Dear John,
Thank for your respone.
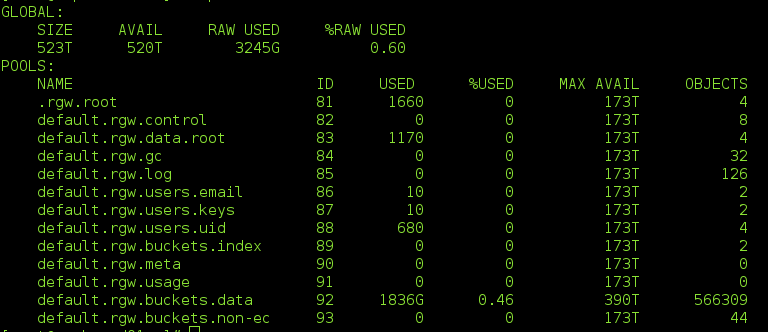

My cluster have 4616 pgs and 13 pools show as below:
in which default.rgw.buckets.data is erasure pool with config:
+ pg_num=pgp_num=1792
+ size=12
+ erause-code-profile:
directory=/usr/lib64/ceph/erasure-code
k=9
m=3
plugin=isa
ruleset-failure-domain=osd
ruleset-root=default
And all of other pools as: rgw.root, default.rgw.control ... are replication pools with pg_num=pgp_num=256 and size=3.
These configurations above can affect system resources?
Here is my memory info:
Thank,
2017-02-15 19:00 GMT+07:00 John Petrini <jpetrini@xxxxxxxxxxxx>:
You should subtract buffers and cache from the used memory to get a more accurate representation of how much memory is actually available to processes. In this case that puts you around 22G of used - or a better term might be unavailable memory. Buffers and cache can be reallocated when needed - it's just Linux taking advantage of memory under the theory why not use it if it's there? Memory is fast so Linux will take advantage of it.With 72 OSD's 22G of memory puts you below the 500MB/daemon that you've mentioned so I don't think you have anything to be concerned about.___
John Petrini
The information transmitted is intended only for the person or entity to which it is addressed and may contain confidential and/or privileged material. Any review, retransmission, dissemination or other use of, or taking of any action in reliance upon, this information by persons or entities other than the intended recipient is prohibited. If you received this in error, please contact the sender and delete the material from any computer.
On Tue, Feb 14, 2017 at 11:24 PM, Khang Nguyễn Nhật <nguyennhatkhang2704@xxxxxxxxx> wrote:Hi Sam,Thank for your reply. I use BTRFS file system on OSDs.Here is result of "free -hw":total used free shared buffers cache availableMem: 125G 58G 31G 1.2M 3.7M 36G 60Gand "ceph df":GLOBAL:SIZE AVAIL RAW USED %RAW USED523T 522T 1539G 0.29POOLS:NAME ID USED %USED MAX AVAIL OBJECTS............default.rgw.buckets.data 92 597G 0.15 391T 84392............I was reviced this a few minutes ago.2017-02-15 10:50 GMT+07:00 Sam Huracan <nowitzki.sammy@xxxxxxxxx>:Hi Khang,What file system do you use in OSD node?XFS always use Memory for caching data before writing to disk.So, don't worry, it always holds memory in your system as much as possible.2017-02-15 10:35 GMT+07:00 Khang Nguyễn Nhật <nguyennhatkhang2704@xxxxxxxxx> :______________________________Hi all,My ceph OSDs is running on Fedora-server24 with config are:128GB RAM DDR3, CPU Intel(R) Xeon(R) CPU E5-2680 v2 @ 2.80GHz, 72 OSDs (8TB per OSD). My cluster was use ceph object gateway with S3 API. Now, it had contained 500GB data but it was used > 50GB RAM. I'm worry my OSD will dead if i continue put file to it. I had read "OSDs do not require as much RAM for regular operations (e.g., 500MB of RAM per daemon instance); however, during recovery they need significantly more RAM (e.g., ~1GB per 1TB of storage per daemon)." in Ceph Hardware Recommendations. Someone can give me advice on this issue? Thank_________________
ceph-users mailing list
ceph-users@xxxxxxxxxxxxxx
http://lists.ceph.com/listinfo.cgi/ceph-users-ceph.com
_______________________________________________
ceph-users mailing list
ceph-users@xxxxxxxxxxxxxx
http://lists.ceph.com/listinfo.cgi/ceph-users-ceph.com
_______________________________________________ ceph-users mailing list ceph-users@xxxxxxxxxxxxxx http://lists.ceph.com/listinfo.cgi/ceph-users-ceph.com
