Hi cephers.
I need your help for some issues.
The ceph cluster version is Jewel(10.2.1), and the filesytem is btrfs.
I run 1 Mon and 48 OSD in 4 Nodes(each node has 12 OSDs).
I've experienced one of OSDs was killed himself.
Always it issued suicide timeout message.
Below is detailed logs.
==================================================================
0. ceph df detail
$ sudo ceph df detail
GLOBAL:
SIZE AVAIL RAW USED %RAW USED OBJECTS
42989G 24734G 18138G 42.19 23443k
POOLS:
NAME ID CATEGORY QUOTA OBJECTS QUOTA BYTES USED %USED MAX AVAIL OBJECTS DIRTY READ WRITE RAW USED
ha-pool 40 - N/A N/A 1405G 9.81 5270G 22986458 22447k 0 22447k 4217G
volumes 45 - N/A N/A 4093G 28.57 5270G 933401 911k 648M 649M 12280G
images 46 - N/A N/A 53745M 0.37 5270G 6746 6746 1278k 21046 157G
backups 47 - N/A N/A 0 0 5270G 0 0 0 0 0
vms 48 - N/A N/A 309G 2.16 5270G 79426 79426 92612k 46506k 928G
1. ceph no.15 log
(20:02 first timed out message)
2016-07-08 20:02:01.049483 7fcd3caa5700 1 heartbeat_map is_healthy 'OSD::osd_op_tp thread 0x7fcd2c284700' had timed out after 15
2016-07-08 20:02:01.050403 7fcd3b2a2700 1 heartbeat_map is_healthy 'OSD::osd_op_tp thread 0x7fcd2c284700' had timed out after 15
2016-07-08 20:02:01.086792 7fcd3b2a2700 1 heartbeat_map is_healthy 'OSD::osd_op_tp thread 0x7fcd2c284700' had timed out after 15
.
.
(sometimes this logs with..)
2016-07-08 20:02:11.379597 7fcd4d8f8700 0 log_channel(cluster) log [WRN] : 12 slow requests, 5 included below; oldest blocked for > 30.269577 secs
2016-07-08 20:02:11.379608 7fcd4d8f8700 0 log_channel(cluster) log [WRN] : slow request 30.269577 seconds old, received at 2016-07-08 20:01:41.109937: osd_op(client.895668.0:5302745 45.e2e779c2 rbd_data.cc460bc7fc8f.00000000000004d8 [stat,write 2596864~516096] snapc 0=[] ack+ondisk+write+known_if_redirected e30969) currently commit_sent
2016-07-08 20:02:11.379612 7fcd4d8f8700 0 log_channel(cluster) log [WRN] : slow request 30.269108 seconds old, received at 2016-07-08 20:01:41.110406: osd_op(client.895668.0:5302746 45.e2e779c2 rbd_data.cc460bc7fc8f.00000000000004d8 [stat,write 3112960~516096] snapc 0=[] ack+ondisk+write+known_if_redirected e30969) currently waiting for rw locks
2016-07-08 20:02:11.379630 7fcd4d8f8700 0 log_channel(cluster) log [WRN] : slow request 30.268607 seconds old, received at 2016-07-08 20:01:41.110907: osd_op(client.895668.0:5302747 45.e2e779c2 rbd_data.cc460bc7fc8f.00000000000004d8 [stat,write 3629056~516096] snapc 0=[] ack+ondisk+write+known_if_redirected e30969) currently waiting for rw locks
2016-07-08 20:02:11.379633 7fcd4d8f8700 0 log_channel(cluster) log [WRN] : slow request 30.268143 seconds old, received at 2016-07-08 20:01:41.111371: osd_op(client.895668.0:5302748 45.e2e779c2 rbd_data.cc460bc7fc8f.00000000000004d8 [stat,write 4145152~516096] snapc 0=[] ack+ondisk+write+known_if_redirected e30969) currently waiting for rw locks
2016-07-08 20:02:11.379636 7fcd4d8f8700 0 log_channel(cluster) log [WRN] : slow request 30.267662 seconds old, received at 2016-07-08 20:01:41.111852: osd_op(client.895668.0:5302749 45.e2e779c2 rbd_data.cc460bc7fc8f.00000000000004d8 [stat,write 4661248~516096] snapc 0=[] ack+ondisk+write+known_if_redirected e30969) currently waiting for rw locks
.
.
