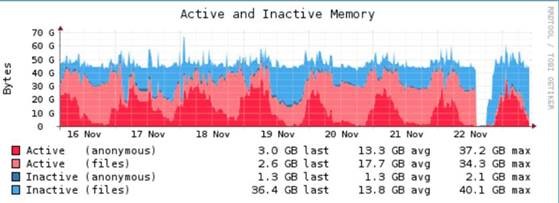
I know this may be a bit vague, but also suggests the "try a newer kernel" approach. We had constant problems with hosts mounting a number of RBD volumes formatted with XFS. The servers would start aggressively swapping even though the actual memory in use was nowhere near even 50% and eventually processes started dying/hanging (Not OOM though). I couldn't quite put my finger on what was actually using the memory, but it looked almost like the page cache was not releasing memory when requested. This was happening on the 4.10 kernel, updated to 4.14 and the problem completely disappeared. I've attached a graph (if it gets through) showing the memory change between 4.10 and 4.14 on the 22nd Nov Nick > -----Original Message----- > From: ceph-users [mailto:ceph-users-bounces@xxxxxxxxxxxxxx] On Behalf Of > Warren Wang > Sent: 24 January 2018 17:54 > To: Blair Bethwaite <blair.bethwaite@xxxxxxxxx> > Cc: ceph-users@xxxxxxxxxxxxxx > Subject: Re: OSD servers swapping despite having free memory > capacity > > Forgot to mention another hint. If kswapd is constantly using CPU, and your sar - > r ALL and sar -B stats look like it's trashing, kswapd is probably busy evicting > things from memory in order to make a larger order allocation. > > The other thing I can think of is if you have OSDs locking up and getting > corrupted, there is a severe XFS bug where the kernel will throw a NULL pointer > dereference under heavy memory pressure. Again, it's due to memory issues, > but you will see the message in your kernel logs. It's fixed in upstream kernels as > of this month. I forget what version exactly. 4.4.0-102? > https://launchpad.net/bugs/1729256 > > Warren Wang > > On 1/23/18, 11:01 PM, "Blair Bethwaite" <blair.bethwaite@xxxxxxxxx> wrote: > > +1 to Warren's advice on checking for memory fragmentation. Are you > seeing kmem allocation failures in dmesg on these hosts? > > On 24 January 2018 at 10:44, Warren Wang <Warren.Wang@xxxxxxxxxxx> > wrote: > > Check /proc/buddyinfo for memory fragmentation. We have some pretty > severe memory frag issues with Ceph to the point where we keep excessive > min_free_kbytes configured (8GB), and are starting to order more memory than > we actually need. If you have a lot of objects, you may find that you need to > increase vfs_cache_pressure as well, to something like the default of 100. > > > > In your buddyinfo, the columns represent the quantity of each page size > available. So if you only see numbers in the first 2 columns, you only have 4K and > 8K pages available, and will fail any allocations larger than that. The problem is > so severe for us that we have stopped using jumbo frames due to dropped > packets as a result of not being able to DMA map pages that will fit 9K frames. > > > > In short, you might have enough memory, but not contiguous. It's even > worse on RGW nodes. > > > > Warren Wang > > > > On 1/23/18, 2:56 PM, "ceph-users on behalf of Samuel Taylor Liston" <ceph- > users-bounces@xxxxxxxxxxxxxx on behalf of sam.liston@xxxxxxxx> wrote: > > > > We have a 9 - node (16 - 8TB OSDs per node) running jewel on centos 7.4. > The OSDs are configured with encryption. The cluster is accessed via two - > RGWs and there are 3 - mon servers. The data pool is using 6+3 erasure coding. > > > > About 2 weeks ago I found two of the nine servers wedged and had to > hard power cycle them to get them back. In this hard reboot 22 - OSDs came > back with either a corrupted encryption or data partitions. These OSDs were > removed and recreated, and the resultant rebalance moved along just fine for > about a week. At the end of that week two different nodes were unresponsive > complaining of page allocation failures. This is when I realized the nodes were > heavy into swap. These nodes were configured with 64GB of RAM as a cost > saving going against the 1GB per 1TB recommendation. We have since then > doubled the RAM in each of the nodes giving each of them more than the 1GB > per 1TB ratio. > > > > The issue I am running into is that these nodes are still swapping; a lot, > and over time becoming unresponsive, or throwing page allocation failures. As > an example, “free” will show 15GB of RAM usage (out of 128GB) and 32GB of > swap. I have configured swappiness to 0 and and also turned up the > vm.min_free_kbytes to 4GB to try to keep the kernel happy, and yet I am still > filling up swap. It only occurs when the OSDs have mounted partitions and ceph- > osd daemons active. > > > > Anyone have an idea where this swap usage might be coming from? > > Thanks for any insight, > > > > Sam Liston (sam.liston@xxxxxxxx) > > ==================================== > > Center for High Performance Computing > > 155 S. 1452 E. Rm 405 > > Salt Lake City, Utah 84112 (801)232-6932 > > ==================================== > > > > > > > > _______________________________________________ > > ceph-users mailing list > > ceph-users@xxxxxxxxxxxxxx > > http://lists.ceph.com/listinfo.cgi/ceph-users-ceph.com > > > > > > _______________________________________________ > > ceph-users mailing list > > ceph-users@xxxxxxxxxxxxxx > > http://lists.ceph.com/listinfo.cgi/ceph-users-ceph.com > > > > -- > Cheers, > ~Blairo > > > _______________________________________________ > ceph-users mailing list > ceph-users@xxxxxxxxxxxxxx > http://lists.ceph.com/listinfo.cgi/ceph-users-ceph.com
Attachment:
kernel mem bug.jpg
Description: JPEG image
_______________________________________________ ceph-users mailing list ceph-users@xxxxxxxxxxxxxx http://lists.ceph.com/listinfo.cgi/ceph-users-ceph.com

{kind=link}