On Mon, Feb 19, 2018 at 9:29 PM, nokia ceph <nokiacephusers@xxxxxxxxx> wrote:
Hi Alfredo Deza,We have 5 node platforms with lvm osd created from scratch and another 5 node platform migrated from kraken which is ceph volume simple. Both has same issue . Both platform has only hdd for osd.We also noticed 2 times disk iops more compare to kraken , this causes less read performance. During rocksdb compaction the situation is worse.Meanwhile we are building another platform creating osd using ceph-disk and analyse on this.
If you have two platforms, one with `simple` and the other one with `lvm` experiencing the same, then something else must be at fault here.
The `simple` setup in ceph-volume basically keeps everything as it was before, it just captures details of what devices were being used so OSDs can be started. There is no interaction from ceph-volume
in there that could cause something like this.
Thanks,Muthu
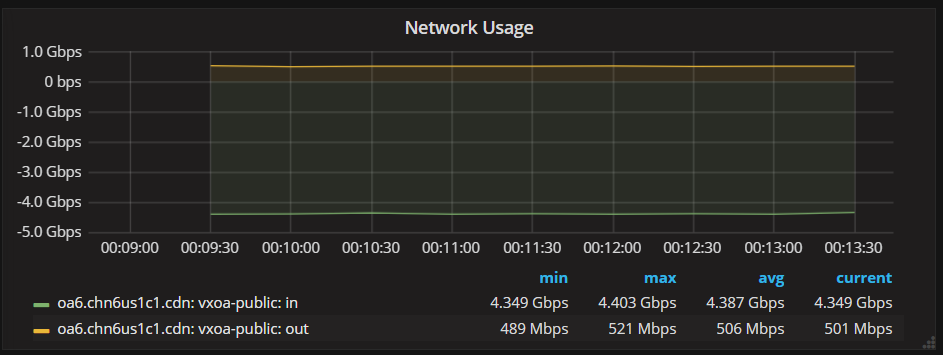
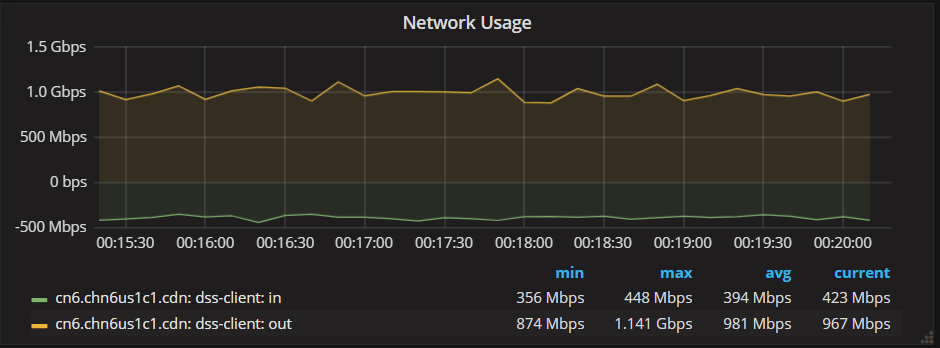
On Tuesday, February 20, 2018, Alfredo Deza <adeza@xxxxxxxxxx> wrote:On Mon, Feb 19, 2018 at 2:01 PM, nokia ceph <nokiacephusers@xxxxxxxxx> wrote:Client network interface towards ceph public interface : shows 4.3Gbps readSome network graphs :Now we see two times more traffic in read compare to client traffic on migrated platform and newly created platforms . This was not the case in older releases where ceph status read B/W will be same as client read traffic.Recently we migrated all our platforms to luminous 12.2.2 and finally all OSDs migrated to ceph-volume simple type and on few platforms installed ceph using ceph-volume .Hi All,We have 5 node clusters with EC 4+1 and use bluestore since last year from Kraken.Ceph Node Public interface : Each node around 960Mbps * 5 node = 4.6 Gbps - this matches.Ceph status output : show 1032 MB/s = 8.06 Gbps
cn6.chn6us1c1.cdn ~# ceph status
cluster:
id: abda22db-3658-4d33-9681-e3ff10690f88
health: HEALTH_OK
services:
mon: 5 daemons, quorum cn6,cn7,cn8,cn9,cn10
mgr: cn6(active), standbys: cn7, cn9, cn10, cn8
osd: 340 osds: 340 up, 340 in
data:
pools: 1 pools, 8192 pgs
objects: 270M objects, 426 TB
usage: 581 TB used, 655 TB / 1237 TB avail
pgs: 8160 active+clean
32 active+clean+scrubbing
io:
client: 1032 MB/s rd, 168 MB/s wr, 1908 op/s rd, 1594 op/s wrWrite operation we don't see this issue. Client traffic and this matches.
Is this expected behavior in Luminous and ceph-volume lvm or a bug ?Wrong calculation in ceph status read B/W ?You mentioned `ceph-volume simple` but here you say lvm. With LVM ceph-volume will create the OSDs from scratch, while "simple" will keep whatever OSD was created before.Have you created the OSDs from scratch with ceph-volume? or is it just using "simple" , managing a previously deployed OSD?Please provide your feedback.Thanks,Muthu
_______________________________________________
ceph-users mailing list
ceph-users@xxxxxxxxxxxxxx
http://lists.ceph.com/listinfo.cgi/ceph-users-ceph.com
_______________________________________________ ceph-users mailing list ceph-users@xxxxxxxxxxxxxx http://lists.ceph.com/listinfo.cgi/ceph-users-ceph.com
