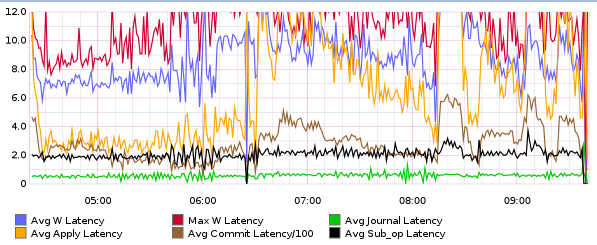
Hi All, Could someone please sanity check this for me please. I trying to get my head round what counter reflect what and how they correlate to end user performance. In the attached graph I am graphing averages of the counters across all OSD's on one host Blue = osd.w_op_latency Red = Max of above Green = Journal Latency Orange = Apply Latency Brown = Commit latency / 100 (so it can fit on graph) Black = Sub op Latency Am I correct in saying that 1. The actual time for a write IO = op_w_latency (excluding RTT from client to OSD) 2. op_w_latency = Apply latency + concurrent apply latency on replica SSD 3. Journal Latency = SSD write time + Ceph overhead (SSD await is slightly lower) 4. Sub OP Latency = Journal Latency on both nodes + Ceph Overheads (Dispatch/messenger) + Network Latency 5. Commit Latency = How long it takes to flush buffers to disk - Doesn't directly affect latency unless there is a backlog 6. Apply Latency = Journal Latency + Queue if disks are too far behind journal Questions 1. Is there any way to see the network latency between OSD's in a counter? 2. Why in my graph does the op_w_latency not go up by the same amount between 07:00 and 08:00, despite the apply latency tripling. I guessing the disks are saturating and the filestore throttle is kicking in, but confused why the op_w_latency counter does not increase. Generally if they are any other counters that are interesting to look at, please let me know. Thanks, Nick
Attachment:
Untitled.jpg
Description: JPEG image
_______________________________________________ ceph-users mailing list ceph-users@xxxxxxxxxxxxxx http://lists.ceph.com/listinfo.cgi/ceph-users-ceph.com

{kind=link}