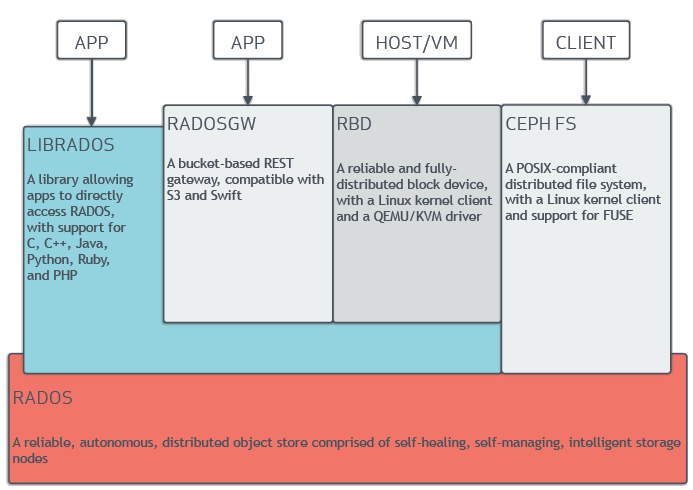
As I parse Youssef’s message, I believe there are some misconceptions. It might help if you could give a bit more info on what your existing ‘cluster’ is running. NFS? CIFS/SMB? Something else? 1) Ceph regularly runs scrubs to ensure that all copies of data are consistent. The checksumming that you describe would be both infeasible and redundant. 2) It sounds as though your current back-end stores user files as-is and is either a traditional file server setup or perhaps a virtual filesystem aggregating multiple filesystems. Ceph is not a file storage solution in this sense. The below sounds as though you want user files to not be sharded across multiple servers. This is antithetical to how Ceph works and is counter to data durability and availability, unless there is some replication that you haven’t described. Reference this diagram: Beneath the hood Ceph operates internally on ‘objects’ that are not exposed to clients as such. There are several different client interfaces that are built on top of this block service: - RBD volumes — think in terms of a virtual disk drive attached to a VM - RGW — like Amazon S3 or Swift - CephFS — provides a mountable filesystem interface, somewhat like NFS or even SMB but with important distictions in behavior and use-case I had not heard of iRODS before but just looked it up. It is a very different thing than any of the common interfaces to Ceph. If your users need to mount the storage as a share / volume, in the sense of SMB or NFS, then Ceph may not be your best option. If they can cope with an S3 / Swift type REST object interface, a cluster with RGW interfaces might do the job, or perhaps Swift or Gluster. It’s hard to say for sure based on assumptions of what you need. — Anthony We currently run a commodity cluster that supports a few petabytes of data. Each node in the cluster has 4 drives, currently mounted as /0 through /3. We have been researching alternatives for managing the storage, Ceph being one possibility, iRODS being another. For preservation purposes, we would like each file to exist as one whole piece per drive (as opposed to being striped across multiple drives). It appears this is the default in Ceph. |
_______________________________________________ ceph-users mailing list ceph-users@xxxxxxxxxxxxxx http://lists.ceph.com/listinfo.cgi/ceph-users-ceph.com

{kind=link}