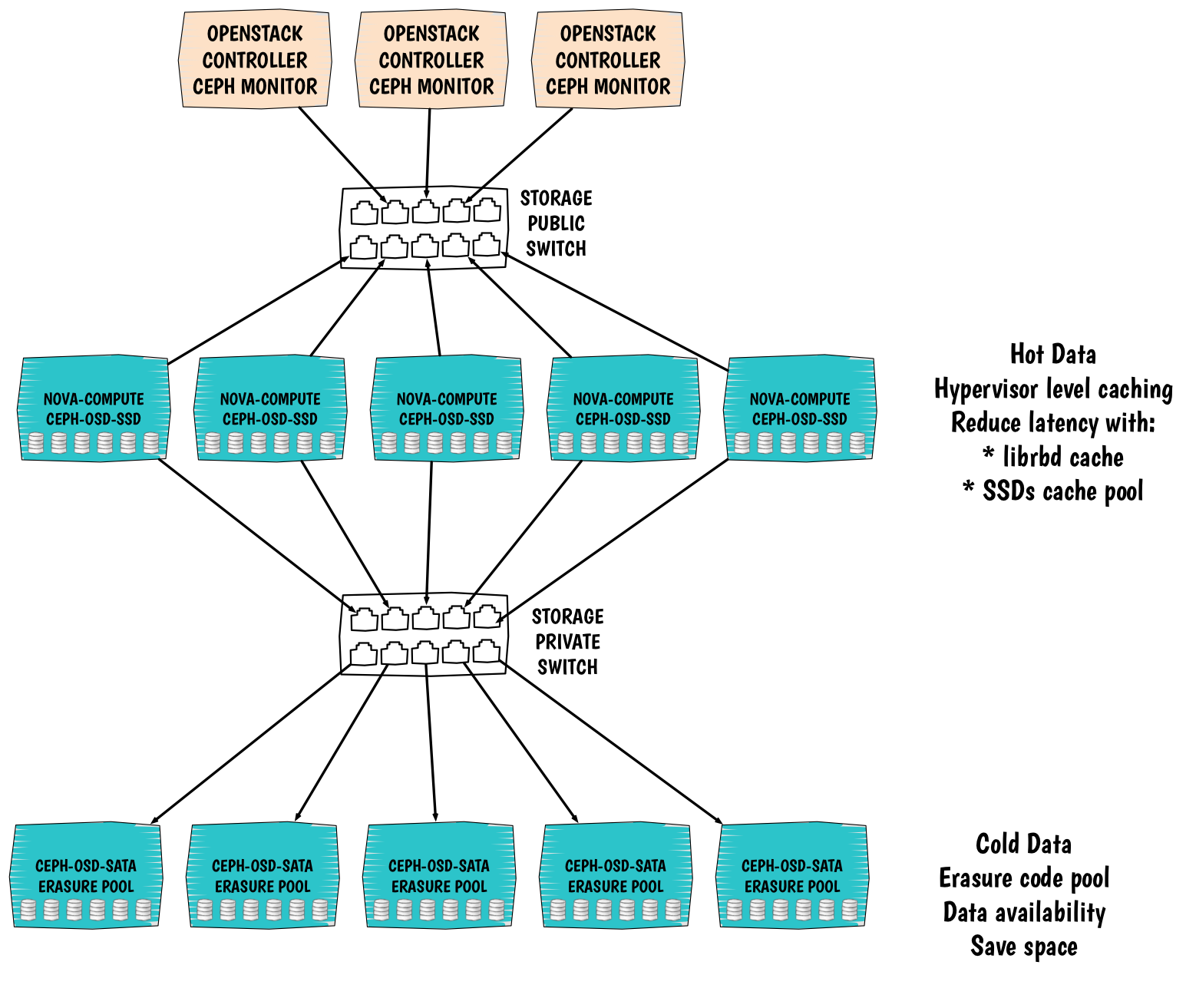
-----BEGIN PGP SIGNED MESSAGE----- Hash: SHA256 >From what I understand, the scrub only scrubs PG copies in the same pool, so there would not be much benefit to scrubbing a single replication pool until Ceph starts storing the hash of the metadata and data. Then you would only know that your data is bad/good and can't repair it automatically. >From what I understand of the documentation, if you are running VMs, you don't want the cache pool in read-only; it is really intended for data that is read many times, written hardly ever. If however, you find that it works well for your use case, you may have a lot of manual work to do when a cache OSD dies. Although the cache tier should just go to the base tier in this situation, when you bring a new drive into the cache, you may have to tell ceph that all the PGs that were on that disk are now lost. Hopefully, Ceph will be smart and just repopulate them as needed without any other issues, but it is a big unknown for me. The best thing to do is try it out on a test cluster first and try different failures to make sure it works as you expect it to. -----BEGIN PGP SIGNATURE----- Version: Mailvelope v1.3.3 Comment: https://www.mailvelope.com wsFcBAEBCAAQBQJWnRpkCRDmVDuy+mK58QAA6TkP+gKNr8bkXAg3bfOJkHrJ PIJ98bJzym5oA8Ny6lzJzgcJYA8WZfcd34ZwEN/7pPheSdcDlm4U2cs5am2h 78xR0RGVHKi4hxN/z17OzBzb9FjqJW2ed5Xq36fw9I363HEfoSkPwDbzibqT 77EGBxgZGFuUqL4lcxAd5JkQp+C4M62FEezdBmJ+nVa+OF0kCosAJelvuDpe D5GO/8MRdmKBHbEoeSUCXX2Tk3S7XaVX/MjjiZ+2UgqLvZk5fIiLHyUKT6jC Otcx+X7fyHHMRdg8bFxHL6Vu5iRRpT5y8M49VW7BhE5+ACo+AXuvn0yJH1rw 84jT7LzQEZeeZtwxOg1prR0qK/E73u3UeF3sONt1dmUxMp5ZEw+UW4yXRhZO gHcfTUbVNPF3b2ZTsj4Bs1GMRktgwQvTaVMDAuBlzVLnMttVtonjOhwynk/Z +GSfoiIdKZeq+8XGfcOS7cFIYiW01cx9KiScDZyBwV88Wwyslop+MU5wyBgM V80TYDmmtouMvN0KuEqR+HHErVzifjOX7D5QXNdjlAtMhzmPB45D/zcrrEXk JYpiDTWCCoADtIai+uyqZaXoE311nne4lv89gzaqZQTjXep5bLvkPHQwkUPn GF6aOgGIZjZf199EkImqsQYmoIyTCXKlwwxcDyFqGcqk5/m43IapcpZ/SnN/ lXPM =iUPg -----END PGP SIGNATURE----- ---------------- Robert LeBlanc PGP Fingerprint 79A2 9CA4 6CC4 45DD A904 C70E E654 3BB2 FA62 B9F1 On Sun, Jan 