boot2019-03-13 11:21:22.726022 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6838 : cluster [INF] osd.4 10.39.0.34:6822/546816 boot2019-03-13 11:21:21.849960 osd.10 osd.10 10.39.0.35:6824/540996 155 : cluster [WRN] Monitor daemon marked osd.10 down, but it is still running2019-03-13 11:21:21.853594 osd.1 osd.1 10.39.0.34:6801/546469 165 : cluster [WRN] Monitor daemon marked osd.1 down, but it is still running2019-03-13 11:21:21.862261 osd.53 osd.53 10.39.0.39:6816/562213 153 : cluster [WRN] Monitor daemon marked osd.53 down, but it is still running2019-03-13 11:21:21.863580 osd.50 osd.50 10.39.0.39:6828/561887 155 : cluster [WRN] Monitor daemon marked osd.50 down, but it is still running2019-03-13 11:21:22.765514 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6840 : cluster [WRN] Health check failed: Reduced data availability: 38 pgs inactive, 78 pgs peering (PG_AVAILABILITY)2019-03-13 11:21:22.765574 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6841 : cluster [WRN] Health check failed: too few PGs per OSD (28 < min 30) (TOO_FEW_PGS)2019-03-13 11:21:23.726065 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6842 : cluster [INF] Health check cleared: OSD_DOWN (was: 6 osds down)2019-03-13 11:21:23.729961 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6843 : cluster [INF] osd.11 10.39.0.35:6805/541106 boot2019-03-13 11:21:23.731669 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6844 : cluster [INF] osd.10 10.39.0.35:6824/540996 boot2019-03-13 11:21:23.731789 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6845 : cluster [INF] osd.14 10.39.0.35:6804/541448 boot2019-03-13 11:21:23.731859 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6846 : cluster [INF] osd.44 10.39.0.38:6800/553222 boot2019-03-13 11:21:23.731926 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6847 : cluster [INF] osd.31 10.39.0.37:6807/548009 boot2019-03-13 11:21:23.731975 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6848 : cluster [INF] osd.38 10.39.0.38:6801/552512 boot2019-03-13 11:21:21.842413 osd.12 osd.12 10.39.0.35:6802/541229 157 : cluster [WRN] Monitor daemon marked osd.12 down, but it is still running2019-03-13 11:21:21.851780 osd.7 osd.7 10.39.0.34:6802/547173 157 : cluster [WRN] Monitor daemon marked osd.7 down, but it is still running2019-03-13 11:21:21.852501 osd.4 osd.4 10.39.0.34:6822/546816 163 : cluster [WRN] Monitor daemon marked osd.4 down, but it is still running2019-03-13 11:21:21.853408 osd.19 osd.19 10.39.0.36:6802/547356 155 : cluster [WRN] Monitor daemon marked osd.19 down, but it is still running2019-03-13 11:21:21.860298 osd.25 osd.25 10.39.0.36:6804/548005 155 : cluster [WRN] Monitor daemon marked osd.25 down, but it is still running2019-03-13 11:21:21.860945 osd.44 osd.44 10.39.0.38:6800/553222 155 : cluster [WRN] Monitor daemon marked osd.44 down, but it is still running2019-03-13 11:21:21.844427 osd.11 osd.11 10.39.0.35:6805/541106 159 : cluster [WRN] Monitor daemon marked osd.11 down, but it is still running2019-03-13 11:21:21.848239 osd.56 osd.56 10.39.0.40:6829/570623 161 : cluster [WRN] Monitor daemon marked osd.56 down, but it is still running2019-03-13 11:21:21.854657 osd.59 osd.59 10.39.0.40:6807/570951 151 : cluster [WRN] Monitor daemon marked osd.59 down, but it is still running2019-03-13 11:21:24.772150 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6851 : cluster [WRN] Health check failed: Degraded data redundancy: 420/332661 objects degraded (0.126%), 1 pg degraded (PG_DEGRADED)2019-03-13 