(after a lot of same messages)
2016-07-08 20:03:53.682828 7fcd3caa5700 1 heartbeat_map is_healthy 'OSD::osd_op_tp thread 0x7fcd2d286700' had timed out after 15
2016-07-08 20:03:53.682828 7fcd3caa5700 1 heartbeat_map is_healthy 'OSD::osd_op_tp thread 0x7fcd2da87700' had timed out after 15
2016-07-08 20:03:53.682829 7fcd3caa5700 1 heartbeat_map is_healthy 'FileStore::op_tp thread 0x7fcd48716700' had timed out after 60
2016-07-08 20:03:53.682830 7fcd3caa5700 1 heartbeat_map is_healthy 'FileStore::op_tp thread 0x7fcd47f15700' had timed out after 60
.
.
(fault with nothing to send, going to standby massages)
2016-07-08 20:03:53.708665 7fcd15787700 0 -- 10.200.10.145:6818/6462 >> 10.200.10.146:6806/4642 pipe(0x55818727e000 sd=276 :51916 s=2 pgs=2225 cs=1 l=0 c=0x558186f61d80).fault with nothing to send, going to standby
2016-07-08 20:03:53.724928 7fcd072c2700 0 -- 10.200.10.145:6818/6462 >> 10.200.10.146:6800/4336 pipe(0x55818a25b400 sd=109 :6818 s=2 pgs=2440 cs=13 l=0 c=0x55818730f080).fault with nothing to send, going to standby
2016-07-08 20:03:53.738216 7fcd0b7d3700 0 -- 10.200.10.145:6818/6462 >> 10.200.10.144:6814/5069 pipe(0x55816c6a4800 sd=334 :53850 s=2 pgs=43 cs=1 l=0 c=0x55818611f800).fault with nothing to send, going to standby
2016-07-08 20:03:53.739698 7fcd16f9f700 0 -- 10.200.10.145:6818/6462 >> 10.200.10.144:6810/4786 pipe(0x558189e9b400 sd=55 :54650 s=2 pgs=1 cs=1 l=0 c=0x558184f7b000).fault with nothing to send, going to standby
.
.
(after all, the OSD killed himself)
2016-07-08 20:04:13.254472 7fcd52c50700 1 heartbeat_map is_healthy 'FileStore::op_tp thread 0x7fcd48716700' had timed out after 60
2016-07-08 20:04:13.254474 7fcd52c50700 1 heartbeat_map is_healthy 'FileStore::op_tp thread 0x7fcd47f15700' had timed out after 60
2016-07-08 20:04:18.254546 7fcd52c50700 1 heartbeat_map is_healthy 'OSD::osd_op_tp thread 0x7fcd2927e700' had timed out after 15
2016-07-08 20:04:18.254560 7fcd52c50700 1 heartbeat_map is_healthy 'OSD::osd_op_tp thread 0x7fcd2927e700' had suicide timed out after 150
2016-07-08 20:04:18.401770 7fcd52c50700 -1 common/HeartbeatMap.cc: In function 'bool ceph::HeartbeatMap::_check(const ceph::heartbeat_handle_d*, const char*, time_t)' thread 7fcd52c50700 time 2016-07-08 20:04:18.254578
common/HeartbeatMap.cc: 86: FAILED assert(0 == "hit suicide timeout")
ceph version 10.2.1 (3a66dd4f30852819c1bdaa8ec23c795d4ad77269)
1: (ceph::__ceph_assert_fail(char const*, char const*, int, char const*)+0x80) [0x55815ee03d60]
2: (ceph::HeartbeatMap::_check(ceph::heartbeat_handle_d const*, char const*, long)+0x259) [0x55815ed3c199]
3: (ceph::HeartbeatMap::is_healthy()+0xe6) [0x55815ed3cac6]
4: (ceph::HeartbeatMap::check_touch_file()+0x2c) [0x55815ed3d31c]
5: (CephContextServiceThread::entry()+0x167) [0x55815ee1c5c7]
6: (()+0x76fa) [0x7fcd5775f6fa]
7: (clone()+0x6d) [0x7fcd557dab5d]
NOTE: a copy of the executable, or `objdump -rdS <executable>` is needed to interpret this.
The dump logs are almost same.
==================================================================
2. Server syslog
(from 20:02 hearbeat_check message)
Jul 8 20:02:20 localhost ceph-osd[2705]: 2016-07-08 20:02:20.423548 7fbab0b0b700 -1 osd.14 30969 heartbeat_check: no reply from osd.15 since back 2016-07-08 20:02:00.011707 front 2016-07-08 20:02:00.011707 (cutoff 2016-07-08 20:02:00.423542)
Jul 8 20:02:21 localhost ceph-osd[2705]: 2016-07-08 20:02:21.423660 7fbab0b0b700 -1 osd.14 30969 heartbeat_check: no reply from osd.15 since back 2016-07-08 20:02:00.011707 front 2016-07-08 20:02:00.011707 (cutoff 2016-07-08 20:02:01.423655)
Jul 8 20:02:21 localhost ceph-osd[4471]: 2016-07-08
.