17, 2016 at 2:08 PM, Tyler Bishop <tyler.bishop@xxxxxxxxxxxxxxxxx> wrote: > Adding to this thought, even if you are using a single replica for the cache > pool, will ceph scrub the cached block against the base tier? What if you > have corruption in your cache? > > ________________________________ > From: "Tyler Bishop" <tyler.bishop@xxxxxxxxxxxxxxxxx> > To: ceph-users@xxxxxxxxxxxxxx > Cc: "Sebastien han" <Sebastien.han@xxxxxxxxxxxx> > Sent: Sunday, January 17, 2016 3:47:13 PM > Subject: Ceph Cache pool redundancy requirements. > > Based off Sebastiens design I had some thoughts: > http://www.sebastien-han.fr/images/ceph-cache-pool-compute-design.png > > Hypervisors are for obvious reason more susceptible to crashes and reboots > for security updates. Since ceph is utilizing a standard pool for the cache > tier it creates a requirement for placement group stability. IE: We cannot > use a pool with only 1 PG replica required. The ideal configuration would be > to utilize a single replica ssd cache pool as READ ONLY, and all writes will > be sent to the base tier ssd journals, this way your getting quick acks and > fast reads without any lost flash capacity for redundancy. > > Has anyone tested a failure with a read only cache pool that utilizes a > single replica? Does ceph simply fetch the data and place it to another pg? > The cache pool should be able to sustain drive failures with 1 replica > because its not needed for consistency. > > Interesting topic here.. curious if anyone has tried this. > > Our current architecture utilizes 48 hosts with 2x 1T SSD each as a 2 > replica ssd pool. We have 4 host with 52x 6T disk for a capacity pool. We > would like to run the base tier on the spindles with the SSD as a 100% > utilized cache tier for busy pools. > > > _______________________________________________ > ceph-users mailing list > ceph-users@xxxxxxxxxxxxxx > http://lists.ceph.com/listinfo.cgi/ceph-users-ceph.com > _______________________________________________ ceph-users mailing list ceph-users@xxxxxxxxxxxxxx http://lists.ceph.com/listinfo.cgi/ceph-users-ceph.com
{kind=link}
 |