11:21:21.840603 osd.30 osd.30 10.39.0.37:6829/547901 169 : cluster [WRN] Monitor daemon marked osd.30 down, but it is still running2019-03-13 11:21:21.850658 osd.16 osd.16 10.39.0.35:6801/541666 161 : cluster [WRN] Monitor daemon marked osd.16 down, but it is still running2019-03-13 11:21:21.852257 osd.40 osd.40 10.39.0.38:6805/552745 157 : cluster [WRN] Monitor daemon marked osd.40 down, but it is still running2019-03-13 11:21:21.854963 osd.48 osd.48 10.39.0.39:6806/561666 145 : cluster [WRN] Monitor daemon marked osd.48 down, but it is still running2019-03-13 11:21:21.861335 osd.42 osd.42 10.39.0.38:6832/553002 151 : cluster [WRN] Monitor daemon marked osd.42 down, but it is still running2019-03-13 11:21:21.861593 osd.22 osd.22 10.39.0.36:6800/547682 159 : cluster [WRN] Monitor daemon marked osd.22 down, but it is still running2019-03-13 11:21:21.845502 osd.54 osd.54 10.39.0.40:6802/570399 147 : cluster [WRN] Monitor daemon marked osd.54 down, but it is still running2019-03-13 11:21:21.848701 osd.14 osd.14 10.39.0.35:6804/541448 159 : cluster [WRN] Monitor daemon marked osd.14 down, but it is still running2019-03-13 11:21:21.854024 osd.51 osd.51 10.39.0.39:6802/561995 157 : cluster [WRN] Monitor daemon marked osd.51 down, but it is still running2019-03-13 11:21:21.858817 osd.26 osd.26 10.39.0.36:6816/548112 165 : cluster [WRN] Monitor daemon marked osd.26 down, but it is still running2019-03-13 11:21:21.859382 osd.6 osd.6 10.39.0.34:6805/547049 161 : cluster [WRN] Monitor daemon marked osd.6 down, but it is still running2019-03-13 11:21:21.862837 osd.45 osd.45 10.39.0.39:6800/561324 145 : cluster [WRN] Monitor daemon marked osd.45 down, but it is still running2019-03-13 11:21:21.871469 osd.13 osd.13 10.39.0.35:6800/541337 157 : cluster [WRN] Monitor daemon marked osd.13 down, but it is still running2019-03-13 11:21:21.841995 osd.33 osd.33 10.39.0.37:6810/548230 165 : cluster [WRN] Monitor daemon marked osd.33 down, but it is still running2019-03-13 11:21:21.848627 osd.28 osd.28 10.39.0.37:6808/547680 157 : cluster [WRN] Monitor daemon marked osd.28 down, but it is still running2019-03-13 11:21:21.860501 osd.20 osd.20 10.39.0.36:6812/547465 159 : cluster [WRN] Monitor daemon marked osd.20 down, but it is still running2019-03-13 11:21:22.050876 osd.23 osd.23 10.39.0.36:6810/547790 161 : cluster [WRN] Monitor daemon marked osd.23 down, but it is still running2019-03-13 11:21:21.853694 osd.38 osd.38 10.39.0.38:6801/552512 153 : cluster [WRN] Monitor daemon marked osd.38 down, but it is still running2019-03-13 11:21:21.863745 osd.49 osd.49 10.39.0.39:6805/561776 153 : cluster [WRN] Monitor daemon marked osd.49 down, but it is still running2019-03-13 11:21:28.784280 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6852 : cluster [WRN] Health check update: Reduced data availability: 38 pgs peering (PG_AVAILABILITY)2019-03-13 11:21:28.784332 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6853 : cluster [INF] Health check cleared: PG_DEGRADED (was: Degraded data redundancy: 420/332661 objects degraded (0.126%), 1 pg degraded)2019-03-13 11:21:28.784372 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6854 : cluster [INF] Health check cleared: TOO_FEW_PGS (was: too few PGs per OSD (28 < min 30))2019-03-13 11:21:21.839907 osd.27 osd.27 10.39.0.37:6803/547560 151 : cluster [WRN] Monitor daemon marked osd.27 down, but it is still running2019-03-13 11:21:21.840611 osd.31 osd.31 10.39.0.37:6807/548009 151 : cluster [WRN] Monitor daemon marked osd.31 down, but it is