.
Jul 8 20:03:44 localhost kernel: [24000.909905] INFO: task wb_throttle:6695 blocked for more than 120 seconds.
Jul 8 20:03:44 localhost kernel: [24000.965687] Not tainted 4.4.0-28-generic #47-Ubuntu
Jul 8 20:03:44 localhost kernel: [24001.022418] "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
Jul 8 20:03:44 localhost kernel: [24001.080286] wb_throttle D ffff88038c6af818 0 6695 1 0x00000000
Jul 8 20:03:44 localhost kernel: [24001.080292] ffff88038c6af818 0000000000000000 ffff88081d598000 ffff8807aa4dc4c0
Jul 8 20:03:44 localhost kernel: [24001.080294] ffff88038c6b0000 ffff8806e2f7eea0 ffff8806e2f7eeb8 ffff88038c6af858
Jul 8 20:03:44 localhost kernel: [24001.080296] ffff8806e2f7ee98 ffff88038c6af830 ffffffff818235b5 ffff8806e2f7ee38
Jul 8 20:03:44 localhost kernel: [24001.080298] Call Trace:
Jul 8 20:03:44 localhost kernel: [24001.080298] Call Trace:
Jul 8 20:03:44 localhost kernel: [24001.080310] [<ffffffff818235b5>] schedule+0x35/0x80
Jul 8 20:03:44 localhost kernel: [24001.080348] [<ffffffffc034c9c9>] btrfs_tree_lock+0x79/0x210 [btrfs]
Jul 8 20:03:44 localhost kernel: [24001.080353] [<ffffffff810c3ca0>] ? wake_atomic_t_function+0x60/0x60
Jul 8 20:03:44 localhost kernel: [24001.080364] [<ffffffffc02e9c43>] push_leaf_left+0xd3/0x1b0 [btrfs]
Jul 8 20:03:44 localhost kernel: [24001.080373] [<ffffffffc02ea33b>] split_leaf+0x4fb/0x710 [btrfs]
Jul 8 20:03:44 localhost kernel: [24001.080383] [<ffffffffc02eaef0>] btrfs_search_slot+0x9a0/0x9f0 [btrfs]
Jul 8 20:03:44 localhost kernel: [24001.080393] [<ffffffffc02ec851>] btrfs_insert_empty_items+0x71/0xc0 [btrfs]
Jul 8 20:03:44 localhost kernel: [24001.080406] [<ffffffffc038be9f>] copy_items+0x139/0x851 [btrfs]
Jul 8 20:03:44 localhost kernel: [24001.080416] [<ffffffffc02edbe9>] ? btrfs_search_forward+0x2d9/0x350 [btrfs]
Jul 8 20:03:44 localhost kernel: [24001.080428] [<ffffffffc038d4cb>] btrfs_log_inode+0x69e/0xe45 [btrfs]
Jul 8 20:03:44 localhost kernel: [24001.080441] [<ffffffffc0351d37>] btrfs_log_inode_parent+0x2a7/0xee0 [btrfs]
Jul 8 20:03:44 localhost kernel: [24001.080454] [<ffffffffc0334247>] ? extent_writepages+0x67/0x90 [btrfs]
Jul 8 20:03:44 localhost kernel: [24001.080467] [<ffffffffc03156b0>] ? btrfs_real_readdir+0x5e0/0x5e0 [btrfs]
Jul 8 20:03:44 localhost kernel: [24001.080479] [<ffffffffc030ff11>] ? wait_current_trans.isra.21+0x31/0x120 [btrfs]
Jul 8 20:03:44 localhost kernel: [24001.080490] [<ffffffffc030f987>] ? join_transaction.isra.15+0x27/0x400 [btrfs]
Jul 8 20:03:44 localhost kernel: [24001.080503] [<ffffffffc0353952>] btrfs_log_dentry_safe+0x62/0x80 [btrfs]
Jul 8 20:03:44 localhost kernel: [24001.080515] [<ffffffffc032774f>] btrfs_sync_file+0x28f/0x3b0 [btrfs]
Jul 8 20:03:44 localhost kernel: [24001.080520] [<ffffffff8124108b>] vfs_fsync_range+0x4b/0xb0
Jul 8 20:03:44 localhost kernel: [24001.080522] [<ffffffff8124114d>] do_fsync+0x3d/0x70
Jul 8 20:03:44 localhost kernel: [24001.080524] [<ffffffff81241403>] SyS_fdatasync+0x13/0x20
Jul 8 20:03:44 localhost kernel: [24001.080527] [<ffffffff818276b2>] entry_SYSCALL_64_fastpath+0x16/0x71
.
