Hello list,
I'm looking for some more information relating to CephFS and the 'Q' size, specifically how to diagnose what contributes towards it rising up
Ceph Version: 11.2.0.0
OS: CentOS 7
Kernel (Ceph Servers): 3.10.0-514.10.2.el7.x86_64
Kernel (CephFS Clients): 4.4.76-1.el7.elrepo.x86_64 - using kernel mount
Storage: 8 OSD Servers, 2TB NVME (P3700) in front of 6 x 6TB Disks (bcache)
2 pools for CephFS
pool 1 'cephfs_data' replicated size 3 min_size 2 crush_ruleset 0 object_hash rjenkins pg_num 8192 pgp_num 8192 last_change 1984 flags hashpspool crash_replay_interval 45 stripe_width 0
pool 2 'cephfs_metadata' replicated size 3 min_size 2 crush_ruleset 0 object_hash rjenkins pg_num 256 pgp_num 256 last_change 40695 flags hashpspool stripe_width 0
Average client IO is between 1000-2000 op/s and 150-200MB/s
We track the q size attribute coming out of ceph daemon /var/run/ceph/<socket> perf dump mds q into prometheus on a regular basis and this figure is always northbound of 5K
When we run into performance issues/sporadic failovers of the MDS servers this figure is the warning sign and normally peaks at >50K prior to an issue occuring
I've attached a sample graph showing the last 12 hours of the q figure as an example
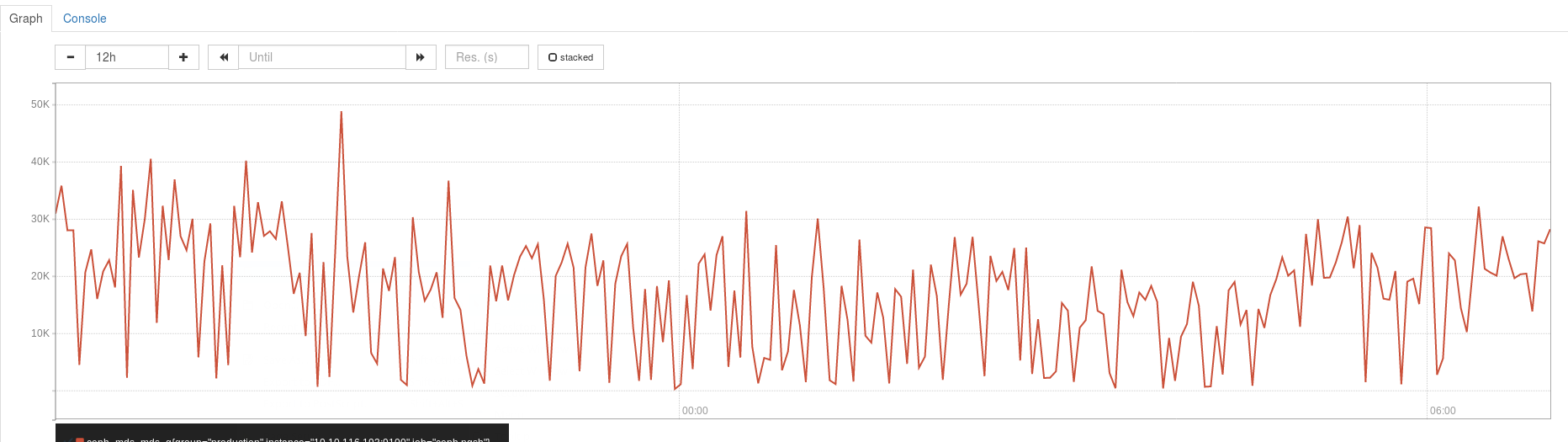
Does anyone have any suggestions as to where we look at what is causing this Q size?
Attachment:
signature.asc
Description: This is a digitally signed message part
_______________________________________________ ceph-users mailing list ceph-users@xxxxxxxxxxxxxx http://lists.ceph.com/listinfo.cgi/ceph-users-ceph.com