still running2019-03-13 11:21:21.842664 osd.17 osd.17 10.39.0.35:6806/541774 157 : cluster [WRN] Monitor daemon marked osd.17 down, but it is still running2019-03-13 11:21:21.846408 osd.61 osd.61 10.39.0.40:6801/571166 159 : cluster [WRN] Monitor daemon marked osd.61 down, but it is still running2019-03-13 11:21:21.859087 osd.2 osd.2 10.39.0.34:6808/546587 157 : cluster [WRN] Monitor daemon marked osd.2 down, but it is still running2019-03-13 11:21:21.861856 osd.46 osd.46 10.39.0.39:6807/561444 155 : cluster [WRN] Monitor daemon marked osd.46 down, but it is still running2019-03-13 11:21:21.843770 osd.34 osd.34 10.39.0.37:6802/548338 151 : cluster [WRN] Monitor daemon marked osd.34 down, but it is still running2019-03-13 11:21:21.845353 osd.18 osd.18 10.39.0.36:6805/547240 165 : cluster [WRN] Monitor daemon marked osd.18 down, but it is still running2019-03-13 11:21:21.860607 osd.41 osd.41 10.39.0.38:6802/552890 157 : cluster [WRN] Monitor daemon marked osd.41 down, but it is still running2019-03-13 11:21:21.861365 osd.36 osd.36 10.39.0.38:6814/552289 159 : cluster [WRN] Monitor daemon marked osd.36 down, but it is still running2019-03-13 11:21:30.790492 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6855 : cluster [INF] Health check cleared: PG_AVAILABILITY (was: Reduced data availability: 38 pgs peering)2019-03-13 11:21:30.790549 mon.ceph-mon1 mon.0 10.39.0.34:6789/0 6856 : cluster [INF] Cluster is now healthyand the ceph-osd.2.log:2019-03-13 11:21:21.857 7fd39aefc700 0 log_channel(cluster) log [WRN] : Monitor daemon marked osd.2 down, but it is still running2019-03-13 11:21:21.857 7fd39aefc700 0 log_channel(cluster) log [DBG] : map e13907 wrongly marked me down at e139072019-03-13 11:21:21.857 7fd39aefc700 1 osd.2 13907 start_waiting_for_healthy.....2019-03-13 11:21:21.865 7fd39aefc700 1 osd.2 13907 is_healthy false -- only 0/10 up peers (less than 33%)2019-03-13 11:21:21.865 7fd39aefc700 1 osd.2 13907 not healthy; waiting to boot.....2019-03-13 11:21:22.293 7fd3a8f18700 1 osd.2 13907 start_boot2019-03-13 11:21:22.725 7fd39aefc700 1 osd.2 13908 state: booting -> activeZhenshi Zhou <deaderzzs@xxxxxxxxx> 于2019年3月12日周二 下午6:08写道:_______________________________________________Hi Kevin,I'm sure the firewalld are disabled on each host.Well, the network is not a problem. The servers are connectedto the same switch and the connection is good when the osdsare marked as down. There was no interruption or delay.I restart the leader monitor daemon and it seems return to thenormal state.Thanks.Kevin Olbrich <ko@xxxxxxx> 于2019年3月12日周二 下午5:44写道:Are you sure that firewalld is stopped and disabled?Looks exactly like that when I missed one host in a test cluster.KevinAm Di., 12. März 2019 um 09:31 Uhr schrieb Zhenshi Zhou <deaderzzs@xxxxxxxxx>:_______________________________________________Hi,I deployed a ceph cluster with good performance. But the logsindicate that the cluster is not as stable as I think it should be.The log shows the monitors mark some osd as down periodly:I didn't find any useful information in osd logs.ceph version 13.2.4 mimic (stable)OS version CentOS 7.6.1810kernel version 5.0.0-2.el7Thanks.
ceph-users mailing list
ceph-users@xxxxxxxxxxxxxx
http://lists.ceph.com/listinfo.cgi/ceph-users-ceph.com
ceph-users mailing list
ceph-users@xxxxxxxxxxxxxx
http://lists.ceph.com/listinfo.cgi/ceph-users-ceph.com
_______________________________________________ ceph-users mailing list ceph-users@xxxxxxxxxxxxxx http://lists.ceph.com/listinfo.cgi/ceph-users-ceph.com