.
Jul 8 20:04:18 localhost ceph-osd[6462]: common/HeartbeatMap.cc: In function 'bool ceph::HeartbeatMap::_check(const ceph::heartbeat_handle_d*, const char*, time_t)' thread 7fcd52c50700 time 2016-07-08 20:04:18.254578
Jul 8 20:04:18 localhost ceph-osd[6462]: common/HeartbeatMap.cc: 86: FAILED assert(0 == "hit suicide timeout")
Jul 8 20:04:18 localhost ceph-osd[6462]: ceph version 10.2.1 (3a66dd4f30852819c1bdaa8ec23c795d4ad77269)
Jul 8 20:04:18 localhost ceph-osd[6462]: 1: (ceph::__ceph_assert_fail(char const*, char const*, int, char const*)+0x80) [0x55815ee03d60]
Jul 8 20:04:18 localhost ceph-osd[6462]: 2: (ceph::HeartbeatMap::_check(ceph::heartbeat_handle_d const*, char const*, long)+0x259) [0x55815ed3c199]
Jul 8 20:04:18 localhost ceph-osd[6462]: 3: (ceph::HeartbeatMap::is_healthy()+0xe6) [0x55815ed3cac6]
Jul 8 20:04:18 localhost ceph-osd[6462]: 4: (ceph::HeartbeatMap::check_touch_file()+0x2c) [0x55815ed3d31c]
Jul 8 20:04:18 localhost ceph-osd[6462]: 5: (CephContextServiceThread::entry()+0x167) [0x55815ee1c5c7]
Jul 8 20:04:18 localhost ceph-osd[6462]: 6: (()+0x76fa) [0x7fcd5775f6fa]
Jul 8 20:04:18 localhost ceph-osd[6462]: 7: (clone()+0x6d) [0x7fcd557dab5d]
Jul 8 20:04:18 localhost ceph-osd[6462]: NOTE: a copy of the executable, or `objdump -rdS <executable>` is needed to interpret this.
Jul 8 20:04:18 localhost ceph-osd[6462]: 2016-07-08 20:04:18.401770 7fcd52c50700 -1 common/HeartbeatMap.cc: In function 'bool ceph::HeartbeatMap::_check(const ceph::heartbeat_handle_d*, const char*, time_t)' thread 7fcd52c50700 time 2016-07-08 20:04:18.254578
==================================================================
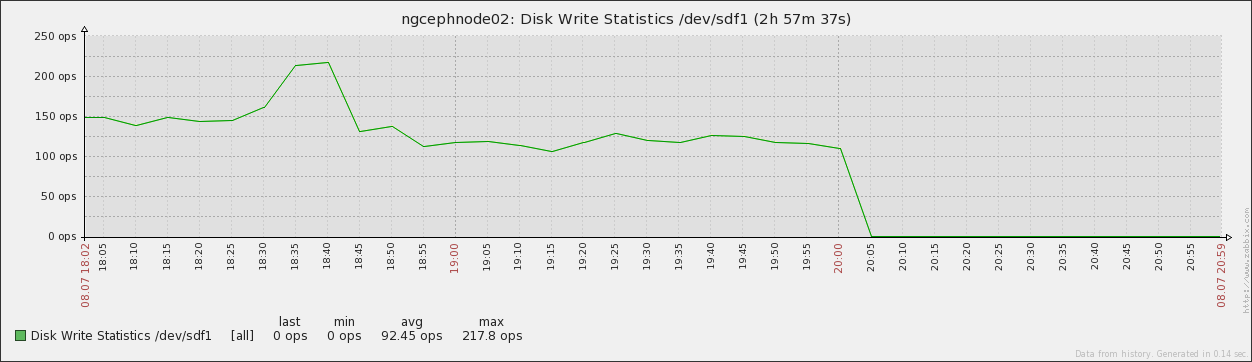
3. There are no maximum stress of disk I/O
===================================================================
3. There are also cpu and memory stress
4. The average wirte I/O is about 250MB/s
- We use ceph as root disk of OpenStack VMs
- We are running test tools for 50 VMs which write tests with vdbench
====================================================================
Could you anybody explain this issue and the exact reason of OSD suicide?
Thanks.
John Haan.
_______________________________________________ ceph-users mailing list ceph-users@xxxxxxxxxxxxxx http://lists.ceph.com/listinfo.cgi/ceph-users-ceph.com
